
|
|
Policies and dispatchers |
The policy decides how to process a request and divide it into jobs. The dispatcher takes those jobs and submits them to a batch system, such as LSF or condor. The STAR scheduler comes with different policies and dispatchers that can be used to control how and where jobs are submitted. To specify a policy use the "-policy policyName" argument of the scheduler. If the site you submit from is the same as the site with the queue(s) you are submitting to the scheduler will simply submit locally. If you are on a different site the scheduler will use its grid dispatcher to submit to this remote site. This assumes you have initialized your grid certificate else the submission will fail.
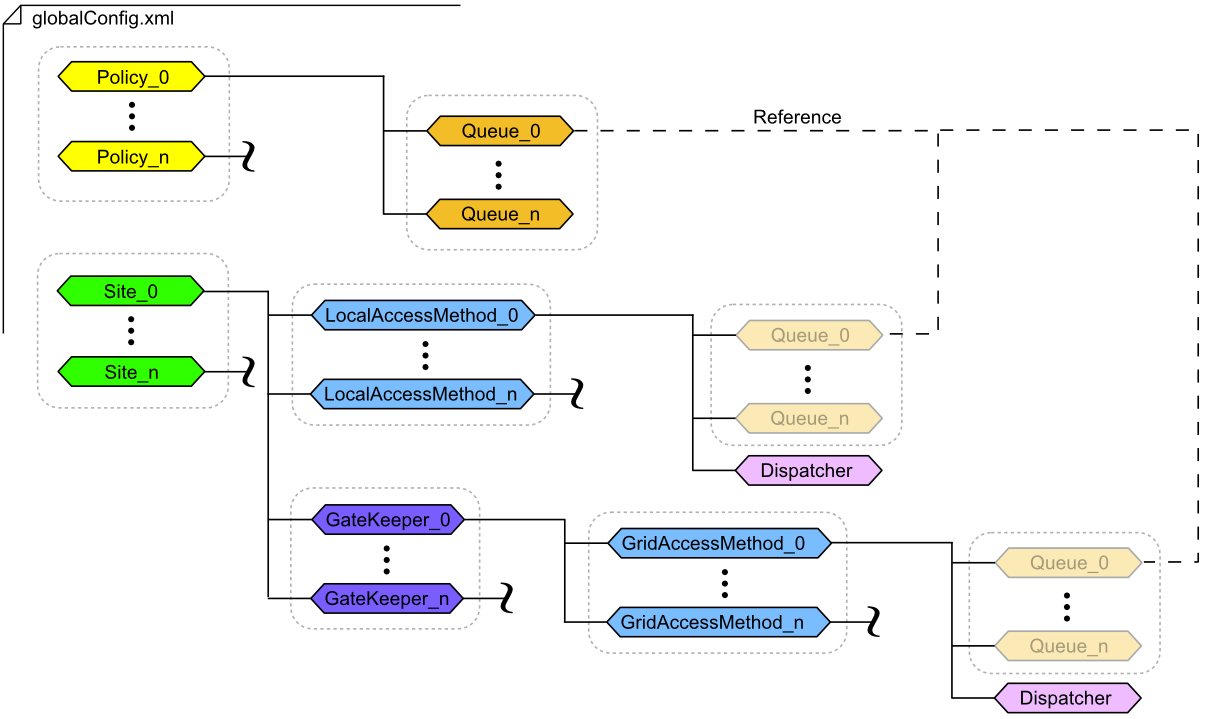
The file globalConfig.xml holds the policies and dispatchers configuration. It is in the same folder as star-submit. Below is a simplified representation of the structure of the file.
