Report
of the 2002 RHIC Computing Requirements Task Force
N.
George, B. Gibbard, K. Hagel, B. Holzman, J. Lauret, D. Morrison, J.
Porter,
T.
Throwe, J. Velkovska, F. Videbaek
-
(June
2002)
-
- History and
Motivation:
-
- As was done prior to
the FY 2001 running of the RHIC experimental program1
a task force was assembled to assess the computing needs of the RHIC
experiments for the FY 2003 running period (Run-3). Using the
performance of the RHIC machine, the experiments and the RCF during
the FY 2001/02 running period (Run-2), and the expected performance
of the RHIC machine and the experiments in the upcoming running
period, the representatives of the experiments produced at least two
sets of estimates for their needs. One estimate was based solely on
expected data rates to each of the experiments with the machine at
expected performance, and the extrapolation of the current
reconstruction and analysis programs of the experiments. A second
estimate was also made adjusting the requirements according to the
constraints imposed by the FY 2002 budget and the expected FY 2003
budget.
-
- Traditionally,
hardware purchases for the RCF have been made late in the fiscal
year in order to maximize the resources obtained with the funds. In
keeping with this tradition, the FY 2002 purchases are being made in
the summer of 2002. But, due to the long shutdown of the RHIC
machine that arose from the combining of the FY2001 and FY2002 runs
and the need to accommodate upgrades to the experiments, which
pushed the start of the next RHIC run into early FY 2003, it became
clear that we could not put off the FY 2003 purchases to the summer
of 2003. In order to obtain sufficient resources to approach the
reconstruction and analysis of the data produced in Run-3, it was
determined that the FY 2003 purchases would have to be made
immediately at the beginning of FY 2003.
-
- The estimates on needs
and the cost to obtain the resources necessary to accommodate these
needs then reflect the time scale of the purchases. The main impact
on the estimates is that the same hardware parameters are used in
each of the two purchases rather than being able to rely on Moore’s
Law to improve the resources obtained in the FY 2003 purchase.
-
- Current Estimates
of Requirements:
-
- The estimates made by
the experiments are summarized in the following tables. The first
table (Table I) contains the estimates of CPU, disk and bandwidth
needed to reconstruct and analyze the expected data set size from a
25-week RHIC Au-AU run assuming a RHIC duty factor of 0.6.
-
-
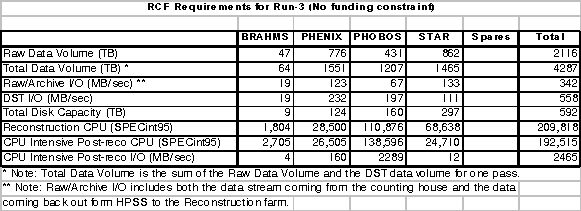
Table
I
- The second table (Table II)
contains the estimates constrained to the present RCF budget.
-
-
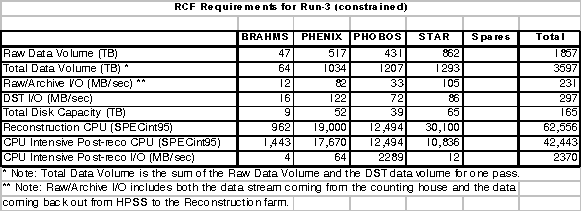
Table
II
- The experiments went
from the “unconstrained” scenario to the “constrained”
scenario through a variety of methods ranging from reducing the
event rate, to increasing the time period over which the data will
be reconstructed and analyzed, to changing the fundamental model of
how data is stored moving from more expensive centralized RAID
storage to less expensive distributed disk storage. None of the
changes made by the experiments to reduce their needs are desirable
since they all will increase the work needed to extract the physics
from the experiments and reduce the physics impact of the data.
-
The third table (Table III)
shows the percentage of the unconstrained estimates achieved under
the constraints of the RCF budget.
-

Table
III
- The current RCF
capacities are listed by experiments in Table IV.
-

Table
IV
- The above
unconstrained and constrained scenarios were produced by the
experiments over the course of the meetings of the task force.
BRAHMS estimated their needs for a 25 week AU + Au run
and based on their experience with the reconstruction and analysis
of the Run-2 data, they determined that their greatest need was in
the area of centralized disk space, since their present model is
based on keeping a significant amount of data on disk. Therefore
BRAHMS allocates the majority of its funds for disk
purchases with a modest addition to their compute farms.
