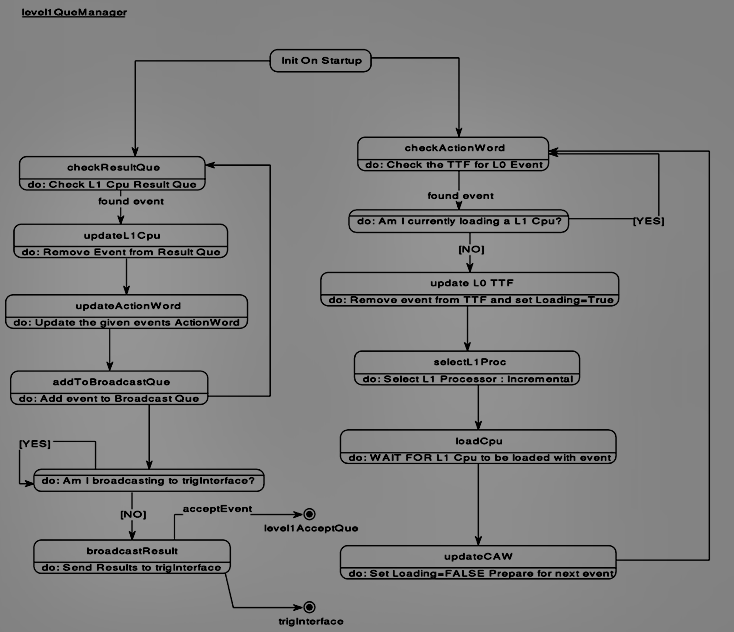
Click on the image for a postscript file.....
In the present simulation architecture the CPU selection is performed incrementally, so that the first "good" event would be loaded to L1CPU_1, the second to L1CPU_2 and so on up to the number of cpus in the L1CPU farm (selected by the user in the input file). When the QueManager has loaded the last L1CPU in the farm it goes back to the first CPU and loads the event there. If this CPU happens to be processing an event the NEW event is placed in the L1CpuMemQue (the depth of this que is also an input parameter). Upon selection of the L1CPU and LOADING=FALSE the L1QueManager loads the event to the CPU. Currently the loading time is fixed with no distribution at 10 microseconds. This represents bandwidth for the worst case scenario, based on the maximum input rate for L1 analysis. In future upgrades of the model it is planned to implement a variable loading time where a mean and distribution can be utilized (see Future Additions ).
The second primary function of the object is to check the results from the L1CPU analysis. The object looks at the L1CpuResultQue for a given L1CPU. The selection of the CPU is performed in the same manner as described above. This restricts the output from Level 1 to the same order as was input from Level 0. Upon finding an event the QueManager updates the trigActionWord and broadcasts the results to the trigInterface . The broadcast has a WAIT period of 220 ns which represents cable delay. The number of "accepts" and "aborts" is recorded.
If the event is accepted at Level 1, it is placed in the level1AcceptQue where the Level 2 Que Manager checks for Level 1 "acccept" events.
Back to the Object Model . J.P. Whitfield, Carnegie Mellon 4/20/95