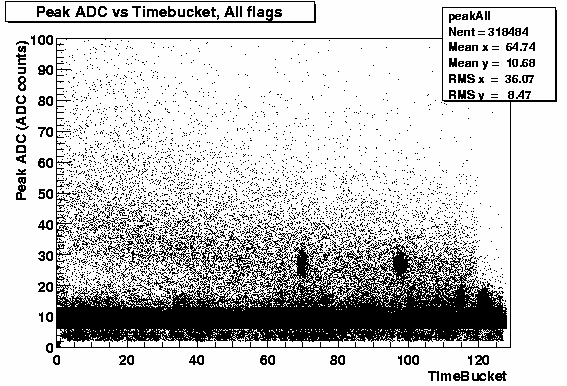
I've looked into optimizing the ASIC parameter settings for the Year 1 ladder. First I looked at the found clusters using Run 1183020, 3484 events, half field, 130 GeV beam. The ASIC parameters where set at thresh_lo=101, n_seq_lo=2, thresh_hi=105 n_seq_hi=0. ( See Zero suppresion pages for details and an explaination of these cuts) Remember we use a fixed offset of 100 ADC counts when we do our zero suppresion so in effect we are cutting on 1 and 5 ADC counts.
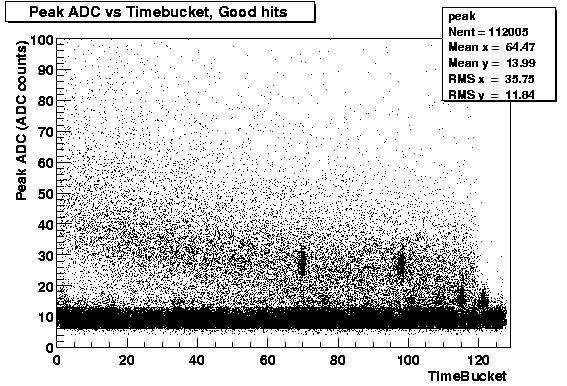
Figures 1 and 2 show the peak ADC distributions as a function of Timebucket for (left) all hits found by the clusters finder and (right) all hits deemed "good" by the cluster fitter. ( See Hit flagging for more details.)
| |
|
You can also see from both plots a clear band of "true" signal approximately following the expected quadratic fall off with drift distance.
Even at long distances it is cleanly separated from the low ADC noise clusters. You can also see that the clusters flagged as good seem to be concentrated in the "quadratic" band.
I then looked at the noise studies we've made and noted that the mean RMS of the noise is 2 ADC counts. This should therefore be set as our thresh_lo for accepting a pixel into a sequence.
we want to keep the ASIC cuts loose as next year this will be done online and there is no way to retrieve any data we cut out here, so we want to be conservative and keep as much of the signal as possible.
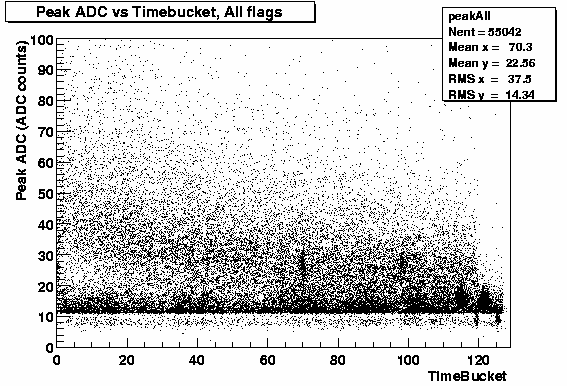
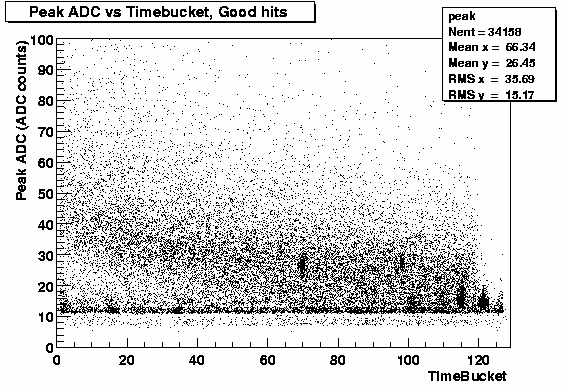
Based on these results I reran with the ASIC parameters now set to thresh_lo=102, n_seq_lo=2, thresh_hi=110 n_seq_hi=0.
 |
 |
| ASIC cuts | No. of Hits | No. of Good hits | Good/Total | No. of Good hits 12 .lt. peak .lt. 100, timebucket .lt.120 |
| 101 2 105 0 | 218484 | 112005 | 0.35 | 28996 |
| 102 2 110 0 | 55,042 | 34,158 | 0.62 | 27076 |
You can see, table above, that this has dramatically reduced the number of hits found. I have run over the same number of events in each case. The ratio of good/all has got much better and when I select, from both sets, those hits that I think should be an even cleaner sample I get close to the same number of clusters. From this I conclude that I am only cutting out "bad" hits. Of course it will take further studies with track-hit matching to really prove that this is the case.
Some things I don't understand are
a) why there are any hits with a peak < 10. I thought the ASIC cut should remove these..
What the blobs are in the time direction. Is this a sign of some common mode noise? (I hope not).