
A behavioral simulation tool has been developed which allows for the investigation of various architectural configurations of the STAR trigger subsystem. A major component of the trigger is the token management system which allows for throttling of the trigger event rate at the various trigger sub-levels. Here we describe a recent set of simulations in which the effect of this throttling methodology on detector deadtime and event latencies has been explored.
Token management is handled utilizing three separate token queues, which include the Master Token Queue (MTQ), the Trigger control unit Token Queue (TTQ) and the Level2 Token Queue (L2TQ). The MTQ can contain up to 4095 tokens, while the TTQ and L2TQ contain some smaller subset of these tokens which represents the system resources available at each of the trigger sub-levels 1 and 2. For instance if there are 10 CPU's at L1 with enough memory allocated so that there could be 4 events queued per CPU, then the number of tokens would be 40 for the TTQ. On the other hand, for the L2TQ the number of tokens is: (system resources at L2-system resources at L1), so that for the above L1 configuration it would be necessary to have enough memory allocated for 10 L2 CPU's so that 8 events could be queued per CPU. This leads to 40 tokens in the L2TQ as well. Upon trigger system initialization, tokens from the MTQ are pushed into both the TTQ and L2TQ based on the above mentioned criteria. This is displayed in Fig. 1.
Figure 1. Token queue initialization scenario.
Click on the image for a ps file.....

Figure 2. Token management methodology. Black lines represent event flow and colored lines represent token flow.
Click on the image for a ps file.....
Upon a L0 accept, a token is removed from the TTQ and attached to the event. Thus, the number of tokens in the TTQ is decremented for a L0 trigger. The event with attached token is then pushed to L1. If there are no tokens in the TCU the STAR detector is effectively dead since no events can be triggered.
At L1 a decision of acceptance or rejection is made. In the figure, for simplicity, tokens from rejected events are shown to be stripped from the event and placed back at the bottom of the TTQ. In the simulation, the rejected event token is actually returned to the bottom of the MTQ and a token from the top of the MTQ is pushed into the TTQ. This ensures that tokens are actually used in a global round robin fashion. On the other hand, if the event is accepted then a token from the top of the L2TQ is pushed into the bottom of the TTQ. Thus upon L1 acceptance a system resource at L1 has been freed while a resource at L2 is now occupied. The accepted event is then pushed into the L2 analysis area.
In the case of an L1 accept when there are no tokens available in the L2TQ, an overdraw counter is incremented. If the overdraw counter > 0 then a token added to the L2TQ is immediately forwarded to the TTQ and the overdraw counter is decremented by one. This is contuinued until the overdraw counter is set to zero.
If an event is rejected at L2, again the token is stripped from the event and placed at the bottom of the MTQ. For either an abort or accept a token is pushed from the top of the MTQ to the bottom of the L2TQ, since an L2 system resource has been freed. (Again for simplicity Fig. 2 shows functionally the same procedure where the rejected event token is returned directly to the bottom of the L2TQ.) Upon L2 acceptance the event is then pushed to the TRG/DAQ Interface and then to L3. Although L3 analysis and events-to-tape are considered, detailed operations of systems at L3 and above have not been included in the simulation. Tokens from L3 and Tape events are returned to the bottom of the MTQ upon completion.
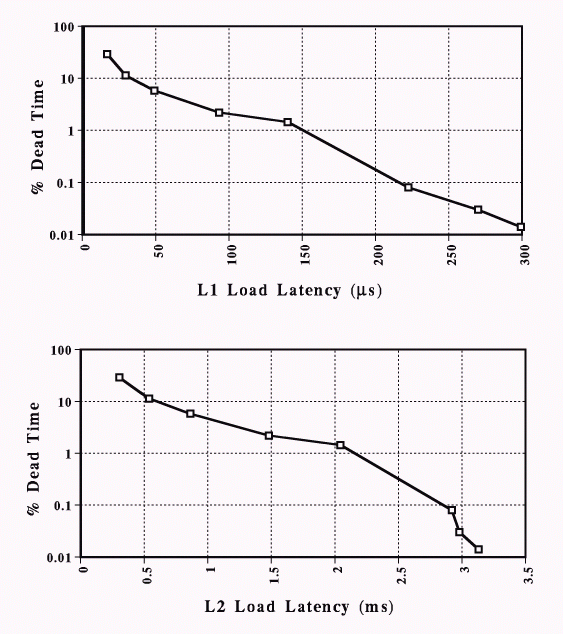
The simulation has been performed such that by varying the depth of the TTQ and L2TQ, event load latencies at sub-levels 1 and 2 can be modified. This in turns leads to variations in detector deadtime due to the lack of tokens in the TTQ. Here simulations have been run with 10, 15, 20, 30, 40, 60, 80 and 100 tokens at each level. Thus when increasing the number of tokens (indicating more system resources available), detector deadtime attributable to an empty TTQ decreases, while conversely the latency of events in trigger will increase. This relationship as determined by the present simulation is shown in Fig. 3. Note that each simulation has been run with a 10us and 100us L1 and L2 load time, respectively and that event analysis takes 100us at L1 and 1ms at L2. Both L1 and L2 use 10 CPU's for analysis, while the event rate input to L1 is 100kHz with a 90% rejection factor so that the input rate to L2 is 10kHz. These repesent the maximum throughput rate for the trigger.

Figure 3. Average load latencies with respect to % deadtime for 100kHz event rate at L1 and 10kHz event rate at L2.
Click on the image for a ps file.....
Click here for image with logy axis.....
Click here for image with logy axis in ps.
Distributions of L1 and L2 load latencies for several of the token configurations (Tokens = 10, 30 and 60) have been generated. A sample distribution of L1 load latencies is displayed in Fig. 4. These represent only 10% of the full simulation values or 10000 events, although the averages agree reasonably well with the full simulation results (100,000 events).

Figure 4. Load latencies for L1 CPU's for various token queue depths.
Click on the image for a ps file.....
Finally, Fig. 5 displays similar results for L2 load latencies for the same token configurations. Again it is apparent that the peak in the distribution is moving towards larger values with increasing token depth. The results show that for Tokens=60, the maximum latency at L2 is ~7ms as expected.

Figure 5. L2 load latencies for various token depths.
Click on the image for a ps file.....
Further tests are planned in which the impact on the trigger system of event bursts at L0 will be investigated. The affect of priority queues on TPC event latency in the Trigger will also be explored.
V. Lindenstruth , UC-Berkeley SSL
{kind=link}