Glue Computing Element Schema
version 1.1
FINAL
Last revision: 12 March 2003
Schema Structure
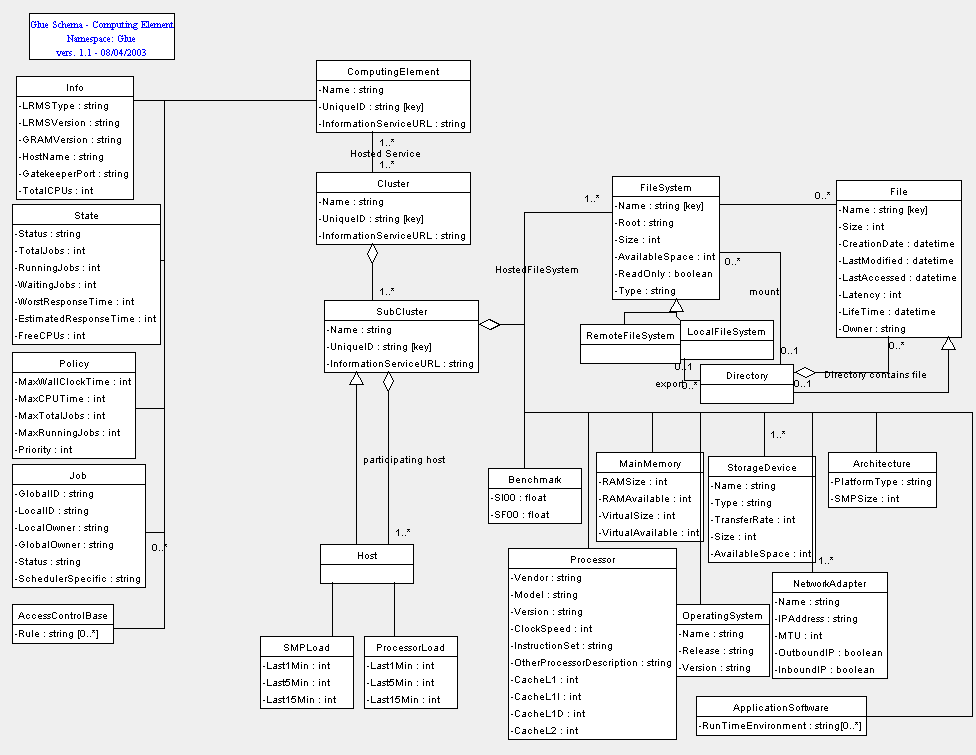
The basic structure of the Glue schema is shown in the figure below. The major components of the initial Glue information model are:
- Computing Element.
- A computing element represents an entry point into a queuing system.
- There is one computing element per queue.
- Queuing systems with multiple queues are represented by creating one computing element per queue.
- The information associated with a computing element is limited only to information relevant to the queue.
- All information about the
physical resources access by a queue are represented by the Cluster
information element.
- Cluster. A cluster is a container that groups
together subclusters, or nodes. Subcluster elements represent “homogeneous”
collections of computational nodes, while a nodes represent unique nodes,
such as head nodes, or individual computing nodes. A cluster may be referenced
by more then one computing element.
- SubCluster. A subcluster represents a “homogeneous”
collection of nodes, where the homogeneity is defined by a collection whose
required node attributes all have the same value. For example, a subcluster
represents a set of nodes with the same CPU, memory, OS, network interfaces,
etc. Strictly speaking, subclusters are not necessary, but they provide
a convenient way of representing useful collections of nodes. A subcluster
captures a node count and the set of attributes for which homogeneous values
are being asserted.
- Host. Represents a physical computing element. This element characterizes the physical configuration of a computing node, including processors, software, storage elements, etc.
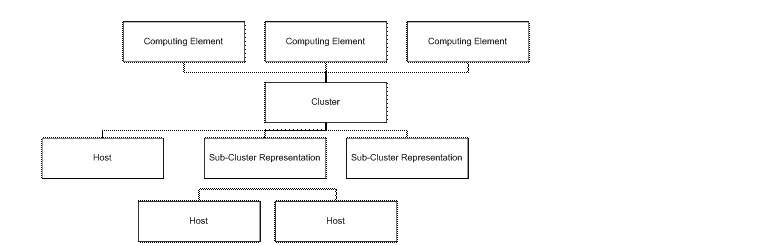
GLUE representations are constructed from the top down. That is, once can deploy a computing element without specifying the cluster, a computing element and cluster without subcluster definitions, and subcluster definitions without providing host definitions.
