| Name | Type | Use | Default | Fixed | Annotation |
| simulateSubmission | xs:boolean | optional | | | | documentation | Tells the scheduler whether to dispatch the actual jobs. If true, the file scripts are
created, but they are not actually submitted. This is useful to check whether everything
is functioning correctly. |
|
| name | xs:string | optional | | | | documentation | Gives the job a name by which it can be identified in the underlying batch system. |
|
| mail | xs:boolean | optional | false | | | documentation | Tells the scheduler whether to allow the submission of a job that will returns it's output
by mail. If not this is not set, or is not equal to true, the scheduler will fail if a stdout
wasn't specified. This option is here to prevent a user to accidentally send himself all
the outputs by mail. |
|
| nProcesses | xs:long | optional | | | | documentation | [New field] |
|
| inputOrder | xs:string | optional | | | | documentation | This attributes tells the scheduler that you want your input files ordered according
to the value of some catalog attribute. This is not going to provide the filelists always
in sequence: there can always be gaps. It's only going to reorder the filelists after
they are produced. This options is only possible if all the inputs are catalog queries. |
|
| fileListSyntax | | optional | paths | | | documentation | This attribute tells the scheduler which syntax to use for the file list. There are
only a few possible values imposed by the schema. There are currently: paths,
rootd.
"paths" syntax returns both files on local disk and on distributed disk as a normal
path used by the filesystem. This syntax is useful within scripts. The "paths"
syntax looks like this /path1/file1 /path2/file2 /path3/file3 ...
"rootd" syntax returns files on distributed disk with paths, and files on local disk
with the rootd syntax. It also appends the number of events contained in each
file. This file syntax is designed to work with the MuDST makers, and has two
advantages:
(1) It allows root to access files that are on the local disk of a different node, making
it possible to guarantee the minFilesPerProcess
(2) By giving the number of events in the files, the MuDST maker doesn't have to
pre-scan the files, slightly improving performance.
The "rootd" syntax looks like this /NFSpath1/file1 nEvents1 /NFSpath2/file2 nEvents2
root://machine//path3/file3 nEvents3 root://machine//path4/file4 nEvents4 ... |
|
| minFilesPerProcess | xs:long | optional | | | | documentation | Tells the scheduler the minimum number of files each process should run on. The
scheduler will do its best to keep this requirement, but it's not guaranteed to succeed.
If a correct distribution is not found, the user will be asked to validate it. |
|
| maxFilesPerProcess | xs:long | optional | | | | documentation | Tells the scheduler how many input files to assign to each process at maximum.
This number should represent the number of files that your program, by design, is
not allowed to have (e.g. after 150 files memory use has increased too much due to
a memory leak). The actual number of files dispatched to the process is decided by
the scheduler, which takes into account user requirements (i.e. minFiles, maxFiles
and filesPerHour) and farm resources (i.e. length of the different queues). |
|
| logControl | | optional | standard | | | documentation | logControl will add features on top of STDOUT / STDERR and possibly enable
additional vertically integrated services within the application being run. The service may be
enabled via internal logic to SUMS. Examples:
- standard is the default and implies standard STD channels (no special enabler assumed)
- UCM will enable UCM logging, a Tech-X/STAR project. |
|
| filesPerHour | xs:double | optional | | | | documentation | Tells the scheduler how many input files per hour the job is going to analyze.
This information is used by the scheduler to determine an estimate of the job
execution time. This is necessary to determine the correct usage of resources
(e.g. use the long or short queue). By combining the use of filesPerHour and
minFilesPerProcess, you can basically tell the scheduler what is the minimum time
required by your job, and force the use of long queues. If this attribute is not
provided, the job is assumed to be instantaneous (e.g. the processes will be
dispatched to the short queue no matter how many input files it has). |
|
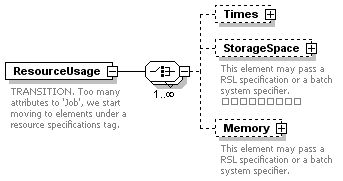
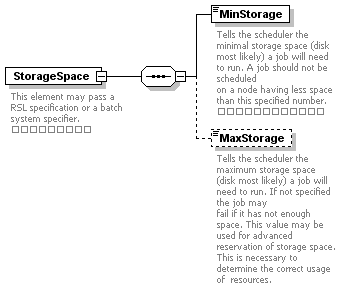
| minStorageSpace | xs:long | optional | | | |
| maxStorageSpace | xs:long | optional | | | |
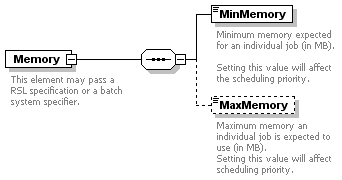
| minMemory | xs:long | optional | | | |
| maxMemory | xs:long | optional | | | |
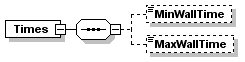
| minWallTime | xs:long | optional | | | |
| maxWallTime | xs:long | optional | | | |