Databases
STAR DATABASE INFORMATION PAGES
Frequently Asked Questions
Frequently Asked Questions
Q: I am completely new to databases, what should I do first?
A: Please, read this FAQ list, and database API documentation :
Database documentation
Then, please read How to request new db tables
Don't forget to log in, most of the information is STAR-specific and is protected; If our documentation pages are missing some information (that's possible), please as questions at db-devel-maillist.
Q: I think, I've encountered database-related bug, how can I report it?
A: Please report it using STAR RT system (create ticket), or send your observations to db-devel maillist. Don't hesitate to send ANY db-related questions to db-devel maillist, please!
Q: I am subsystem manager, and I have questions about possible database structure for my subsystem. Whom should I talk to discuss this?
A: Dmitry Arkhipkin is current STAR database administrator. You can contact him via email, phone, or just stop by his office at BNL:
Phone: (631)-344-4922
Email: arkhipkin@bnl.gov
Office: 1-182
Q: why do I need API at all, if I can access database directly?
A: There are a few moments to consider :
a) we need consistent data set conversion from storage format to C++ and Fortran;
b) our data formats change with time, we add new structures, modify old structures;
b) direct queries are less efficient than API calls: no caching,no load balancing;
c) direct queries mean more copy-paste code, which generally means more human errors;
We need API to enable: schema evolution, data conversion, caching, load balancing.
Q: Why do we need all those databases?
A: STAR has lots of data, and it's volume is growing rapidly. To operate efficiently, we must use proven solution, suitable for large data warehousing projects – that's why we have such setup, there's simply no subpart we can ignore safely (without overall performance penalty).
Q: It is so complex and hard to use, I'd stay with plain text files...
A: We have clean, well-defined API for both Offline and FileCatalog databases, so you don't have to worry about internal db activity. Most db usage examples are only a few lines long, so really, it is easy to use. Documentation directory (Drupal) is being improved constantly.
Q: I need to insert some data to database, how can I get write access enabled?
A: Please send an email with your rcas login and desired database domain (e.g. "Calibrations/emc/[tablename]") to arkhipkin@bnl.gov (or current database administrator). Write access is not for everyone, though - make sure that you are either subsystem coordinator, or have proper permission for such data upload.
Q: How can I read some data from database? I need simple code example!
A: Please read this page : DB read example
Q: How can I write something to database? I need simple code example!
A: Please read this page : DB write example
Q: I'm trying to set '001122' timestamp, but I cannot get records from db, what's wrong?
A: In C++, numbers starting with '0' are octals, so 001122 is really translated to 594! So, if you need to use '001122' timestamp (any timestamp with leading zeros), it should be written as simply '1122', omitting all leading zeros.
Q: What time zone is used for a database timestamps? I see EDT and GMT being used in RunLog...
A: All STAR databases are using GMT timestamps, or UNIX time (seconds since epoch, no timezone). If you need to specify a date/time for db request, please use GMT timestamp.
Q: It is said that we need to document our subsystem's tables. I don't have privilege to create new pages (or, our group has another person responsible for Drupal pages), what should I do?
A: Please create blog page with documentation - every STAR user has this ability by default. It is possible to add blog page to subsystem documentation pages later (webmaster can do that).
Q: Which file(s) is used by Load Balancer to locate databases, and what is the order of precedence for those files (if many available)?
A: Files being searched by LB are :
1. $DB_SERVER_LOCAL_CONFIG env var, should point to new LB version schema xml file (set by default);
2. $DB_SERVER_GLOBAL_CONFIG env. var, should point to new LB version schema xml file (not set by default);
3. $STAR/StDb/servers/dbLoadBalancerGlobalConfig.xml : fallback for LB, new schema expected;
if no usable LB configurations found yet, following files are being used :
1. $STDB_SERVERS/dbServers.xml - old schema expected;
2. $HOME/dbServers.xml - old schema expected;
3. $STAR/StDb/servers/dbServers.xml - old schema expected;
DB access: read data
// this will be in chain
St_db_Maker *dbMk=new St_db_Maker("db", "MySQL:StarDb", "$STAR/StarDb");
dbMk->SetDebug();
dbMk->SetDateTime(20090301,0); // event or run start time
dbMk->SetFlavor("ofl"); // pick up offline calibrations
// dbMk->SetFlavor("simu"); // use simulations calibration set
dbMk->Init();
dbMk->Make();
// this is done inside ::Make method
TDataSet *DB = 0;
// "dbMk->" will NOT be needed, if done inside your [subsys]DbMaker.
// Simply use DB = GetInputDb("Calibrations/[subsystem_name]")
DB = dbMk->GetInputDB("Calibrations/[subsystem_name]");
if (!DB) { std::cout << "ERROR: no db maker?" << std::endl; }
St_[subsystem_name][table_name] *[table_name] = 0;
[table_name] = (St_[subsystem_name][table_name]*) DB->Find("[subsystem_name][table_name]");
// fetch data and place it to appropriate structure
if ([table_name]) {
[subsystem_name][table_name]_st *table = [table_name]->GetTable();
std::cout << table->param1 << std::endl;
std::cout << table->paramN << std::endl;
}
DB access: write data
// Initialize db manager
StDbManager* mgr = StDbManager::Instance();
StDbConfigNode* node = mgr->initConfig("Calibrations_[subsystem_name]");
StDbTable* table = node->addDbTable("[subsystem_name][table_name]");
TString storeTime = "2009-01-02 00:00:00"; // calibration timestamp
mgr->setStoreTime(storeTime.Data());
// create your c-struct and fill it with data
[subsystem_name][table_name]_st [tablename];
[table_name].param1 = [some_value];
[table_name].paramN = [some_other_value];
// store data in the table
table->SetTable((char*)&[table_name]);
// store table in dBase
mgr->storeDbTable(table);
Timestamps
TIMESTAMPS
There are three timestamps used in STAR databases;
| beginTime | This is STAR user timestamp and it defines ia validity range |
| entryTime | insertion into the database |
| deactive | either a 0 or a UNIX timestamp - used for turning off a row of data |
EntryTime and deactive are essential for 'reproducibility' and 'stability' in production.
The beginTime is the STAR user timestamp. One manifistation of this, is the time recorded by daq at the beginning of a run. It is valid until the the beginning of the next run. So, the end of validity is the next beginTime. In this example it the time range will contain many event times which are also defined by the daq system.
The beginTime can also be use in calibration/geometry to define a range of valid values.