Every information element in the GLUE schema has a unique name. This enables disambiguation of nodes. This can be important for example in determining that two different computing elements are actually referring to the same physical resources when determining available processing resources.
Note that this document does not currently contain information regarding file systems or any storage element data. These are recognized by the group as extremely important and high priority, and will be addressed shortly.
Representing Information
As illustrated in the figure above, information is organized hierarchically: hosts are composed into sub-clusters (is partition a better name), sub-clusters are grouped into clusters, and then computing elements refer to one or more clusters. Depending on the implementation, different techniques will be used to represent the structure of the information. For example in current MDS technology, the structure can be represented via a DIT in the GRIS that provides access to the information. In an OGSA base implementation, the structure could be directly represented via an XML document.
Information is represented via named attributes. Attributes may be used in more then one location in the information model. For example attributes at the host level to represent details of the host or node, while the same attribute may be used may also be used to represent summary information at the sub-cluster level. Attribute names are not scoped to the use, and therefore should be selected from a namespace that ensures uniqueness.
Attributes are grouped together to form named objects. There are two types of objects in the information model. Structural objects (computing elements, cluster, sub-cluster, nodes nodes and hosts) are containers for other objects. Auxiliary objects carry the attributes that carry the actual information. Each container can have required, advised and optional auxiliary objects associated with it.
Computing Elements
The computing element models a computational service which access point is a queue. Each queue points to one or more clusters. The Computing Element is a container and can contain the following objects:
- Info (required)
- State (optional)
- Policy (optional)
- State (optional)
- Job (optional)
- AccessControlBase (optional)
| ComputingElement |
ID # from table |
|
| UniqueID |
ID.5 |
A unique identifier for the computing element. For example, EDG uses CE-hn:CE-port/jobmanager-CE-lrms-CE-queue |
| InformationServiceURL |
|
URL of the local information service providing for info about this entity |
| Name |
A name for this service |
| Info |
ID # from table |
|
| LRMSType |
ID.3 |
Name of local resource management system |
| LRMSVersion | Version of local resource manager | |
| GRAMVersion |
QP.2 |
The GRAM version |
| HostName |
ID.1 |
Fully qualified host name for host on which the gatekeeper that corresponds to the computing element runs. |
| GatekeeperPort |
ID.2 |
Port number for the gatekeeper. |
| TotalCPUs |
Num.1 |
Number
of CPUs available to the queue. |
| Policy |
ID # from table |
|
| MaxWallClockTime |
QP.3 |
The maximum wall clock time allowed for jobs submitted to the CE in mins (0=not specified) |
| MaxCPUTime |
QP.4 |
The maximum CPU time allowed for jobs submitted to the CE in mins (0=not specified) |
| MaxTotalJobs |
QP.6 |
The maximum allowed number of jobs in the CE (0=not specified) |
| MaxRunningJobs |
QP.7 |
The maximum number of jobs allowed to be running (0=not specified) |
| Priority |
QP.8 |
Info about the Queue Priority |
| State |
ID # from table |
|
| RunningJobs |
QS.1 |
Number of currently running jobs |
| TotalJobs |
Number of jobs in the CE (=RunningJobs+WaitingJobs) |
|
| Status |
QS.2 |
States a queue can be in: 1. Queueing: the queue can accept job submission, but can’t be served by the scheduler 2. Production: the queue can accept job submissions and is served by a scheduler 3. Closed: The queue can’t accept job submission and can’t be served by a scheduler 4. Draining: the queue can’t accept job submission, but can be served by a scheduler |
| WaitingJobs |
QS.3 |
Number of jobs that are in a state different than running |
| WorstResponseTime |
RT.1 |
Worst time between job submission till when job starts its execution in sec |
| EstimatedResponseTime |
RT.2 |
Estimated time between job submission till when job starts its execution in sec |
| FreeCPUs |
Free.1 |
Number of free CPUs available to a scheduler (generally used with Condor) |
| AccessControlPolicyBase |
ID # from table |
|
| Rule |
User.1 |
A
rule that grant/deny access to the Computing Element service, specific
semantic needs to be defined (e.g. list of X509 user certificate subjects,
VO names) |
| Job |
ID # from table |
|
| LocalOwner |
QJ.1 |
Owner local username |
| GlobalOwner |
QJ.2 |
Owner GSI subject name |
| LocalID |
QJ.3 |
Job local id |
| GlobalID |
QJ.4 |
Job global id |
| Status |
QJ.5 |
Job status {SUBMITTED, WAITING, READY, SCHEDULED, RUNNING, ABORTED, DONE, CLEARED, CHECKPOINTED} |
| SchedulerSpecific |
QJ.6 |
Scheduler specific info |
The CE will always point to a cluster, this is a containment relationship. In the absence of other information, it is assumed that the CE has access to all of the resources contained in the cluster. If this is not true, the “Accessible” Attribute in the QueueInfoOpt object will enumerate what subset of the resources are available to the queue. This is needed in part to construct different logical partitionings for the resource.