-
- Using a data rate of
300 Hz based on the performance of their DAQ system during Run-2,
PHENIX estimates that they would accumulate
approximately 15 times the data taken in Run-2. Since the budgets
will not allow the purchase of the resources necessary to
reconstruct and analyze this volume of data, PHENIX
has looked to improving their rare event trigger to reduce the
overall event rate, and to reducing the number of reconstruction
passes through the data to 1.2. A significant amount of manpower
will need to be committed to the improvement of calibration
procedures, online monitoring and the content of the micro- and
nano-DSTs in order to achieve the above reductions. Overall, PHENIX
feels that the funding for FY 2002 and FY 2003 falls short of their
needs by a factor of 2 to 3.
-
- PHOBOS
is implementing two significant upgrades to their experiment to
improve the data taking rate and trigger efficiency and therefore
expects to take two orders of magnitude more data during Run-3 than
they took in Run-2. Based on the current usage of their RCF
resources, PHOBOS estimates that the funding for FY
2002 and FY 2003 will leave them with an order of magnitude fewer
resources than are required for the amount of data they expect to
accumulate. PHOBOS plans to record as much of the data from Run-3
as is possible and looks to improvements in their analysis code and
stretching out the analysis time to resolve the gap in resources.
Since it is not clear what magnitude of an improvement can be made
in the code and since increasing the analysis time-scale will result
in a decline in physics productivity, if PHOBOS and
the RHIC machine perform as expected during the upcoming run, PHOBOS
feels that there will be a clear need for additional computing
resources in the latter half of FY 2003.
-
- STAR is
implementing new detectors and improvements to their DAQ system (a
five-fold increase in their data rate and buffering of data in the
counting house for later transfer during RHIC downtimes) prior to
the Run-3 running period. As a result of these improvements, STAR
expects the volume of their DST and micro-DST data to exceed the
available resources from the FY 2002 and FY 2003 funding by a factor
of 10 and that, even with an expected 40% reduction in
reconstruction time, the processing time of the data would span the
order of 3 years. To try to compensate for the resource mismatch
STAR sees, they plan to mode to a distributed disk
model to reduce the gap in storage and stretch out their data
production period to 37 weeks. This approach is deemed risky in
that it relies on a non-existent infrastructure to use the
distributed disk. STAR also feels that to reach their physics goals
in a timely fashion will require additional funding in the latter
half of FY 2003.
-
Constrained Scenario:
- Table V through Table VIII
shows the breakdown, by experiment, of the cost and capacity by
fiscal year with the budget constrained to the current FY 2002
funding and the expected funding for FY 2003.
-
-
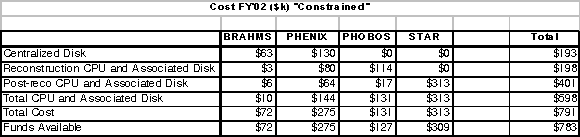
Table
V
-

Table VI
-
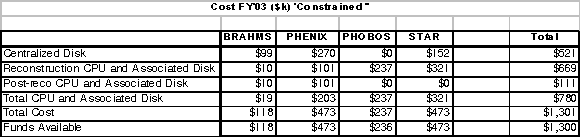
Table VII
-

Table
VIII
- The total capacity of
the RCF in FY 2003, given the present funding, is indicated in Table IX.
-
-

Table
IX
HPSS Tape I/O
- Funding has been set
aside to upgrade the mass storage system to support the increased
data rates anticipated by the experiments for Run-3. The major item
in this upgrade, in terms of cost and criticality, is the
replacement of the currently used StorageTek 9940 tape drives by
next generation 9940b tape drives. In addition, two additional HPSS
server nodes will be purchased. The new tape drives will use the
same media but will have approximately three times the I/O rate and
three times the density of data on tape. The new capacity numbers
are expected to be 30 MBytes/sec uncompressed streaming per tape
drive and 200 GBytes per tape cartridge in native (uncompressed)
mode. In typical RCF operations the actual I/O rate of tape drives
is generally observed to be about 70% of the theoretical
performance. As a result of data compression, the volume of data
stored on a tape cartridge typically exceeds the native capacity by
a modest amount. There are 34 tape drives that will be upgraded to
this new technology. This new type of tape drive is currently in
β-test at multiple sites and is expected to be generally
available in August. It should be pointed out that, while such a
problem appears unlikely, if these new drives were not available for
Run-3, it would present a major problem for RHIC data handling.
Meeting the tape I/O requirements would then require that RCF make a
more costly purchase of older lower speed tape drives and additional
tape storage silos to house the data. It would also require that
the experiments purchase three times as many tapes.
