In the next run (FY01/FY02) STAR will record approximately 50 times the amount of raw data taken in the previous run while the amount of available disk space will increase by a factor of 3 to 5 only. Fifty times more raw data means fifty times as many miniDSTs as last year. This implies that we have to optimize the disk usage to a very high degree. We decided a while ago to keep only 2 weeks worth of DST on disk. There is no way that all the DSTs from the FY01/FY02 run will be disk resident. There is no way that all the current pwg-specific miniDSTs will be disk resident. It may be possible, however, to have a fully disk resident STAR-wide miniDST on disk (if it's well designed).
Currently we have several pwg specific miniDST formats whith lots of duplicated information. Since a while now we are discussing a STAR-wide miniDST scheme. We have to address this issue pretty soon in order to have enough time to implement and test the code and the required infrastructure. Below is a proposal on how the new miniDST scheme could look like.
Changes to the STAR data model (StEvent)
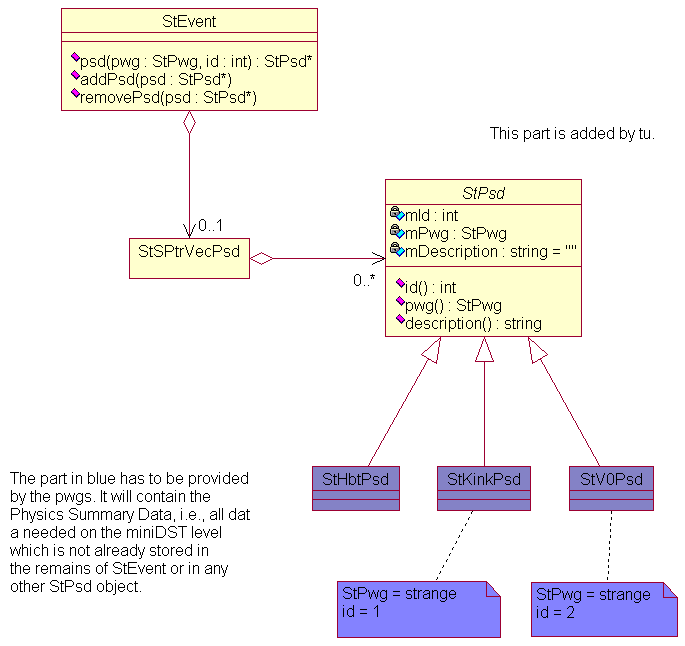
StEvent has currently no standardized 'hooks' to plug in information which is assembled after the reconstruction. What is needed is a way to store data which is created by the code used to create the miniDSTs, i.e., extra information specific to the various physics topics. These kind of data is usually called Physics Summary Data (PSD). The simplest and most straightforward way to accomplish this is by adding a container which holds the various PSD objects. The design and content of the underlying classes is entirely up to the Physics Working Groups. All what is required is that they all inherit from a common base class StPsd. In order to pull out the correct PSD we also need a way of identifying the various objects. This can be done by either using integer IDs, enumerations, text strings, or a combination of them. In what follows I assume that the PSDs are identified by a pwg identifier (enumeration) and an integer number in case a pwg requires several different PSDs.
The UML below means essentially that there will be a new vector (type StSPtrVecPsd) added to StEvent which will store the pointers to the various PSD objects and that StEvent will get few new methods to retrieve the requested PSDs according to their identifiers. Note that this design assumes that there will be more than one PSD per pwg. The ID helps to distinguish them.
That's all what is needed. The current miniDSTs can be used as templates.
Changes to the reconstruction chain (bfc)
None.
A new chain: the miniDST chain (sfc)
Yes, we need a new chain. This 'official' chain will contain the code from each pwg. With other words this chain will contain only StPwgMakers (besides the IOMaker of course). The task of each maker is to
At the end of the chain we have (i) a reduced StEvent and (ii) new PSD objects containing all new information. This needs of course some coordination. No pwg should remove objects from StEvent others need and no PSD object should contain what others already stored. To avoid this we could create a StCommonPsd. Good candidates to go there are for example the reference multiplicity.
Doesn't the miniDST become bigger than the DST?
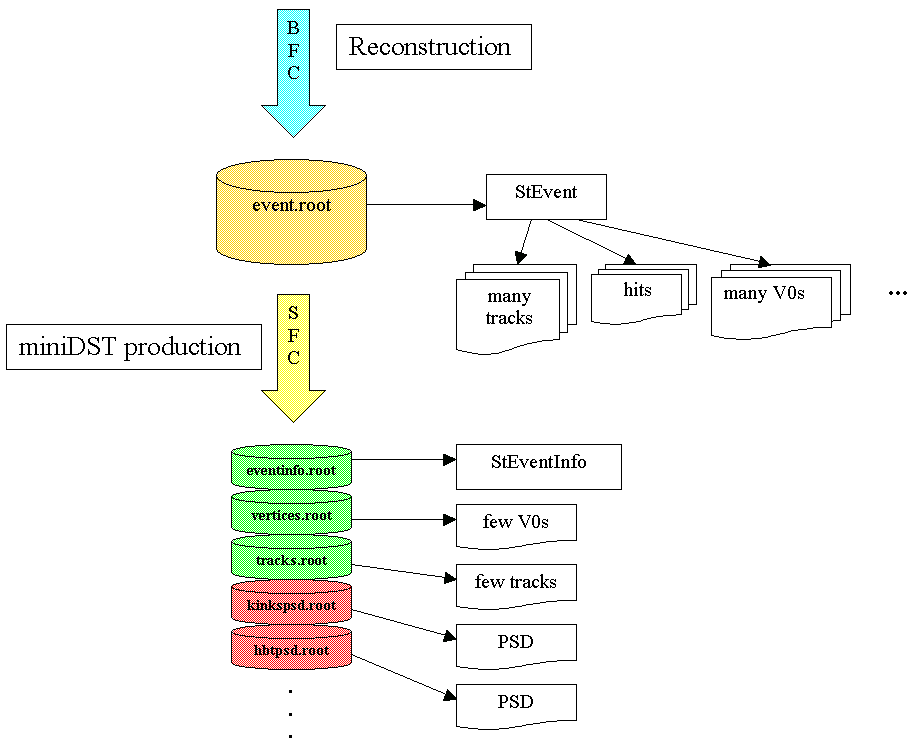
No. Lots of information in StEvent is redundant. Many V0s can be eliminated, the same way the are eliminated now before they are stored in the strangeness miniDST. Also I know of no pwg which deals with tracks with less than 10 hits. All tracks with 5-9 hits can go. Also all hits will be removed (including RICH). There is lots of info stored in the DST which we have to keep but which is not needed on the miniDST.
The most important things comes now: the remaining StEvent including the PSDs gets written out into several branches. All branches are already defined except the PSD. As soon as the PSDs are defined we have to figure out if ever PSD gets its own PSD or if they get clustered. This certainly has to be tested and we probably will have to change the clustering after we gained some experience.
Why all that?
Mostly for efficiency reason. To analyze the data users now have to access only their PSD (or several) and the StEvent branches they need. But not everything! This speeds up the I/O. Since we cannot hold all miniDSTs on disk retrieval is also quicker. If someone needs only branch X, Y and one PSD we only have to pull this part out of HPSS.
And, most important, we can run the miniDST production on CRS or CAS as we please. It will be a STAR wide procedure and handled like reconstruction.
Again, the pwgs have to provide:
In summary:
Pros
Cons
Last update: