Next: Reconstruction of Space-Points Up: CATS Track Recognition Strategy Previous: CATS Track Recognition Strategy Contents
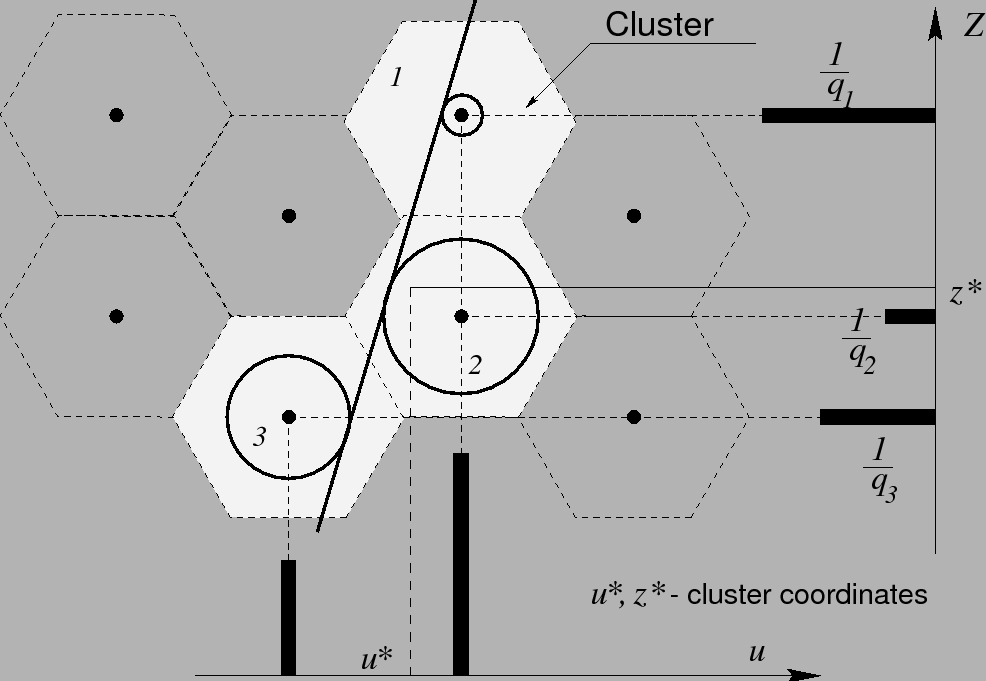
This step is done only for hits in the OTR, since in this detector a track usually produces more than one hit in a layer (up to four in case of double layers). The main idea behind this preliminary clusterization is to resolve left-right ambiguity at least partially and suppress combinatorial pile-up already at this early step of reconstruction.
The clusterization process is illustrated in Fig. 4.3.
In order to account for drift distance information, cluster coordinates
![]() are calculated as a weighted sum of the coordinates of the wires participating in the cluster:
are calculated as a weighted sum of the coordinates of the wires participating in the cluster:
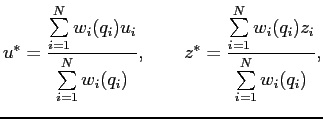
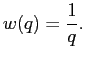
Yury Gorbunov 2010-10-21