THOSE INSTRUCTIONS WERE NOT YET REVIEWED FOR RUN5
A meeting with the RCF and other experiments is scheduled at a later time to verify its accuracy and relevance.
THOSE
INSTRUCTIONS WERE NOT YET REVIEWED FOR RUN5
A meeting with the RCF
and other experiments is scheduled at a later time to verify its
accuracy and relevance.
Last modified
Basic purpose & Established procedure when a problem occurs :
The purpose of this shift is to answer calls from experiments, check GUI status or Web pages for problems and report to the RCF expert (as explained later in this document) .
A
person calling the counting house from another experiment to report
a problem MUST :
(a)
Have submitted a ticket describing the problem PRIOR to calling
(b)
Ask for the appropriate person covering for the RCF
Monitoring, that is, by Experiment Specific title. In STAR, the
shift covering for the RCF monitoring is the Shift
Crew Person position.
(c)
Identify itself by Name & Experiment (AND leave a Phone number)
After assessing a reported problem, the shift person must decide whether an expert needs to be called during the night. If the problem does not interfere with data-taking, a CTS ticket should be filed if not already done by the caller. However, if the problem does affect data-taking, then the appropriate expert should be called.
Now that you already know the summary, let's go into the details ...
General Information
Who is on shift for RCF Monitoring ?
During normal business hours (8 AM - 4 PM), the RCF staff members are always on shift. The next shift period goes from 4 PM - 12 AM, which is the responsibility of an RCF operator. The operator name can be found on the RCF Shift Monitor page .
During a run, the time between 12:30 AM - 8:30 AM belongs to a STAR OR a PHENIX shift person on alternating weeks. On BNL lab holidays, STAR or PHENIX is responsible for shifts during the entire day. To see who is responsible for the overnight RCF Monitoring shift, use the Shift Schedule page.
In the case of STAR, the Shift Crew Person position is responsible for the RCF monitoring.
Summary
Please check first the Shift Schedule , when you start taking the Shift Crew Person responsibilities.
In the following sections, we will explain how to monitor the RCF and what you should do.
What are the responsibilities of the person on shift?
The STAR RCF monitoring shift person is required to carry the RCF phone-list above onllinux2 in the STAR counting house. A second list is taped to the STAR Shift Leader's desk. If you do not find this list, Email me immediately. If anyone from the 4 experiments experiences a problem with the RCF, the RCF Monitoring Shift person should call the appropriate expert. The shift person is not required nor qualified to fix the problem. The main responsibility of the shift person is to assess the severity of a problem and decide whether to call the appropriate RCF expert or to file a CTS ticket.
The shift person is required to monitor the data transfer rate to HPSS from the counting house.
The counting house monitoring shifter should be aware of the data transfer to HPSS.
Only problems affecting data-taking justify a call to the expert in the middle of the night.
(1) Mandatory
Monitoring
1-1. HPSS Monitoring
HPSS Check list for the shifter
The data sent to HPSS by STAR can be seen on the STAR DAQ Network Activity summary page. You should see those numbers progress as time passes. The expected rate for STAR is also close to 60 MB/sec. Deviation remaining below 50% for a long perdiod of time (at least an hour) without any increase while lots of data is available for transfer and the client is functionning normally is suspect.
For STAR, errors related to failed pftp connections in the DAQ Operator Log is an indication of a problem.
An overview of the data rate for the four experiments can be seen on the DAQ Summary Snapshot page. A drop or complete stop of the data transfer by all (or most) experiments for a long period of time is a strong indication of a global problem.
The number of PFTP connections should be below 50. A saturation at 50 connections is an indication of a problem.
The space available on the HPSS disk cache should not saturate to the maximum. Check it for STAR ; we also provide the graphs for Phenix, Brahms or Phobos. The line should not leave the yellow area.
If
you find a problem as described in the above check-list
OR
If you receive a call from another experiment reporting similar problems
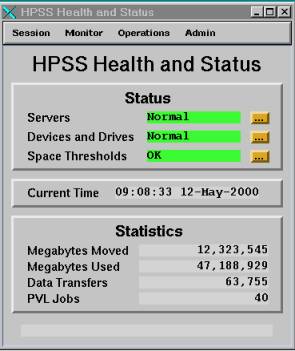
Check the clock in the HPSS GUI is actually working. If not, please, quit and restart the GUI and check the clock again. If the clock is still not functioning, HPSS is simply dead. Call RCF HPSS experts immediately.
Check
the "Servers" status is
[Normal] , [Suspect](the
result a Minor problem) : you do not have to call. If you see the
status changing to a
![]() , call RCF HPSS experts immediately.
, call RCF HPSS experts immediately.
Check the "Space Thresholds" is Normal (green). If you see the "Major Problem" for more than 30 min. , call RCF HPSS experts. Otherwise, the HPSS cache will fill up!
Check "Alarms and Events" status by clicking "Monitor" menu on the top of the GUI. Watch this screen, but red does not necessarily mean that someone needs to be called. Only if there are continual red lines, then expert should be called.
Figure 1. HPSS Health and Status monitor GUI.
On-call person for HPSS problem
Click Current HPSS on call person to see who is covering for HPSS now. The office and beeper numbers summary is indicated above.
|
Razvan Popescu |
X5806, pager: 877-546-9067 |
|
John Riordan |
x7201, pager: 877-526-2715 |
|
Ognian Novakov |
X2813, pager: 877-451-1920 |
|
Grace Tsai |
X3905, pager: 877-629-4452 |
How to setup HPSS monitoring software at the STAR counting house. (not necessary to read, if HPSS GUI has already been set up)
Log on to onllinux2 in the STAR control room as starcrew. See instructions taped to the monitor.
Login
as STAR_op on hpss.rcf.bnl.gov
using ssh by typing
% ssh
hpss.rcf.bnl.gov -l STAR_op
and then enter the password.
(ask Micheal DePhillips <dephilli@bnl.gov>
or Jérôme LAURET <jlauret@bnl.gov>
for the password).
The
procedure starts automatically the HPSS control. Accept the default
values for user and display. A graphical login window (Figure 2)
will prompt you for user ID and Password.
Use user STAR_op and the same password
as for login into HPSS as described in step 2 above.
Type the
username in the first field, THEN SWITCH TO
THE SECOND FIELD (using a tab or the mouse), type the
password and then press "Enter". The main control window
(shown in Figure 1) will show up !
To
logoff ( IMPORTANT !!)
Select [Session]
, [Quit Sammi] and confirm. DO
NOT use [Log off Session].
The
terminal window that initiated the session will not close since its
process handles the X encrypted channel. Minimize it and ignore it.
It will automatically close when the HPSS session will be
terminated.
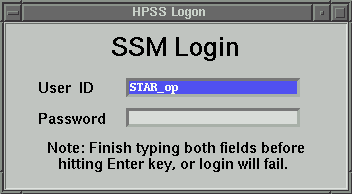
Figure
2. The Sammi Login window
Here are a list of links toward several HPSS related monitoring tools and interfaces.
1-2. Network Monitoring
Network Monitoring
It is important to monitor the network traffic as a network problem may be the reason for a broken data flow / data sinking. In other words, if data sinking stops from the counting house point of view, you MUST determine if the problem is related to HPSS (see section 1-1) or network related.
There are several tools helping to monitor the network traffic. All links provided above may be found on the RCF Network Infrastructure page. We will describe what we believe is important for STAR.
The RCF Gigabit snapshot page is a complex graph showing the overall network layout at the RCF. On top of it, the purple boxes connections to the first green box labeled SW1 shows the traffic between the different counting houses and the main switch SW1. The green number displayed below the purple [ STAR ] box is the number for STAR. If 0, there may be a problem OR STAR is not sinking data ... Now, following the traffic (black line), the next number appears below SW1 on the way toward SW6 ; this number measures the internal traffic rate. Finally, the last relevant number appears in the corner of the connection SW6 to rmds08. This is our final data sinking rate to HPSS . Numbers are integrated transfer rate in MB/sec ... Again, ff any of those numbers goes to 0 it may be the sign of a network problem or the fact that there is really no activity. This complicated graph however can be analyzed in more detailed using the following
STAR DAQ average is another view of our network traffic. It indicates the internal traffic between SW1 and SW4 and shows the averaged by 5 and 30 minutes, monthly and yearly. It is not an integrated value and should show the exact data transfer rate (internal).
The data rate between SW4 and rmds08 can be examined as the last piece of network traffic. The equivalent for all four experiments is available as a traffic snapshot (a copy is available from the RCF traffic snapshot Page)
Not stopping there on our way to data sinking, you can also have a look at HPPS mover traffic page.
(2) Non mandatory monitoring
2-1. Servers Monitoring
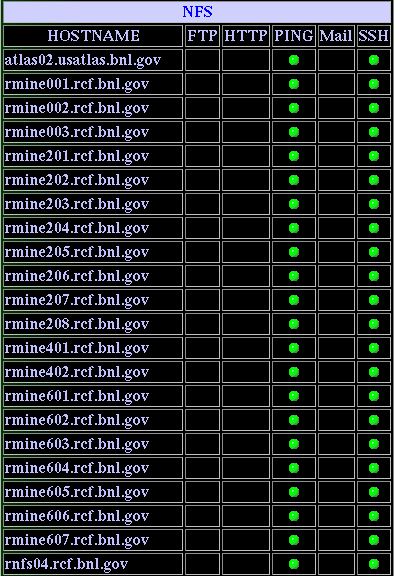
The status of monitored machines can be checked from here. Figure 3 shows the snapshot of the status of monitored machines. You can check the current status of the ssh gateway servers, FTP servers, NFS servers, DNS/NIS servers and mail servers. In this status monitor, green signal indicates OK, yellow is the warning sign and red is a failure sign. Failure (in red) on one of the RMINE (NFS server) machines does not warrant a call to the expert in the middle of the night.
A CTS ticket could/should be filled. However, RKDC (Kerberos servers) machines and ssh gateway machines (RSSH) are critical and DO warrant a late-night call during data-taking. Call the appropriate RCF responsible person (see below). The hard copy of list of RCF staff's home phone number should be available at the control room. If you cannot find this list, please send me (J.Lauret) a note ASAP and I will provide it.
On-Call RCF persons for RKDC and SSHGW problems
|
Maurice Askinazi |
x2159, pager: 877-450-3915 |
|
Shigeki Misawa |
x2635, pager: 877-600-2401 |
 |
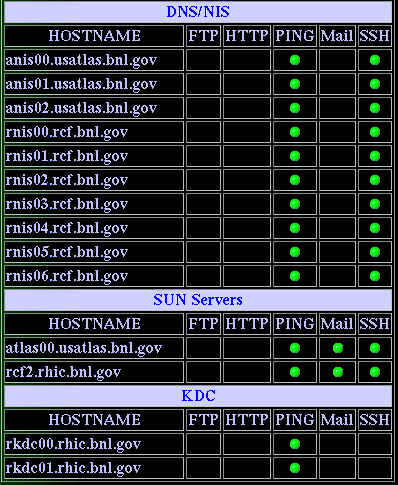 |
Figure 3. Status of monitored machines display. The provided link will show all servers in one column. We did split the view in tow panels for presentation purposes.
2-2 Instructions for CAS and CRS node monitor
Status
of CAS (Central Analysis Server) machines
Status
of the CAS machines (the analysis nodes) can be found here.
The link under " CAS
Operational Status" lists any CAS machines experiencing
problems. Failure on one of the RCAS machines does not warrant a
call to the expert in the middle of the night. A CTS
ticket should be filled.
Status
of CRS (Central Reconstruction Server) machines
Status of
the CRS machines (the reconstruction farm) can be found here.
Failure on one of the CRS machines does not warrant a call to the
expert in the middle of the night. A CTS
ticket should be filed. Reconstruction Farm latest
staging failures is also available.
Other
links to CAS/CRS monitoring tools
can
be found
here (CRS) and here
(CAS)
|
Subsystem |
Name |
Office Phone |
Pager |
|
General |
RCF Operator |
x5480 (4:00pm - 00:00am) |
NA |
|
RNIS and RSSH |
Maurice Askinazi |
x2159 |
877-450-3915 |
|
Shigeki Misawa |
x2635 |
877-600-2401 |
|
|
Network |
Terry Healy |
x4199 |
631-834-5394 |
|
HPSS |
Razvan Popescu |
x5806 |
877-546-9067 |
|
John Riordan |
x7201 |
877-526-2715 |
|
|
Ognian Novakov |
x2813 |
877-451-1920 |
|
|
Grace Tsai |
x3905 |
877-629-4452 |
Paging RCF Personnel
RCF Staff List (a printed list should also be available in the counting house)
Other useful Links for the online QA shifter
RCF
Call Tracking System (CTS) - to submit the trouble ticket
to rcf
Most useful choices are: New,
View,
Search,
Help