SUMS will read in its own configuration file and print it out in a human readable format. The options (arguments) for visualizing basic configuration settings are:
| Example | Description |
| star-submit -print | Printout all the 'star-submit -print [filter]' options |
| star-submit -print polConfig | Print out the policy configuration tree for all sites. |
| star-submit -print siteConfig | Print out the site config tree for all sites |
| star-submit -print defPolConfig | Print out the default policy configuration tre for this site. |
| star-submit -print localSiteConfig | Print out the local site configuration tree for this site. |
| Name | Location | Description |
| bnl_lsf_cas | BNL (deprecated) | Prepares all jobs and assigns them to the rcas cluster. |
| pdsf_sge | PDFS (default at pdsf) | Prepares all jobs and assigns them to SGE at PDSF |
| bnl_condor_cas_quick | BNL (default at bnl) | Prepares all jobs and assigns them to the condor batch system on the RCAS cluster (short, medium, and long queues ), faster then the bnl_condor_cas policy. |
| bnl_condor_cas | BNL (active) | Prepares all jobs and assigns them to the condor batch system on the RCAS cluster (short, medium, and long queues ) |
| bnl_condor_crs | BNL (active) | Prepares all jobs and assigns them to the condor batch system on the RCRS cluster. (special account permeations may be needed) |
| bnl_condor_cas_crs | BNL (active) | Prepares all jobs and assigns them to the condor batch system. The condor batch system decides how to split jobs between the RCAS and RCRS clusters. |
| ResonanceGroupPolicy | BNL (active) | Prepares all jobs and assigns them to the rcas cluster. The long jobs will be using the star_cas_cd queue at BNL |
| sp_sge | Sao Paulo (active) | Prepares all jobs and assigns them to the SGE batch system at Departamento de Física Nuclear Universidade de Sao Paulo |
| star_all | Distributed Across All Sites (Experimental, should no be used ) | Prepares all jobs and distributes them in a fixed ratio between BNL, WSU and Sao Paulo. A grid cert is required to use this policy |
| bnl_lsf_prod | BNL(active) | Submits all jobs to the production queue on the LSF batch system at BNL. Only the production coordinator has access to this queue. |
| bnl_condor_rcf | BNL(active) | This is an opportunistic policy, it prepares
all jobs and assigns them to the condor batch system. This is a cross experiment
queue. It gives STAR users the ability to run jobs on all RCF nodes (including
ATLAS) even if they are own by an experiment other then STAR. If your job
lands on a STAR own node it has a 3 hour guarantied run time. Should it
land on a node not owned by STAR it will run so long as no local experiments
job wants the node. If a local experiments job wants the node your job will
be evicted, this can be 1 minute, 1 hour, ect … there are no guaranties.
This is a truly opportunistic policy, the shorter the jobs, greater your
chances of having the unit of work done.
Note: If you are accessing files please use xrootd or rootd as the files you want may not be on the node your job is sent to. |
| wsu_sge | Wayne State University (default at WSU) | Prepares all jobs and assigns them to the SGE batch system at Wayne State University. |
| MLQueuePolicy | BNL (Experimental, should no be used ) | This is a policy based on the AssignmentByQueueMonitorPolicy class which looks at the loads of queues and submits to the best one. It uses the crs_queue and NFSQueueObj queues. The most optimal calculation for determining queue load is still under development. |
| MonalisaBNLPolicy | BNL (Experimental, should no be used ) | Prepares all jobs and assigns some of them to the rcas and some to the rcrs cluster. The policy will contact the Monalisa monitoring service to determine whether the rcrs cluster is being fully used or not. Therefore, the number of jobs sent to the rcrs cluster will depend on the load on the rcrs cluster. |
| BNLPolicy | BNL (Experimental, should no be used ) | Prepares all jobs and assigns them roughly half to the rcas cluster and the other half to the rcrs cluster. |
| MIT_XGrid | MIT (ONLY mit, can not be called by name) | Prepares all jobs and assigns them to the Apple Mac Xgrid cluster at MIT. |
| cz_pbs | Golias CZ | |
| zen_pbs | ANY (Experimental, should no be used ) | For submitting to the Chicago globus Virtual Workspace. Note that the gatekeeper name is always in fux on this policy. |
| lowMen | BNL (active) | This policy submits exclusively to the queue star_cas_mem. This policy is for jobs using less then 90min of run time and 200MB of ram. Users should be aware that if jobs exceed this requirement and do not "fit in the queue" the job will be bounced and because star_cas_mem is the only queue in this policy, the jobs will not be routed to a bigger queue. An error message will be displayed letting you know the job could not be placed, however no "file lists" or .csh files will be generated. |
| Name | Available at | Dispatcher | Description |
| NSFlocalQueueObj | BNL | RCASDispatcher | star_cas_dd on RCAS |
| NFSQueueObj | BNL | RCASDispatcher | star_cas_short on RCAS |
| NSFlongQueueObj | BNL | RCASDispatcher | star_cas_big on RCAS |
| star_golias_pbs | Golias CZ | PBS_Dispatcher | PBS queue at Golias |
| condor_rcrs_queue | BNL | RCASDispatcher | a condor queue on the RCRS cluster |
| HBT_group_Queue | BNL | condorRCRSDispatcher | star_cas_cd on RCAS |
| PDSF_SGE_Queue | BNL | SGETestDispatcher | not a real queue, just used for testing- (currently disabled) |
| lsf_crs_queue | BNL | RCASDispatcher | star_crs_short on RCRS |
| medium | PDSF no longer available | PDSFDispatcher | medium queue |
| long | PDSF no longer available | PDSFDispatcher | long queue |
| PDSF_SGE_Queue | PDSF | SGETestDispatcher | meta queue used for submitting to the SGE |
* Dispatchers are now selected by the scheduler at runtime as of version 1.8.6.
Levente Hajdu - page was last modified
 |
 |
|