EXAMPLE: (et = entryTime) The beginTime represents a 'running' timeline that marks changes in db records w/r to daq's event timestamp. In this example, say at some time, et1, I put in an initial record in the db with daqtime=bt1. This data will now be used for all daqTimes later than bt1. Now, I add a second record at et2 (time I write to the db) with beginTime=bt2 > bt1. At this point the 1st record is valid from bt1 to bt2 and the second is valid for bt2 to infinity. Now I add a 3rd record on et3 with bt3 < bt1 so that
1st valid bt1-to-bt2, 2nd valid bt2-to-infinity, 3rd is valid bt3-to-bt1.
Let's say that after we put in the 1st record but before we put in the second one, Lydia runs a tagged production that we'll want to 'use' forever. Later I want to reproduce some of this production (e.g. embedding...) but the database has changed (we've added 2nd and 3rd entries). I need to view the db as it existed prior to et2. To do this, whenever we run production, we defined a productionTimestamp at that production time, pt1 (which is in this example < et2). pt1 is passed to the StDbLib code and the code requests only data that was entered before pt1. This is how production in 'reproducible'.
The mechanism also provides 'stability'. Suppose at time et2 the production was still running. Use of pt1 is a barrier to the production from 'seeing' the later db entries.
Now let's assume that the 1st production is over, we have all 3 entries, and we want to run a new production. However, we decide that the 1st entry is no good and the 3rd entry should be used instead. We could delete the 1st entry so that 3rd entry is valid from bt3-to-bt2 but then we could not reproduce the original production. So what we do is 'deactivate' the 1st entry with a timestamp, d1. And run the new production at pt2 > d1. The sql is written so that the 1st entry is ignored as long as pt2 > d1. But I can still run a production with pt1 < d1 which means the 1st entry was valid at time pt1, so it IS used.
One word of caution, you should not deactivate data without training!
email your request to the database expert.
In essence the API will request data as following:
'entryTime <productionTime<deactive || entryTime< productionTime & deactive==0.'
To put this to use with the BFC a user must use the dbv switch. For example, a chain that includes dbv20020802 will return values from the database as if today were August 2, 2002. In other words, the switch provides a user with a snapshot of the database from the requested time (which of coarse includes valid values older than that time). This ensures the reproducability of production.
If you do not specify this tag (or directly pass a prodTime to StDbLib) then you'll get the latest (non-deactivated) DB records.
Below is an example of the actual queries executed by the API:
select beginTime + 0 as mendDateTime, unix_timestamp(beginTime) as mendTime from eemcDbADCconf Where nodeID=16 AND flavor In('ofl') AND (deactive=0 OR deactive > =1068768000) AND unix_timestamp(entryTime) < =1068768000 AND beginTime > from_unixtime(1054276488) And elementID In(1) Order by beginTime limit 1
select unix_timestamp(beginTime) as bTime,eemcDbADCconf.* from eemcDbADCconf Where nodeID=16 AND flavor In('ofl') AND (deactive=0 OR deactive>=1068768000) AND unix_timestamp(entryTime) < =1068768000 AND beginTime < =from_unixtime(1054276488) AND elementID In(1) Order by beginTime desc limit 1
How-To: user section
Useful database tips and tricks, which could be useful for STAR activities, are stored in this section.
New database tables, complete guide
How-To: request new DB tables
-
First of all, you need to define all required variables you want to store in database, and their compositions. This means, you will have one or more C++ structures, stored as one or more tables in STAR Offline database. Typically, this is stored in either Calibrations or Geometry db domains. Please describe briefly the following: a) how those variables are supposed to be used in offline code (3-5 lines is enough), b) how many entries would be stored in database (e.g. once per run, every 4 hours, once per day * 100 days, etc);
-
Second, you need an IDL file, describing your C/C++ structure(s). This IDL file will be automatically compiled/converted into C++ header and Fortran structure descriptor – so STAR Framework will support your data at all stages automatically. NOTE: comment line length should be less than 80 characters due to STIC limitation.
EXAMPLE of IDL file:
fooGain.idl :
--------------------------------------------------------------------------------------------------------------
/* fooGain.idl*
* Table: fooGain
*
* description: // foo detector base gain
*
*/
struct fooGain {
octet fooDetectorId; /* DetectorId, 1-32 */
unsigned short fooChannel; /* Channel, 1-578*/
float fooGain; /* Gain GeV/channel */
};
--------------------------------------------------------------------------------------------------------------
Type comparison reference table :
-
IDL
C++
short, 16 bit signed integer
short
unsigned short, 16 bit unsigned integer
unsigned short
long, 32 bit signed integer
int
unsigned long, 32 bit unsigned integer
unsigned int
float, 32 bit IEEE float
float
double, 64 bit IEEE double
double
char, 8 bit ISO latin-1
char
octet, 8 bit byte (0x00 to 0xFF)
unsigned char
Generally, you should try to use types with smallest size, which fits your data. For example, if you expect your detector ids to go from 1 to 64, please use “octet” type, which is translated to “unsigned char” (0-255), not integer (0 - 65k).
-
There are two types of tables supported by STAR DB schema: non-indexed table and indexed table. If you are able to fit your data into one record, and you expect it to change completely (all members), than you need non-indexed table. If you know that you'll have, say, 16 rows corresponding to 16 subdetector ids, and only a few of those will change at a time, than you need indexed table. Please write down your index name, if needed (e.g. detectorID) and its range (e.g. 1-16) - if there's no index needed, just write "non-indexed".
-
Calculate average size of your structure, per record. You will need this to understand total disk space/memory requirements – for optimal performance on both database and C++ side, we want our tables to be as small as possible. Bloated tables are hard to retrieve from database, and might consume too much RAM on working node during BFC chain run.
EXAMPLE :In a step 1 we created fooGain.idl file. Now, we need to convert it into header file, so we can check structure size. Let's do that (at any rcas node) :
shell> mkdir TEST; cd TEST; # create temporary working directory
shell> mkdir -p StDb/idl; # create required directory structure
shell> cp fooGain.idl StDb/idl/; # copy .idl file to proper directoryshell> cons; # compile .idl file
After that, you should be able to include .sl44_gcc346/include/fooGain.h into your test program, so you can call sizeof(fooGain_st) to determine structure size, per entry. We need to write down this number too. Ultimately, you should multiply this size by expected number of entries from step 1 – generally, this should fit into 1 Gb limit (if not – it needs to be discussed in detail).
-
Decide on who is going to insert data into those tables, write down her/his rcf login (required to enable db “write” access permissions). Usually, subsystem coordinator is a best choice for this task.
-
Create Drupal page (could be your blog, or subsystem page) with the information from steps 1-5, and send a link to it to current database administrator or db-devel maillist. Please allow one day for table creation and propagation of committed .idl files to .dev version of STAR software. Done! If you need to know how to read or write your new tables, please read Frequently Asked Questions page, it has references to read/write db examples Frequently Asked Questions.
Time Stamps
| STAR Computing | Tutorials main page |
| STAR Databases: TIMESTAMP
|
|
| Offline computing tutorial | |
TIMESTAMPS
|
There are three timestamps used in STAR databases;
EntryTime and deactive are essential for 'reproducibility' and 'stability' in production. The beginTime is the STAR user timestamp. One manifistation of this, is the time recorded by daq at the beginning of a run. It is valid unti l the the beginning of the next run. So, the end of validity is the next beginTime. In this example it the time range will contain many eve nt times which are also defined by the daq system. The beginTime can also be use in calibration/geometry to define a range of valid values. EXAMPLE: (et = entryTime) The beginTime represents a 'running' timeline that marks changes in db records w/r to daq's event timestamp. In this example, say at some tim e, et1, I put in an initial record in the db with daqtime=bt1. This data will now be used for all daqTimes later than bt1. Now, I add a second record at et2 (time I write to the db) with beginTime=bt2 > bt1. At this point the 1st record is valid from bt1 to bt2 and the second is valid for bt2 to infinity. Now I add a 3rd record on et3 with bt3 < bt1 so that
Let's say that after we put in the 1st record but before we put in the second one, Lydia runs a tagged production that we'll want to 'use' fo rever. Later I want to reproduce some of this production (e.g. embedding...) but the database has changed (we've added 2nd and 3rd entries). I need to view the db as it existed prior to et2. To do this, whenever we run production, we defined a productionTimestamp at that production time, pt1 (which is in this example < et2). pt1 is passed to the StDbLib code and the code requests only data that was entered before pt1. This is how production in 'reproducible'. The mechanism also provides 'stability'. Suppose at time et2 the production was still running. Use of pt1 is a barrier to the production from 'seeing' the later db entries. Now let's assume that the 1st production is over, we have all 3 entries, and we want to run a new production. However, we decide that the 1st entry is no good and the 3rd entry should be used instead. We could delete the 1st entry so that 3rd entry is valid from bt3-to-bt2 but the n we could not reproduce the original production. So what we do is 'deactivate' the 1st entry with a timestamp, d1. And run the new production at pt2 > d1. The sql is written so that the 1st entry is ignored as long as pt2 > d1. But I can still run a production with pt1 < d1 which means the 1st entry was valid at time pt1, so it IS used. email your request to the database expert.
In essence the API will request data as following: 'entryTime <productionTime<deactive || entryTime< productionTime & deactive==0.' To put this to use with the BFC a user must use the dbv switch. For example, a chain that includes dbv20020802 will return values from the database as if today were August 2, 2002. In other words, the switch provides a user with a snapshot of the database from the requested time (which of coarse includes valid values older than that time). This ensures the reproducability of production.
Below is an example of the actual queries executed by the API:
select unix_timestamp(beginTime) as bTime,eemcDbADCconf.* from eemcDbADCconf Where nodeID=16 AND flavor In('ofl') AND (deactive=0 OR deactive>=1068768000) AND unix_timestamp(entryTime) < =1068768000 AND beginTime < =from_unixtime(1054276488) AND elementID In(1) Order by beginTime desc limit 1
For a description of format see ....
|
How-To: admin section
This section contains various pages explaining how to do typical STAR DB administrative tasks. Warning: this section and recipies are NOT for users, but for administrator - following this recipies may be harmful to STAR, if improperly used.
Basic Database Storage Structure
Introduction
To ease maintainence of databases, a common storage structure is used where applicable. Such a structure has been devised for such database types as Conditions, Configurations, Calibrations, and Geometry. Other database types (e.g. RunLog & Production Database) require additional low level structures specific to the access requirements for the data they contain. These shall be documented independently as they are developed. The base table structures are discussed according to their function. Within each sub-section, the real table names are written with purple leters.
- Schema Definition
- Named References
- Index
- Data Storage
- Configuration (ensemble links) *
- Catalog of Configurations *
Schema DefinitionThe data objects stored in DB are pre-defined by c-structs in header files (located in $STAR/StDb/include directories). The database is fed the information about these c-structs which it stores in a pair of tables used to re-construct the c-struct definitions used for storing the data. This information can also be used to provide the memory allocation for the tables returned in the C++ API, but this can also be over-ridden to request any c-struct type allowed by the request. That is, as long as the table requested contained (at some time) items in the user-input c-struct description, the data will be return in the format requested. To perform such operations, the two DB tables used are,
|
|
| The schema table holds the names of all elements associated with a c-struct, thier relative order in the c-struct, and in which schema-versions each element exists. The table contains the fields, |
|
| *** Will replace "position" field and add information for total binary store of structure but requires that the schema-evolution model be modified. This will be for next interation of database storage structure |
Named ReferencesThere are c-structs which are used for more than one purpose. For example, Daq's detector structure is common to all types of detectors but referenced by different names when a detector specific set of data is requested or stored. Thus a request for a structure is actually a request for a named reference which in many cases is simply the name of the structure but can be different. This information is kept in the namedRef table which contains; |
|
IndexData is accessed from the database via reference contained in an index table called dataIndex. The purpose of this table is to provide access to specific rows of specific storage tables per the request information of name, timestamp, and version . Additional requests for specific element identifiers are also allowed (e.g. Sector01 of the tpc)via this index. The table contains the following fields; |
|
Data StorageThere are 2 general type of storage tables used in the mysql database. The first type of storage makes use of MySQL basic storage types to store the data as specified by the schema of the c-struct. That is, each element of the c-struct is given a column in which values are recorded and can subsequently be queried against. The name of the table is the same as the name of the structure obtained from the structure table and referenced directly from the namedRef table. Within this structure, large arrays can be handled using binary storage (within mysql) by defining the storage type as being binary. Each row of each storage table contains a unique row id that is used by the dataIndex table. example: The tpcElectronics table contains the following fields; |
|
| An additional storage table is used for those table which are more easily stored in purely binary form. This is different then the note above where some "columns" of a c-struct are large arrays and can be independently (column-specific) stored in binary form. What is meant by purely binary form is that the entire c-struct (&/or many rows) is stored as a single binary blob of data. This is (to be) handled via the bytes table. The rows in the bytes table are still pointed to via the dataIndex table.
The content of the stored data is extracted using the information about how it was stored from the namedRef, schema, & structure tables. The bytes table contains the following fields; |
|
ConfigurationsThe term Configurations within the Star Databases refers to ensembles of data that are linked together in a common "named" structure. The extent of a Configuration may span many Star Databases (i.e. a super-configuration) to encompass a entire production configuration but is also complete at each database. For example, there is a data ensemble for the Calibrations_tpc database that can be requested explicity but that can also be linked together with a Calibrations_svt, Calibrations_emc, ... configurations to form a Calibrations configuration. The data ensembles are organized by a pair of tables found in each database. These tables are
The Nodes table contains the following fields; |
|
| The NodeRelation table contains the following fields; |
|
CatalogThe Catalog structure in the database is used to organized different configurations into understandable groupings. This is much like a folder or directory system of configurations. Though very similar to the configuration database structure it is different in use. That is, the Nodes and NodeRelation tables de-reference configurations as a unique data ensemble per selection. The Catalog is used to de-references many similar configurations into groupings associated with tasks. The Catalog table structure has only seen limited use in Online databases and is still under development. Currently there 2 tables associated with the catalog,
The Nodes table contains the following fields; |
|
| The NodeRelation table contains the following fields; |
|
commentThe Offline production chain does not use the Configurations & Catalog structures provided by the database. Rather an independent configuration is stored and retrieved via an offline table, tables_hierarchy, that is the kept within the St_db_Maker. This table contains the fields; |
|
This table is currently stored as a binary blob in the
params
database.
Creating Offline Tables
HOW TO ADD NEW TABLE TO DATABASE:
create a working directory.
$> cvs co StDb/idl (overkill - but so what) $> cp StDb/idl/svtHybridDriftVelocity.idl . $> mkdir include && mkdir xml $> cp svtHybridDriftVelocity.idl include/ $> mv include/svtHybridDriftVelocity.idl include/svtHybridDriftVelocity.h $> cp -r ~deph/updates/pmd/070702/scripts/ . # this directory is in cvs $> vim include/svtHybridDriftVelocity.h
### MAKE SURE your .idl file comments are less than 80 characters due to STIC limitation. "/* " and " */" also counted, so real comment line should be less than 74 chars.
### Check and change datatypes - octets become unsigned char and long becomes int, see table for mapping details:
| IDL | C++ | MySQL |
| short, 16 bit signed integer | short, 2 bytes | SMALLINT (-32768...32768) |
| unsigned short, 16 bit unsigned integer | unsigned short, 2bytes | SMALLINT UNSIGNED (0...65535) |
| long, 32 bit signed integer | int, 4 bytes | INT (-2147483648...2147483647) |
| unsigned long, 32 bit unsigned integer | unsigned int, 4 bytes | INT UNSIGNED (0...4294967295) |
| float, 32 bit IEEE float | float, 4 bytes | FLOAT |
| double, 64 bit IEEE double | double, 8 bytes | DOUBLE |
| char, 8 bit ISO latin-1 | char, 1 byte | CHAR |
| octet, 8 bit byte (0x00 to 0xFF) | unsigned char, 1 byte | TINYINT UNSIGNED (0...255) |
NOW execute a bunch of scripts (italics are output) ( all scripts provide HELP when nothing is passed) .....
1) ./scripts/dbTableXml.pl -f include/svtHybridDriftVelocity.h -d Calibrations_svt
inputfile= include/svtHybridDriftVelocity.h
input database =Calibrations_svt
******************************
*
* Running dbTableXML.pl
*
outputfile = xml/svtHybridDriftVelocity.xml
******************************
2) ./scripts/dbDefTable.pl -f xml/svtHybridDriftVelocity.xml -s robinson.star.bnl.gov -c
#####output will end with create statement####
3) ./scripts/dbGetNode.pl -s robinson.star.bnl.gov -d Calibrations_svt
###retuns a file called svtNodes.xml
4) vim svtNodes.xml
###add this line <dbNode> svtHybridDriftVelocity <StDbTable> svtHybridDriftVelocity </StDbTable> </dbNode>
### this defines the node in the Nodes table
5) ./scripts/dbDefNode.pl -s robinson.star.bnl.gov -f svtNodes.xml
###garbage output here....
###now do the same for NodeRelations table
6) ./scripts/dbGetConfig.pl -s robinson.star.bnl.gov -d Calibrations_svt
###might retrun a couple of different configurations (svt definatetely does)
###we're interested in
7) vim Calibrations_svt_reconV0_Config.xml
###add this line <dbNode> svtHybridDriftVelocity <StDbTable> svtHybridDriftVelocity </StDbTable> </dbNode>
8) /scripts/dbDefConfig.pl -s robinson.star.bnl.gov -f Calibrations_svt_reconV0_Config.xml
IF YOU NEED TO UPDATE TABLE, WHICH NAME IS DIFFERENT FROM C++ STRUCTURE NAME:
$> ./scripts/dbDefTable.pl -f xml/
<table_xml>
.xml -s <dbserver>.star.bnl.gov -n
<table_name>
;
</table_name>
</dbserver>
</table_xml>How to check if table name does not equal to c++ struct name :
mysql prompt> select * from Nodes where structName = 'c++ struct name'
This will output the "name", which is real db table name, and "structName", which is the c++ struct name.
IF YOU NEED TO CREATE A NEW PROTO-STRUCTURE (no storage):
./scripts/dbDefTable.pl -f xml/<structure>.xml -s robinson.star.bnl.gov -e
IF YOU NEED TO CREATE A NEW TABLE BASED ON THE EXISTING STRUCTURE:
checkout proto-structure IDL file, convert to .h, then to .xml, then do:
$> ./scripts/dbDefTable.pl -f xml/<structure>.xml -s .star.bnl.gov -s <table-name><br />
then add mapping entry to the tableCatalog (manually)IMPORTANT: WHEN NEW TPC TABLE IS CREATED, THERE SHOULD BE A NEW LOG TRIGGER DEFINED!
please check tmp.dmitry/triggers directory at robinson for details..
-Dmitry
Deactivating records
A full description of the deactivation feild can be found here
http://drupal.star.bnl.gov/STAR/comp/db/time-stamps
Briefly, it is the field that removes a record from a particular query based on time. This allows for records that are found to be erroneous, to remain available to older libraries that may have used the values.
The deactive field in the database is an integer, that contains a UNIX Time Stamp.
IMPORTANT - entryTime is a timestamp which will get changed with an update - this needs to remain the same...so set entryTime = entryTime.
To deactivate a record:
1) You must have write privileges on robinson
2) There is no STAR GUI or C++ interface for this operation so it must be done from either the MySQL command line or one of the many MySQL GUIs e.g., PHPAdmin, etc.
3) update <<TABLE>> set entryTime = entryTime, deactive = UNIX_TIMESTAMP(now()) where <<condition e.g., beginTIme between "nnnn" and "nnnn">>
4) do a SELECT to check if OK, that's it!
Element IDs
PHILOSOPHY
Element IDs are part of the OFFLINE Calibrations data primary key.
This is the mechanism that allows more the one row of data returned per time stamp (beginTime).
If the elementID is not set to 0 and is set to n, the API will return between 1 and n rows depending on how many rows have be inserted into the database.
A change INCREASING the elementID is backward compatable with a table that had element ID originally set to 0. The only thing to watch out for is a message that will read something like n rows looked for 1 return.
IMPLIMENTATION
In order for this to work three actions need to be taken:
1) Insert the rows with the element ID incrementing 1,2,3...
2) an new table called blahIDs needs to be created - the syntax is important and blah should be replaced with something descriptive.
3) in the nodes table identify the index by update in relevant node (table) and update the index feild with blah
For example the pmd SMCalib table wants to return 24 rows:
A table is created and filled (onlthing different will be the table name and the third "descriptive column" and the number of rows:
mysql> select * from pmdSmIDs;
+----+-----------+----+
| ID | elementID | SM |
+----+-----------+----+
| 1 | 1 | 1 |
| 2 | 2 | 2 |
| 3 | 3 | 3 |
| 4 | 4 | 4 |
| 5 | 5 | 5 |
| 6 | 6 | 6 |
| 7 | 7 | 7 |
| 8 | 8 | 8 |
| 9 | 9 | 9 |
| 10 | 10 | 10 |
| 11 | 11 | 11 |
| 12 | 12 | 12 |
| 13 | 13 | 13 |
| 14 | 14 | 14 |
| 15 | 15 | 15 |
| 16 | 16 | 16 |
| 17 | 17 | 17 |
| 18 | 18 | 18 |
| 19 | 19 | 19 |
| 20 | 20 | 20 |
| 21 | 21 | 21 |
| 22 | 22 | 22 |
| 23 | 23 | 23 |
| 24 | 24 | 24 |
+----+-----------+----+
24 rows in set (0.01 sec)
The the Nodes table is update to read as follows:
mysql> select * from Nodes where name = 'pmdSMCalib' \G
*************************** 1. row ***************************
name: pmdSMCalib
versionKey: default
nodeType: table
structName: pmdSMCalib
elementID: None
indexName: pmdSm
indexVal: 0
baseLine: N
isBinary: N
isIndexed: Y
ID: 6
entryTime: 2005-11-10 21:06:11
Comment:
1 row in set (0.00 sec)
+++++++++++++++++++++++++++++
note the index field reads pmdSm not the default none.
HOW-TO: elementID support
HOW-TO enable 'elementID' support for a given offline table
Let's see how elementID support could be added on example of "[bemc|bprs|bsmde|bsmdp]Map" tables.
1. Lets' try [bemc|bprs]Map table first:
1.1 Create table 'TowerIDs' (4800 channels)
CREATE TABLE TowerIDs ( ID smallint(6) NOT NULL auto_increment, elementID int(11) NOT NULL default '0', Tower int(11) NOT NULL default '0', KEY ID (ID), KEY Tower (Tower) ) ENGINE=MyISAM DEFAULT CHARSET=latin1;
1.2 Fill this table with values (spanning from 1 to [maximum number of rows]):
INSERT INTO TowerIDs VALUES (1,1,1); INSERT INTO TowerIDs VALUES (2,2,2); INSERT INTO TowerIDs VALUES (3,3,3); ... INSERT INTO TowerIDs VALUES (4800,4800,4800);
Sample bash script to generate ids
#!/bin/sh echo "USE Calibrations_emc;" for ((i=1;i<=4800;i+=1)); do echo "INSERT INTO TowerIDs VALUES ($i,$i,$i);" done for ((i=1;i<=18000;i+=1)); do echo "INSERT INTO SmdIDs VALUES ($i,$i,$i);" done
1.3 Update 'Nodes' table to make it aware of new index :
UPDATE Nodes SET Nodes.indexName = 'Tower' WHERE Nodes.structName = 'bemcMap'; UPDATE Nodes SET Nodes.indexName = 'Tower' WHERE Nodes.structName = 'bprsMap';
2. Now, smdChannelIDs (18000 channels)
1.1 Create db index table:
CREATE TABLE SmdIDs ( ID smallint(6) NOT NULL auto_increment, elementID int(11) NOT NULL default '0', Smd int(11) NOT NULL default '0', KEY ID (ID), KEY Smd (Smd)
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
1.2 Fill this table with values:
INSERT INTO SmdIDs VALUES (1,1,1); INSERT INTO SmdIDs VALUES (2,2,2); INSERT INTO SmdIDs VALUES (3,3,3); ... INSERT INTO SmdIDs VALUES (18000,18000,18000);
(see helper bash script above)
1.3 Update 'Nodes' to make it aware of additional index :
UPDATE Nodes SET Nodes.indexName = 'Smd' WHERE Nodes.structName = 'bsmdeMap'; UPDATE Nodes SET Nodes.indexName = 'Smd' WHERE Nodes.structName = 'bsmdpMap';
LAST STEP: Simple root4star macro to check that everything is working fine ( courtesy of Adam Kocoloski ):
{ gROOT->Macro("LoadLogger.C");
gROOT->Macro("loadMuDst.C");
gSystem->Load("StDbBroker");
gSystem->Load("St_db_Maker");
St_db_Maker dbMk("StarDb", "MySQL:StarDb");
// dbMk.SetDebug(10); // Could be enabled to see full debug output
dbMk.SetDateTime(20300101, 0);
dbMk.Init();
dbMk.GetInputDB("Calibrations/emc/y3bemc");
dbMk.GetInputDB("Calibrations/emc/map");
}
Process for Defining New or Evolved DB Tables
Introduction
The process for defining new database tables has several steps, many are predicated on making the data available to the offline infrastructure. The steps are listed here and detailed further down. Currently, the limitations on people performing these steps are those of access protection either in writing to the database or updating the cvs repository. Such permissions are given to specific individuals responsible per domain level (e.g. Tpc, Svt,...) .
- Schema Definition in Database
- Data loading into database
- Idl definition in Offline repository
- Table (Query) list for St_db_Maker (now obsolete)
- Table (Query) support for StDbLib
Several of the steps involve running perl scripts. Each of these scripts require arguments. Supplying no arguments will generate a description of what the script will do and what arguments are needed/optional.
Schema Definition in DatabaseThe data objects stored in DB are pre-defined by c-structs in header files (located in $STAR/StDb/include directories). The database is fed the information about these c-structs which it stores for use during later read and write operations. The process is performed by a set of perl scripts which do the following; |
|
| These steps are done pointing to a specific database (and a specific MySQL server). That is, the schema used to store data in a database is kept within that database so there is no overlap between, say, a struct defined for the tpc Calibrations and that defined for the emc Calibrations.
Example of taking a new c-struct through to making it available in a Configuration (such as used in Offline).
|
Data Loading into DataBaseThe data loading into the database can take many forms. The most typical is via the C++ API and can be done via a ROOT-CINT macro once the c-struct has been compiled and exists in a shared library.
|
Idl definitions in the Offline RepositoryFor data to be accessed in the offline chain, a TTable class for the database struct must exist. The current pre-requesite for this to occur is the existance of an idl file for the structure. This is the reason that the dbMakeFiles.pl was written. Once the dbMakeFiles.pl script is run for a specific structure to produce the idl file from the database record of the schema, this file must be placed in a repository which the Offline build scripts know about in order for the appropriate TTable to be produced. This repository is currently;
For testing new tables in the database with the TTable class;
|
Table (Query) List for St_db_Maker
(Now Obsolete)To access a set of data in the offline chain, The St_db_Maker needs to know what data to request from the database. This is predetermined as the St_db_Maker's construction and Init() phases. Specifically, the St_db_Maker is constructed with "const char* maindir" argument of the form,
The structure of this list is kept only inside the St_db_Maker and stored within a binary blob inside the params database. Updates must be done only on "www.star.bnl.gov".
|
Table (Query) List from StDbLib
The C++ API was written to understand the Configuration tables structure and to provide access to an ensemble of data with a single query. For example, the configuration list is requested by version name and provides "versioning" at the individual table level. It also prepares the list with individual element identifiers so that different rows (e.g. tpc-sectors, emc-modules, ...) can be accessed independently as well as whether the table is carries a "baseLine" or "time-Indexed" attribute for which provide information about how one should reference the data instances.
Storage of a Configuration can be done via the C++ API (see StDbManager::storeConfig()) but is generally done via the perl script dbDefConfig.pl. The idea behind the configuration is to allow sets of structures to be linked together in an ensemble. Many such ensembles could be formed and identified uniquely by name. However, we currently do not use this flexibility in the Offline access model hence only 1 named ensemble exists per database. In the current implementation of the Offline access model, the St_db_Maker requests this 1 configuration from the StDbBroker which passes the request to the C++ API. This sole configurations is returned to the St_db_Maker as a array of c-structs identifying each table by name, ID, and parent association.
Set up replication slave for Offline and FC databases
Currently, STAR is able to provide nightly Offline and FC snapshots to allow easy external db mirror setup.
Generally, one will need three things :
- MySQL 5.1.73 in either binary.tgz form or rpm;
- Fresh snapshot of the desired database - Offline or FileCatalog;
- Personal UID for every external mirror/slave server;
Current STAR policy is that every institution must have a local maintainer with full access to db settings.
Here are a few steps to get external mirror working :
- Request "dbuser" account at "fc3.star.bnl.gov", via SKM ( https://www.star.bnl.gov/starkeyw/ );
- Log in to dbuser@fc3.star.bnl.gov;
- Cd to /db01/mysql-zrm/offline-daily-raw/ or /db01/mysql-zrm/filecatalog-daily-raw to get "raw" mysql snapshot version;
- Copy backup-data file to your home location as offline-snapshot.tgz and extract it to your db data directory (we use /db01/offline/data at BNL);
- Make sure your configuration file (/etc/my.cnf) is up to date, all directories point to your mysql data directory, and you have valid server UID (see example config at the bottom of page). If you are setting up new mirror - please request personal UID for your new server from STAR DB administrator, otherwise please reuse existing UID; Note: you cannot use one UID for many servers, even if you have many local mirrors - you MUST have personal UID for each server.
- If you are running Scientific Linux 6, make sure you have either /etc/init.d/mysqld or /etc/init.d/mysqld_multi scripts, and "mysqld" or "mysqld_multi" is registered as service with chkconfig.
- Start MySQL with "service mysqld start" or "service mysqld_multi start 3316". Replication should be OFF at this step (skip-slave-start option in my.cnf), because we need to update master information first.
- Log in to mysql server and run 'CHANGE MASTER TO ...' followed by 'SLAVE START' to initalize replication process.
Steps 1-8 should complete replication setup. Following checks are highly recommended :
- Make sure your mysql config has "report-host" and "report-port" directives set to your db host name and port number. This is requred for indirect monitoring.
- Make sure your server has an ability to restart in case of reboot/crash. For RPM MySQL version, there is a "mysqld" or "mysqld_multi" script (see attached files as examples), which you should register with chkconfig to enable automatic restart.
- Make sure you have local db monitoring enabled. It could be one of the following : Monit, Nagios, Mon (STAR), or some custom script that does check BOTH server availability/accessibility and IO+SQL replication threads status.
If you require direct assistance with MySQL mirror setup from STAR DB Administrator, you should allow DB admin's ssh key to be installed to root@your-db-mirror.edu.
At this moment, STAR DB Administrator is Dmitry Arkhipkin (arkhipkin@bnl.gov) - feel free to contact me about ANY problems with STAR or STAR external mirror databases, please.