Clusters
The cluster information element provides a grouping of Hosts and sub-clusters. Only the name of the cluster is required, enumeration of underlying cluster structure is optional.
A cluster may represent a grouping of individually described nodes or hosts, or a set of SubClusters. An individual host may be represented in a cluster to capture a unique computational element, such as a head node, or in the case where subcluster grouping does not make sense, enumerate the actually computing elements. A cluster has the same attributes as an MDSHostNodeGroup. This is only a name – previously ID.G.4, now also ID.6.
| Cluster |
ID # from table |
|
| Name |
ID.6 |
Name of the cluster, taken from I.g.4, MDS-host-node-group-name |
| InformationServiceURL |
|
URL of the local information service providing for info about this entity |
| UniqueID |
ID.9 |
Unique ID for the cluster |
Sub-Clusters
A subcluster is used to represent a collection of computing resources whose configuration is homogeneous enough that it can be represented by a common set of attributes. For example, a SubCluster can represent the part of a cluster that consists of the nodes with the same CPU, OS, memory and disk configuration. The definition of homogeneous is determined by the set of attributes that are enumerated in the subcluster definition. These attributes must be such that the values of the specified attributes are the same for every node included in the subcluster. Note that elements of a subcluster are only homogenious with respect to the specified values, and the detailed description of the nodes (if provided) may differ in values that are not specified at the subcluster level. We further constrain, the decomposition of resources into subclusters must be such that no node is included in more then one subcluster.
Each SubCluster object has a name attribute that provides a unique name to the subcluster. To represent the resources that the subcluster is summarizing, the SubCluster must contain a name (attribute SubClusterName, ID.7) and a count (attribute SubClusterCount, id.8).
| SubCluster | ID # from table |
|
| Name |
ID.7 |
Name of the Subcluster |
| UniqueID | ID.10 | Unique ID for the Subcluster |
| InformationServiceURL |
|
URL of the local information service providing for info about this entity |
In addition, much of the information available from theHost level may be optionally included in a subcluster is the values are the same across all of the nodes in the subcluster. These are labeled in the tables in the subcluster section.
Host
The Host element is used to represent details of a specific computing element. Many of the objects that may be contained at the host level can be included in the subcluster, these are marked.
There are several attributes that will be able to be located at different levels of the hierarchy depending on their homogeneity properties. Two sets of these are the network attributes and the filesystem attributes. For example, if all of the nodes that can be addressed by a single CE share all of their file systems, that information could hang off the CE level. However, if it was uniform only at the sub-cluster level, it would be attached there, and if it were different for every node then it would need to be at the node level.
