Content
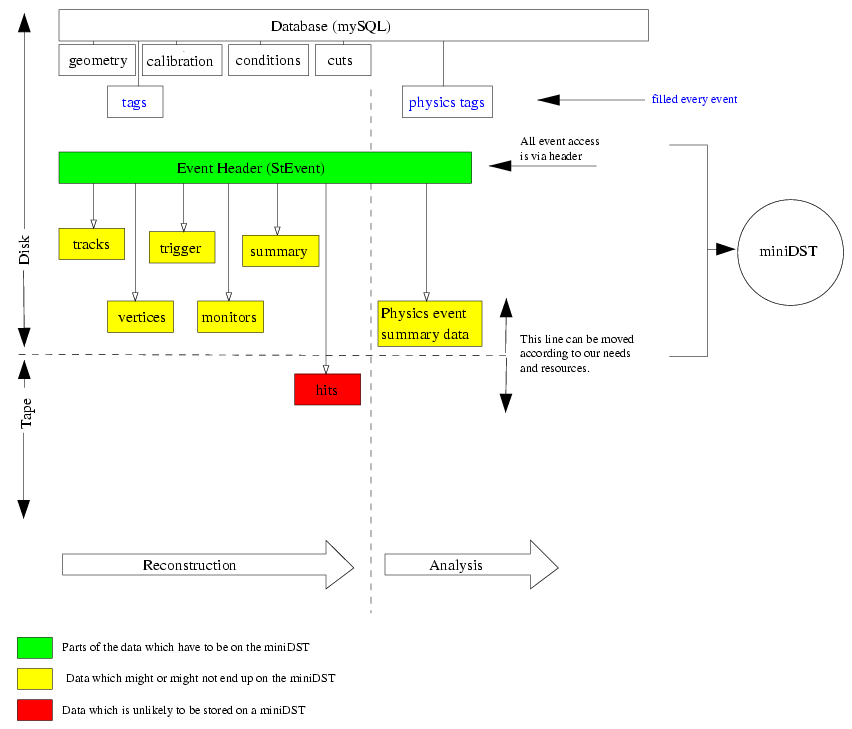
The plot above exist in a similar, somewhat outdated form since quite a while and was often shown by Torre. The pdf version is available here. The plot above is based on this viewgraph and is not really meant to replace it but to help in this discussion.
In the center of the plot you see the STAR datamodel. Its implementation is called StEvent. As a model is is independent of (i) the location of the data (tape/disk) and (ii) the degree to which it is filled. (This is nothing else than saying that the two dashed lines in the plot can be freely moved up and down/left or right). Access to the event data is through the event header, i.e. the StEvent class itself. From the header one can navigate to the various parts. The names (tracks, vertices, trigger ) are only to make the point. The actual model is more detailed. What is new in this plot is the box called Physics event summary data. More below.
The datamodel is not setup (filled) completely during reconstruction. Parts of it can and will be created (filled) at a later stage during the analysis. As with all other objects it is completely under our control what is filled or not. The model is still valid if parts are missing. What resides on disk or gets migrated to tape (HPSS) is also entirely under our control. It will be determined mainly by our needs and our resources.
On the top of the plot you see the DB icons. The DB consist of several parts, some are filled per event, some per run and some are valid even longer. A good example for data which is stored in the DB every event are the tags. Tags are created by Online and Offline reconstruction and some at a later stage during the analysis. The DB is available at any time, ie during reconstruction and analysis. A priori it is independent of StEvent which makes maintenance and administration easier. StEvent does not use the DB directly. It is only in the code of the applications (reco/analysis/testing/QA ...) where both get together. The often raised question if one can use the DB when using StEvent is the wrong questions. One doesn't need one to use the other. StEvent represents is a datamodel not an applications in the old sense (although StEvent provides some functionality because of its OO character).
Physics event summary data (PSD)
Before we come to the miniDST a few words on the Physics event summary data (PSD). This is not an invention by STAR but used in many HEP OO models. Much of the confusion in the discussion was caused because I called it PWG miniDST. Mea culpa, not a good name. So let me explain in detail what this is. The reconstruction program (bfc) creates tracks, vertices, cluster, hits etc. which are stored on the DST. It thus provides us with the basic quantities to do physics. Physics analysis is usually performed later. The learning curves and the frequency of code modifications are different for reconstruction and analysis hence it makes perfectly sense to defer much of the 'physics' analysis to later. There is nevertheless the need for STAR-wide access to those physics quantities. Examples are:
It is obvious that these are topics which must be handled by PWGs. The reconstruction team (Spiros et al.) is more than busy with other things. The PWGs are responsible for
Clear that every pwg will pick those PSDs which are specific to their interest.
The question arises on the difference between PSD and tags. First of all: tags are quantities used for queries. They allow to select events but for a detailed analysis one needs certainly more than this. Take as an example the centrality business Nu Xu is working on. At the end he will come up with numbers on the centrality. One can express this in nch, Et, (b), percent of total x-section, participants, whatever. One might want them all. All are quantities which have an error assigned to them, cuts and assumptions were made. At the end one wants to store certainly everything there is in a dedicated PSD class. One or two variables describing the centrality will go to the TagDB - but that's it. No need to pump all the details in the tags. This is only an example and there's is certainly a grey area between PSD and tags.
The miniDST contains a fraction of the StEvent tree. Which fraction is under our control - almost. Some objects have to be present to preserve the integrity of the model. Currently I see only one object namely the event header itself. Then there are objects which one could write to the miniDST but it would make really little sense to do so. Hits are a good example, although one might consider keeping hits of certain tracks. The obvious candidates to go on miniDSTs are tracks, vertices and the PSD objects. There is no rule which says that there can only be one miniDST. It makes perfectly sense to keep different variants of miniDSTs. Some pwgs might want highly compressed miniDSTs (i.e. small) for rare probe searches since they deal with many events. Other groups might want more complete miniDSTs since they need less events in total. But again, this is not a must. Several PWG can go for a common miniDST. STAR can go for a common miniDST. This is our choice. Important is that the model/scheme does not limit us in our choice. The important thing is that there's a common format and scheme. Group A then can read group Bs miniDST. They might not find the objects they look for but they can read the file and use whatever is stored.
I hope this text answers most of the questions. I'm aware of the fact that there are still some open technical issues to discuss but they is better handled by a smaller group of experts. More important is that the basic idea is clear to everybody.
Thomas
Last update: