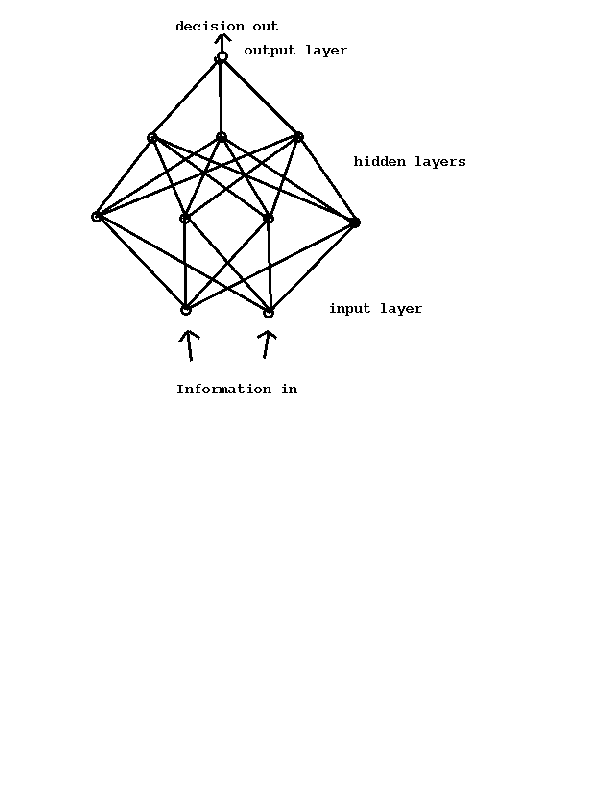
Introduction to Neural Nets: Unlike algorithmic computers biological intelligence makes use of a different means of processing information. The process makes use of neurons which have a large degree of interconnections. In the crudest terms, each neuron receives simple information from a number of other earlier neurons, combines that information with weighting factors that are learned in some manner, and passes its ``decision'' on to many neurons at the next level. See Figure 1 for a approximate, simplified schematic of such a net. The individual output can be taken to be a sigmoid function of the weighted sum of the inputs so that there is a sense that many input conditions will lead to a ``yes'' or ``no'' type output (modeled as the value 0 or 1). It is also possible to have more indeterminate results (``maybe'' or a value of .5) passed along for further processing. The heart of the problem comes in teaching each neuron, whether in a biological system or simulated neural net, how to combine the information it receives and how steep its sigmoid response should be. One should always keep in mind that the simulated neural nets attempt to embody the main features of such a decision making process but that the model neurons are approximate.
Throughout this report all references to a neural net are really references to a feed forward multilayer perceptron which was trained using a back-propagation learning algorithm. The multilayer nature is seen in Figure 1 in that there are four interconnected layers. The feed forward nature is somewhat implied in that information goes in one side and a decision (which could be ``maybe'') comes out the other end. This is unlike a feed back network where the neurons are bi-directional and one seeks to achieve a steady state condition in the net. The back-propagation algorithm refers to the specific details of how the network weights and parameters are determined from the known data.
Without becoming excessively mathematical, our neural net is then composed of neurons that form a weighted sum of the values presented to them and forms an out value which is a function of the weighted sum and sigmoid in shape with respect to the sum. The weights and sigmoid widths need to be determined with a training process.
There are many similarities between the train of the simulated net an a biological net. If a human is presented with very few sample patterns from two distributions and asked to make a rule about future patterns, the reliability when applied to previously unseen patterns is apt to be poor. However, as more patterns are seen the rule is refined and the reliability is increased. This is easily seen at work with many brain teaser games. Of course the more distinct are the two distributions or the simpler the rule the sooner the process should converge. (Except for those of us that never get it.) So to with the simulation of a net. The more patterns on which to train the net the better. Also, the more subtle the distinctions being made, the more training input will be needed. Keep in mind that the simple example in Figure 1 has 33 undetermined parameters.
: Neural Nets for STAR triggers: The task at hand was to investigate the possibility of using neural nets to making triggering decisions for STAR. We restricted our work to dealing with the information in the standard 32 pixel array (8 bins in eta and 4 in phi). Our goal was to train a net on the events from Ron Longacre (processed through GEANT and TAS) to the point where it could distinguish between the mundane events and the special events.
A great number of different configurations were tried and discarded. The current configuration seem large but one must realize that the shapes of some special events are only a few percent different from the shapes of the mundane events. Currently the net consists of 8 input nodes (the events are summed over phi), 32 nodes in the first hidden layer, 16 nodes in the second hidden layer, and one output node. (This results in nearly a 1000 parameters to be determined by training.) There are only 100 of each type of event available. To overcome this limitation, which would not be present with real data, we took 90% of the events of each type and added a random number to each of the 8 eta bins where the number was chosen from a gaussian distribution with a width equal to the square root of the number of counts in the particular bin. In this fashion, 9000 events of each type were constructed. The net was trained with the requirement that normal events should result in 1.0 from the output node and special events should give 0.0, independent of what type of special event they were.
After training was completed the original unmodified events were tested to see if the net could distinguish the patterns. The results are: 85% of RHIC events, 95% of SMK events, 73% of PLS events, 87% of LND events, and 43% of CHIRAL events were correctly identified as mundane or special. (Earlier tests based on moments and other simple tests resulted in 93%, 96%, 87%, 64%, and 86% for the same event types. The earlier tests are better for CHIRAL while the net is better for LND events.) Note that during the testing phase the events were not totally independent from the training set since the training events were based on the original events with random variations added. This may impact the quality of the results.
We observe that the neural net is sensitive to the shape but entirely insensitive to the magnitude or multiplicity. (Read the disclaimer at the beginning again.) A final test was made where, in addition to the result from the net, a simple multiplicity cut was made. Any event that was outside the range of normal multiplicity or was flagged by the net as special was counted as special. With this additional filter, the following results were obtained: CHIRAL - 100%, LND - 99%, PLS - 97%, and SMK - 100%. These are the percentages of events that would have correctly passed the combined trigger test. In addition, 23% of the RHIC events would have been incorrectly passed on to the next level. (Keep in mind that the RHIC events are all CENTRAL collisions and do not contain the more prevalent peripheral collisions which can be rejected by other means.) As above remember that the test events were different from the training events but that they share a common history.
Conclusions: While the results are encouraging two things are needed. The first is more independent events for testing the determined weights and possibly more events for training. (If the scheme described above gives acceptable weights, the fact that we constructed events is irrelevant as long as good results are obtained when testing against new unseen events.) Secondly, the reliance on multiplicity for the best results implies that the event generators must be careful to have consistent multiplicities from event type to event type.
Disclaimer: Both of the authors of this work are new to the field of neural nets and their applications. The reader should keep in mind that we may have missed the obvious or used methods that are not suited for the problem at hand.
Additional Sources of Information: Information can be obtained via anonymous ftp from thep.lu.se in pub/Jetnet/ or from freehep.scri.fsu.edu in freehep/analysis/jetnet. The JETNET 3.0 program was used exclusively for all neural net work reported here.
{kind=link}