| Architecture |
ID # from table |
Included in SubCluster? |
|
| PlatformType |
Arch.5 |
informally describes the platform type of the computing element |
Yes |
| SMPSize |
Num.2 |
number of CPUs in an SMP node |
Yes |
| Operating System |
ID # from table |
Included in SubCluster? |
|
| Name |
Os.1 |
informally names the OS using a vendor-specific convention |
Yes |
| Release |
OS.2 |
informally names the OS release using a vendor-specific convention |
Yes |
| Version |
OS.3 |
informally names the OS or kernel version using a vendor-specific convention |
Yes |
| Benchmark |
ID # from table |
Included in SubCluster? |
|
| SI00 |
Benchm.1 |
The SpecInt2000 benchmark of the nodes associated to the subcluster |
Yes |
| SF00 |
Benchm.2 |
The SpecfFloat2000 benchmark of the nodes associated with the subcluster |
Yes |
| ApplicationSoftware |
ID # from table |
Included in SubCluster? |
|
| RunTimeEnvironment |
SW.1 |
List of softwares/packages installed on this subcluster |
Yes |
| ArchitectureDetails |
ID # from table |
Included in SubCluster? |
| Processor |
ID# from table |
Included in SubCluster? |
|
| Vendor |
Arch.1 |
Informally names CPU vendor |
Yes |
| Model |
Arch.2 |
Informally names CPU model |
Yes |
| Version |
Arch.3 |
Informally names CPU version |
Yes |
| ClockSpeed |
Arch.11 |
The MHz associated with the CPUS in the subcluster |
Yes |
| ComputerISA |
Arch.4 |
informally names the Instruction Set Architecture (ISA) of the computing element |
Yes |
| Features |
Arch.6 |
informally names optional CPU features |
Yes |
| CacheL1 |
Arch.7 |
first-level unified cache size (in kb) of a cpu |
Yes |
| CacheL1I |
Arch.8 |
first-level instruction cache size (in kb) of a cpu |
Yes |
| CacheL1D |
Arch.9 |
first-level data cache size (in kb) of a cpu |
Yes |
| Cachel2 |
Arch.10 |
second-level unified cache size (in kb) of a cpu |
Yes |
| MainMemory |
ID # from table |
Included in SubCluster? |
|
| RAMSize |
Mem.1 |
configured physical memory on any one CPU in the subcluster in MB |
Yes |
| RAMAvailable |
Mem.2 |
unallocated RAM size in MB |
Yes |
| VirtualAvailable | available virtual memory | Yes | |
| VirutalSize |
Mem.3 |
configured disk-based virtual memory (VM) in MB in a computing node |
Yes |
The file system class can be specialized in REMOTE (for remote directory locally mounted) or LOCAL (for local directory); each local file system can contains directories. Each directory can be associated to a Storage Space.
| FileSystem | |
| Root | path name or other information defining the root of the file system |
| Name | the name for the file system |
| Type | the file system type (e.g. NFS, AFS) |
| ReadOnly | is the file system readonly? |
| Size |
Total space assigned for this file type (MB) |
| AvailableSpace | Total available space for this file type (MB) |
| File | |
| Name | Name for the file |
| Size | File size in bytes |
| CreationDate | File creation date and time |
| LastModified | Last modified date and time |
| LastAccessed |
Last access date and time |
| Latency | Time taken to access file in seconds |
| Owner | File owner |
| LifeTime | Date and time after which the file can be canceled |
(to add path attribute and cancel owner)
| Directory | |
| Name | Name for the file |
(to be updated to be specialization of a file)
(Storage Device: to be canceled, none is interested in publishing it; maybe also file class)
| RemoteFileSystem |
ID # from table |
Included in SubCluster? |
|
| Name |
Mem.1 |
configured physical memory on any one CPU in the subcluster in MB |
Yes |
| RAMAvailable |
Mem.2 |
unallocated RAM size in MB |
Yes |
| VirtualAvailable | available virtual memory | Yes | |
| VirutalSize |
Mem.3 |
configured disk-based virtual memory (VM) in MB in a computing node |
Yes |
| ProcessorLoad |
ID # from table |
Included in SubCluster? |
|
| Last1min |
Free.2 |
1-minute average processor availability for a single node (the difference between the available CPUs and the average runable task count during that time) X 100 |
No |
| Last5min |
Free.3 |
5-minute average processor availability for a single node (the difference between the available CPUs and the average runable task count during that time) X 100 |
No |
| Last15min |
Free.4 |
15-minute average processor availability for a single node (the difference between the available CPUs and the average runable task count during that time) X 100 |
No |
| SMPLoad |
ID# from table |
Included in SubCluster? |
|
| Load1min |
Free.5 |
1-minute average processor availability for an SMP node (multi CPU), which is the difference between the available CPUs and the average runable task count during that time X 100 |
No |
| Load5min |
Free.6 |
5-minute average processor availability for an SMP node (multi CPU), which is the difference between the available CPUs and the average runable task count during that time X 100 |
No |
| Load15min |
Free.7 |
15-minute average processor availability for an SMP node (multi CPU), which is the difference between the available CPUs and the average runable task count during that time X 100 |
No |
| NetworkAdapter |
ID # from table |
||
| Name |
Net.3 |
names a network interface |
no |
| IPAddress |
Net.4 |
ip address of a network interface |
no |
| OutboundIP |
Net.1 |
Defines if outbound connectivity is allowed from "worker nodes"- can a worked node initiate outbound connectivity |
Yes |
| InboundIP |
Net.2 |
{Defines if inbound connectivity is allowed} |
Yes |
| MTU |
Net.6 |
maximum transmission unit size (in bytes) for a network interface |
no |
UML Computing Element Class Diagram