Typical MySQL config for STAR OFFLINE mirror (/etc/my.cnf) :
[mysqld]<br />
user = mysql<br />
basedir = /db01/offline/mysql<br />
datadir = /db01/offline/data<br />
port = 3316<br />
socket = /tmp/mysql.3316.sock<br />
pid-file = /var/run/mysqld/mysqld.pid<br />
skip-locking<br />
log-error = /db01/offline/data/offline-slave.log.err<br />
max_allowed_packet = 16M<br />
max_connections = 4096<br />
table_cache=1024<br />
query-cache-limit = 1M<br />
query-cache-type = 1<br />
query-cache-size = 256M<br />
sort_buffer = 1M<br />
myisam_sort_buffer_size = 64M<br />
key_buffer_size = 256M<br />
thread_cache = 8<br />
thread_concurrency = 4<br />
relay-log=/db01/offline/data/offline-slave-relay-bin<br />
relay-log-index=/db01/offline/data/offline-slave-relay-bin.index<br />
relay-log-info-file=/db01/offline/data/offline-slave-relay-log.info<br />
master-info-file=/db01/offline/data/offline-slave-master.info<br />
replicate-ignore-db = mysql<br />
replicate-ignore-db = test<br />
replicate-wild-ignore-table = mysql.%<br />
read-only<br />
report-host = [your-host-name]<br />
report-port = 3316<br />
server-id = [server PID] <br />
# line below should be commented out after 'CHANGE MASTER TO ...' statement applied.<br />
skip-slave-start [mysqld_safe]<br />
log=/var/log/mysqld.log<br />
pid-file=/var/run/mysqld/mysqld.pid<br />
timezone=GMTTypical 'CHANGE MASTER TO ...' statement for OFFLINE db mirror :
CHANGE MASTER TO MASTER_HOST='robinson.star.bnl.gov', MASTER_USER='starmirror', MASTER_PASSWORD='[PASS]', MASTER_PORT=3306, MASTER_LOG_FILE='robinson-bin.00000[ZYX]', MASTER_LOG_POS=[XYZ], MASTER_CONNECT_RETRY=60; START SLAVE; SHOW SLAVE STATUS \G
You can find [PASS] in master.info, robinson-bin.00000[ZYX] and [XYZ] in relay-log.info files in offline-snapshot.tgz archive
database query for event timestamp difference calculation
Database query, used by Gene to calculate [run start - first event] time differences...
select ds.runNumber,ds.firstEventTime, (ds.firstEventTime-rd.startRunTime),(rd.endRunTime-ds.lastEventTime) from runDescriptor as rd left join daqSummary as ds on ds.runNumber=rd.runNumber where rd.endRunTime>1e9 and ds.lastEventTime>1e9 and ds.firstEventTime>1e9;
Moved to protected page, because it is not recommended to use direct online database queries for anybody but online experts.
How-To: subsystem coordinator
Recommended solutions for common subsystem coordinator's tasks reside here.
Please check pages below.
Database re-initialization
It is required to
a) initialize Offline database for each subsystem just before new Run,
..and..
b) put "closing" entry at the end of the "current" Run;
To make life easier, there is a script which takes database entry from specified time, and re-inserts it at desired time. Here it is:
void table_reupload(const char* fDbName = 0, const char* fTableName = 0, const char* fFlavorName = "ofl",
const char* fRequestTimestamp = "2011-01-01 00:00:00",
const char* fStoreTimestamp = "2012-01-01 00:00:00" ) {
// real-life example :
// fDbName = "Calibrations_tpc";
// fTableName = "tpcGas";
// fFlavorName = "ofl"; // "ofl", "simu", other..
// fRequestTimestamp = "2010-05-05 00:00:00";
// fStoreTimestamp = "2011-05-05 00:00:00";
if (!fDbName || !fTableName || !fFlavorName || !fRequestTimestamp || ! fStoreTimestamp) {
std::cerr << "ERROR: Missing initialization data, please check input parameters!\n";
return;
}
gSystem->Setenv("DB_ACCESS_MODE", "write");
// Load all required libraries
gROOT->Macro("LoadLogger.C");
gSystem->Load("St_base.so");
gSystem->Load("libStDb_Tables.so");
gSystem->Load("StDbLib.so");
// Initialize db manager
StDbManager* mgr = StDbManager::Instance();
mgr->setVerbose(true);
StDbConfigNode* node = mgr->initConfig(fDbName);
StDbTable* dbtable = node->addDbTable(fTableName);
//dbtable->setFlavor(fFlavorName);
// read data for specific timestamp
mgr->setRequestTime(fRequestTimestamp);
std::cout << "Data will be fetched as of [ " << mgr->getDateRequestTime() << " ] / "<< mgr->getUnixRequestTime() <<" \n";
mgr->fetchDbTable(dbtable);
// output results
std::cout << "READ CHECK: " << dbtable->printCstructName() << " has data: " << (dbtable->hasData() ? "yes" : "no") << " (" << dbtable->GetNRows() << " rows)" << std::endl;
if (!dbtable->hasData()) {
std::cout << "ERROR: This table has no data to reupload. Please try some other timestamp!";
return;
} else {
std::cout << "Data validity range, from [ " << dbtable->getBeginDateTime() << " - " << dbtable->getEndDateTime() << "] \n";
}
char confirm[255];
std::string test_cnf;
std::cout << "ATTENTION: please confirm that you want to reupload " << fDbName << " / " << fTableName << ", " << fRequestTimestamp << " data with " << fStoreTimestamp << " timestamp.\n Type YES to proceed: ";
std::cin.getline(confirm,256);
test_cnf = confirm;
if (test_cnf != "YES") {
std::cout << "since you've typed \"" << test_cnf << "\" and not \"YES\", data won't be reuploaded." << std::endl;
return;
}
// store data back with new timestamp
if (dbtable->hasData()) {
mgr->setStoreTime(fStoreTimestamp);
if (mgr->storeDbTable(dbtable)) {
std::cout << "SUCCESS: Data reupload complete for " << fDbName << " / " << fTableName << " [ flavor : " << fFlavorName << " ]"
<< "\n" << "Data copied FROM " << fRequestTimestamp << " TO " << fStoreTimestamp << std::endl << std::endl;
} else {
std::cerr << "ERROR: Something went wrong. Please send error message text to DB Admin!" << std::endl;
}
}
}New subsystem checklist
DB: New STAR Subsystem Checklist
1. Introduction
There are three primary database types in STAR: Online databases, Offline databases and FileCatalog. FileCatalog database is solely managed by STAR S&C, so subsystem coordinators should focus on Online and Offline databases only.
Online database is dedicated to subsystem detector metadata, collected during the Run. For example, it may contain voltages, currents, error codes, gas meter readings or something like this, recorded every 1-5 minutes during the Run. Or, it may serve as a container for derived data, like online calibration results.