-
- Summary and
Conclusions:
-
- All of the
experiments, through upgrades and/or trigger rate improvements and a
desire to make up for the lower than expected data rates during
Run-2, have increased the aggregate data rate expected during Run-3
to 230 MBytes/sec, well beyond the rate of 90 MBytes /sec predicted
for this point in the life of the experiments prior to the turn on
of RHIC. The direct result of this high data rate is a gap between
the resources available in the RCF and the resources needed by the
experiments to reach their physics goals. The resource gap varies
among the experiments from perhaps a factor of two to an order of
magnitude, and the experiments have addressed this shortfall in a
variety of ways from reducing the trigger rate, to extending the
time period for analysis, to changing their analysis model. Each of
these changes from an “unconstrained” data collection
and analysis scenario has a resulting impact on the experiments
ability to reach their physics goals, and the actual impact will
depend on the performance of the RHIC machine, the experiments and
the RCF during the run.
-
- With the possible
exception of BRAHMS, each of the RHIC experiments feel
that they will be underpowered in CPU and lacking in disk space to
varying degrees for Run-3 given the present funding of the RCF.
But, since the estimates of needs by the experiments were based on
the upper limits of the performance of both the RHIC machine and the
experimental systems, it can not be estimated at this time what the
actual performance of either of the systems will be (especially
since the species mix to be delivered during the run has not yet
been determined) so it is too early to know exactly how underpowered
the RCF is likely to be. Given the present funding, the RCF will be
sized for a certain amount of data, and, as Run-3 proceeds, the
experiments and RCF will be better able to assess the rate of data
collection versus the available resources in the RCF. As the data
collected compared to the expected data volume approaches the ratios
expressed in Table III a decision would be made as to whether or not
to request additional funds to make up for the shortfalls the
experiments see in the resources at the RCF.
-
- The efforts going into
reducing event sizes, improving triggers to lower event rates, and
improving code efficiencies by the experiments in order to produce
physics output in the present funding scenario cannot continue. If
the RHIC machine continues to improve at the rate predicted, then
the experiments will not be able to keep up with the increased data
flow without increases in hardware funding since the experiments
feel that they are reaching the limits of the above improvements.
In addition, since all of the experiments have manpower limitations,
the effort going into these improvements is taking away from the
effort going into producing the physics output of the experiments.
-
- There is also concern
that the current level of funding will result in a RCF that is
stretched to its limit both in manpower and resources. We feel that
the facility should function at the levels indicated by the
“constrained” scenarios, but with little, if any, room
to spare, and an unexpected failure could have a major impact on the
productivity of the facility.
-
�
Appendix:
Contributions from the Experiments
- BRAHMS
once again undertook a review of the computing requirements based on
data collected in the 2001 run. In the 2001 run we stored data at
an average rate of 5.5 Mb/s over stores where data were collected.
In the next run, for an assumed efficiency factor of .6 for the
accelerator and .95 for the experiment, we would obtain an average
data rate of 3.1 Mb/s which would enable us to collect about 48 Tb
over the course of a 25 week Au + Au run.
- The size of the DST
data sets generated in BRAHMS analysis of the data
from the past year was approximately 34% of the raw data volume,
which would lead to about 16 Tb.
- In our current scheme
of data selection, the size of the DSTs
is 10% of the DST data. To be able to work on 3 different analyses
concurrently would require a volume of 5 Tb.
-
- In part because the
available I/O-bandwidth from the HPSS does not match well with the
CPU requirements the present analysis model is based on keeping a
significant amount of the data (in particular DST) on disk for
repeated calibration and analysis (multiple times per dataset).
-
The total disk capacity is
calculated by assuming 3.5% of raw data resident on disk, 15% of DST
data resident on disk and the full volume of uDST and nDST (10% of
uDST) data to be resident on disk. This is 48*.035 + 16*.15 + 5 +
.5 = 1.7 + 2.4 + 5 + .5 = 9.6 Tb. We currently have 5.5 Tb of
available disk space.
-
- We have also evaluated
the CPU estimates for the upcoming run based on what is necessary to
reconstruct and analyze the current data from the 2001 run. We
learned that we require about 5 SPECint 95-sec/event in our
reconstruction pass. We have also learned that we need an average
of 2 reconstruction passes in order to properly calibrate and then
reconstruct the data. When taking into account the efficiency of
farm, we require about 1800 SPECint 95 in order to completely
reconstruct the data in 16 weeks.
-
- If we examine the
table, we note that we have more than 1800 SPECint 95 processing
power in the CRS farm already. That would indicate that the CPU
computing resources are adequate in the current scheme.
- We have also estimated
that the CAS farm needs 1.5 times the processing power of the CRS
farm. That would indicate 2700 SPECint 95 as opposed to the 1738
SPECint 95 currently in the farm.
-
- We note that we have a
deficit of about 5 Tb in required disk space. It is clear,
therefore, that disk space is where we should concentrate the
available funds. We choose, however, to devote some funds to
“small” upgrades to the CPU power in order to ride the
technology curve as a small investment can make a large difference
in analysis ease given the more powerful processors that can be
purchased later in time.
-
- This preceding
philosophy guides the following division of purchases from FY02 and
FY03 funds. For BRAHMS, there will be ~$72k and ~$118k available
for FY02 and FY03, respectively. We plan to purchase 1 CRS machine
and 2 CAS machines in FY02 and 3 CRS machines and 3 CAS machines in
FY03. This will bring the total CRS processor power to 3059 SPECint
95 and the total CAS processor power to 2467 SPECint 95.
-
- The rest of the funds
would be spent on disk upgrades. The plan is to purchase 3.2 Tb of
disk space with FY02 funds and 5.1 Tb with FY03 funds. This will
bring the total amount of disk space available to BRAHMS to 13.8 Tb,
a comfortable margin that will allow an efficient analysis of the
data.
-
�
PHENIX computing
requirements for FY02 and FY03
- The estimate presented
here is based upon a 25 week Au-Au run at full RHIC luminosity with
60% RHIC duty factor and 95% PHENIX duty factor. Other running
scenarios were also considered and the overall uncertainty in the
presented requirements numbers was estimated to be within a factor
of 2. During RUN2, the PHENIX DAQ system was demonstrated to be
capable of recording data at 500Hz, however a more realistic
sustained rate used for this estimate is 300Hz. Recording data with
this rate will result in approximately 776 TB of raw data. This is a
factor of ~15 more data than PHENIX has accumulated during RUN2.
Clearly the combined FY02 and FY03 computing funds do not allow such
volumes of data to be handled in the same way as we have done in the
past. Since PHENIX is a rare event experiment, we can also look into
collecting more triggered data and reducing the overall event rate
without affecting significantly the PHENIX physics program. A
constrained estimate presented here uses 200 Hz event rate as an
input parameter. The resulting raw data volume in the constrained
case is ~517 TB – a factor of 11 more data than the RUN2
value. Being able to collect data at such rates is contingent upon
the integration into the system of the STK 9940b
high-density/high-speed tape drives (3 in FY02 and 3 in FY03).
Without these tape drives we will be severely limited not only by
the speed at which data can be recorded and read out, but also by
the prohibitive price tag on the tape storage that PHENIX has to buy
from its operation funds.
- To be able to handle
hundreds of terabytes of data, we need to reduce the number of full
reconstruction passes through the data. Our current experience shows
that at least 1.5 passes through the data are necessary to assure
high quality data analyses. However, to fit into the available
computing funds, we need to restrict ourselves to 1.2 reconstruction
passes. This reduction will require significant improvement of
calibration procedures and online data monitoring.
-
The expected large volume
of data also increases significantly the need for disk space.
Currently, PHENIX is able to store 100% of the microDSTs and
nanoDSTs on disk. For RUN3 only 30% of the microDSTs can be kept on
disk. This constraint limits the speed with which the data can be
analyzed. Possible solution is revision of DST, microDST and nanoDST
optimizing their content and minimizing the size. Few analyses need
the full information stored in the DSTs – the limited disk
space resources will inevitably affect these.
- In conclusion, the RCF
funding for FY02 and FY03 may be a factor of 2 or 3 short of the
PHENIX needs, depending on the amount of data that we will record
during RUN3. With the current constrained scenario we will be able
to meet our needs after committing significant manpower for
improvement of calibration procedures, online monitoring and
micro/nano/DST content. �
- Phobos Computing
Requirements Proposal: 8th May 02:
Two
significant upgrades affecting the data taking rate will be
implemented for the PHOBOS detector for the upcoming run in FY03.
The first involves a significant upgrade to the PHOBOS DAQ allowing
data to be taken at a rate of 500 Hz (50 MB/sec). The second is the
addition of a spectrometer trigger enabling PHOBOS to trigger on
single particles in pp and dA collisions. These upgrades are in part
to compensate for the reduction in RHIC’s overall running
time, and an emphasis on low multiplicity species scans for
systematic studies.
- Combining the funding
from FY02 and FY03, PHOBOS has calculated that this funding level
will undershoot the projected requirements by about an order of
magnitude. This is a reasonable estimate, given that our current
farm is ~100% loaded and that we are expected to take two orders of
magnitude more data in the upcoming run. The dominant factor comes
from the increase in CPU resources needed. To resolve the funding
gap, PHOBOS has proposed two alternative extreme constrained
scenarios. The first is that we increase the analysis time by an
order of magnitude (1/2 year -> ~4 years) assuming no additional
optimization can be achieved. The second is to try to optimize the
code to effectively run an order of magnitude faster. In reality
neither of these scenarios is guaranteed to work, and some
combination of the two will result in a smaller but significant fall
short of the needed computing resources. Given last years
experience, where RHIC’s net luminosity was over-predicted by
about a factor of 4, PHOBOS feels that, although there is clearly a
need for additional computing resources above the current FY02+FY03
levels, it is premature at this time to request additional funds
until we have a better sense of the expected data volume and
processing time. This time should be in about May of FY03. We feel,
that with the currently funded resources, we can take all of the raw
data RHIC can deliver. This is contingent upon the functionality of
the new tape drives which offer 3 times the current rate and
capacity. The full analysis of the taken data will then have to be
delayed until sufficient resources become available. Large
increases in analysis time-scales provide problems such as a decline
in physics productivity, which prevents achievement of stated goals.
In addition this can affect funding and student availabilities. An
additional concern remains regarding RCF’s ability to maintain
an efficient operation if operating continuously at its very
limits.
�
STAR
Computing requirements proposal FY02/FY03
- During the Year2 RHIC
run, the STAR experiment accumulated over 10 M AuAu
events and 25 M pp events. Although this data sample is a
factor of 5 larger than in Year1, it was still much lower than we
had predicted due to the reduced RHIC physics running time, the
rather poor RHIC duty factor, and our data rate limit set by writing
data to RCF. As a result, several measurements in STAR's
physics program such as Open Charm and event characterization
(elliptic flow and HBT) using rare probes are limited by the
statistics in the Year2 data samples. To minimize our dependence on
RHIC's performance in the upcoming run, STAR's DAQ-100
project was initiated with goals of a 60 MB/sec data rate
(sustained), a 5-fold increase in our event rate, and a 40%
reduction in our reconstruction time (ideal). The DAQ-100 project is
now fully operational and expected to be used during the Year3 run.
- The calculations
presented here include the effects of the DAQ-100 project as well as
effects from new detectors coming on line during the next year. We
stress that the increased data volumes projected here from the
DAQ-100 project are an attempt to recover the full physics program
not yet realized due to RHIC past performance and to protect our
program from future limitations of RHIC operations. We have made
three scenario estimates taking into account FY02 and FY03 funds
merging; only one is proposed as an achievable goal.
- The DAQ-100
scenario extends our data deployment model of the current Year2
datasets through the analysis FY03 data. This scenario shows 100% of
μDSTs and 25% of our DSTs on centralized disks and represents a
known (safe) model for delivering data to physics analysis codes.
The result shows a 280TB disk space deficit. This deficit could be
reduced to about 160TB by removing the disk residency of the DST
data; however, even with this reduction, we are 2 million dollars
short of our budget requirements and a factor of 10 off our storage
needs.
- The second scenario
(Constrained 1) reduced the number of passes, increased the
compression level raw/DST, and assumed 50% (5%) of our μDST (DST)
on central storage. It did not allow us to recover from the
downfalls unless the processing time was spanned over 3 years (at
the expense of our physics goals), mainly running on our existing
resources. This is obviously not viable since our user farm is
currently congested and cries for more CPU power in addition to the
consequences from such a long turn around for data analyses.
- Finally, Constrained
2 scenario, or the "challenge" scenario relies on a
more risky distributed disk model for covering our disk space
requirements without leaving us without processing power. The
approach balances our CPU and disk space needs within a 37-week
production period (an assumed 80% RCF farm uptime was also folded
in). This approach entirely relies on a non-existing STAR
infrastructure components and a robust and heavily accessed HPSS.
However, it seems to be our only alternative given the current
budget restrictions.
- A factor of 4
reduction in the RHIC efficiency from the assumptions in these
calculations (as did occur last year) would not translate to a
factor of 4 reduction in our numbers. DAQ-100 allows us to buffer
more events for later transfer during RHIC downtimes; the net effect
being at worst a factor of 2 reduction in the data volumes and CPU
resource requirements presented here. We therefore feel that, to
reach our physics objectives in a reasonable time frame, there is a
need for extended funding. However, we acknowledge that these
numbers do depend on factors beyond our control such as RHIC and RCF
performance. Finally, we would like to mention, once again, that
HPSS reliability will become an even more critical requirement than
ever before, our distributed disk model's success depending on it.
-
1
M. Baker, et al., Report of the 2001RHIC Computing Requirements Task
Force, April 12, 2001