Online db metadata are migrated to Offline db for further usage in STAR data production. Major difference between Online and Offline is the fact that Online db is optimized for fast writes, and Offline is optimized for fast reads to achieve reasonable production times. Important: each db type has its own format (Offline is much more constrained).
Offline database contains extracts from Online database, used strictly as accompanying metadata for STAR data production purposes. This metadata should be preprocessed for easy consumption by production Makers, thus it may not contain anything involving complex operations on every data access.
2. Online database key moments
o) Please don't plan your own database internal schema. In a long run, it won't be easy to maintain custom setup, therefore, please check possible options with STAR db administrator ASAP.
o) Please decide on what exactly you want to keep track of in Online domain. STAR DB administrator will help you with data formats and optimal ways to store and access that data, but you need to define a set of things to be stored in database. For example, if your subsystem is connected to Slow Controls system (EPICS), all you need is to pass desired channel names to db admistrator to get access to this data via various www access methods (dbPlots, RunLog etc..).
3. Offline database key moments
o) ...
o) ...
Online Databases
Online Databases
Online databases are :
onldb.starp.bnl.gov:3501 - contains 'RunLog', 'Shift Sign-up' and 'Online' databases
onldb.starp.bnl.gov:3502 - contains 'Conditions_<subsysname>' databases (online daemons)
onldb.starp.bnl.gov:3503 - contains 'RunLog_daq' database (RTS system)
db01.star.bnl.gov:3316/trigger is a special buffer db for FileCatalog migration database
Replication slaves :
onldb2.starp.bnl.gov:3501 (slave of onldb.starp.bnl.gov:3501)
onldb2.starp.bnl.gov:3502 (slave of onldb.starp.bnl.gov:3502)
onldb2.starp.bnl.gov:3503 (slave of onldb.starp.bnl.gov:3503)
.gif)
How-To Online DB Run Preparation
This page contains basic steps only, please see subpages for details on Run preparations!
I. The following paragraphs should be examined *before* the data taking starts:
--- onldb.starp.bnl.gov ---
1. DB: make sure that databases at ports 3501, 3502 and 3503 are running happily. It is useful to check that onldb2.starp, onl10.starp and onl11.starp have replication on and running.
2. COLLECTORS AND RUNLOG DAEMON: onldb.starp contains "old" versions of metadata collectors and RunLogDB daemon. Collector daemons need to be recompiled and started before the "migration" step. One should verify with "caGet <subsystem>.list" command that all EPICS variables are being transmitted and received without problems. Make sure no channels produce "cannot be connected" or "timeout" or "cannot contact IOC" warnings. If they do, please contact Slow Controls expert *before* enabling such service. Also, please keep in mind that RunLogDB daemon will process runs only if all collectors are started and collect meaningful data.
3. FASTOFFLINE: To allow FastOffline processing, please enable cron record which runs migrateDaqFileTags.new.pl script. Inspect that script and make sure that $minRun variable is pointing to some recently taken run or this script will consume extra resource from online db.
4. MONITORING: As soon as collector daemons are started, database monitoring scripts should be enabled. Please see crontabs under 'stardb' and 'staronl' accounts for details. It is recommended to verify that nfs-exported directory on dean is write-accessible.
Typical crontab for 'stardb' account would be like:
*/3 * * * * /home/stardb/check_senders.sh > /dev/null
*/3 * * * * /home/stardb/check_cdev_beam.sh > /dev/null
*/5 * * * * /home/stardb/check_rich_scaler_log.sh > /dev/null
*/5 * * * * /home/stardb/check_daemon_logs.sh > /dev/null
*/15 * * * * /home/stardb/check_missing_sc_data.sh > /dev/null
*/2 * * * * /home/stardb/check_stale_caget.sh > /dev/null
(don't forget to set email address to your own!)
Typical crontab for 'staronl' account would look like:
*/10 * * * * /home/staronl/check_update_db.sh > /dev/null
*/10 * * * * /home/staronl/check_qa_migration.sh > /dev/null
--- onl11.starp.bnl.gov ---
1. MQ: make sure that qpid service is running. This service processes MQ requests for "new" collectors and various signals (like "physics on").
2. DB: make sure that mysql database server at port 3606 is running. This database stores data for mq-based collectors ("new").
3. SERVICE DAEMONS: make sure that mq2memcached (generic service), mq2memcached-rt (signals processing) and mq2db (storage) services are running.
4. COLLECTORS: grab configuration files from cvs, and start cdev2mq and ds2mq collectors. Same common sense rule applies: please check that CDEV and EPICS do serve data on those channels first. Also, collectors may be started at onl10.starp.bnl.gov if onl11.starp is busy with something (unexpected IO stress tests, user analysis jobs, L0 monitoring scripts, etc).
--- onl13.starp.bnl.gov ---
1. MIGRATION: check crontab for 'stardb' user. Mare sure that "old" and "new" collector daemons are really running, before moving further. Verify that migration macros experience no problems by trying some simple migration script. If it breaks saying that library is not found or something - find latest stable (old) version of STAR lib and set it to .cshrc config file. If tests succeed, enable cron jobs for all macros, and verify that logs contain meaningful output (no errors, warnings etc).
--- dean.star.bnl.gov ---
1. PLOTS: Check dbPlots configuration, re-create it as a copy with incremented Run number if neccesary. Subsystem experts tend to check those plots often, so it is better to have dbPlots and mq collectors up and running a little earlier than the rest of services.
2. MONITORING:
- Replication monitor aka Mon (replication should be on for all online servers);
- "old" collection daemon monitor (should be all green, some yellow possible);
- mq-based collectors, by checking "MQ Collectors" tab at Online Control Center (should be all green);
- check IOC monitor, to make sure that no EPICS channels are stuck.
- check physics on/off monitor after the fill, to make sure that CDEV transmits data correctly. If there is no data, then cdev2mq-rt service is not running. If data does not look realistic (shifted/offset timestamps) - please contact CAD, or at least let Jamie Dunlop know about it.
- check dbPlots to see that all collectors are really serving data and there are no delays.
3. RUNLOG - now RunLog browser should display recent runs.
--- db03.star.bnl.gov ---
1. TRIGGER COUNTS check cront tab for root, it should have the following records:
40 5 * * * /root/online_db/cron/fillDaqFileTag.sh
0,10,15,20,25,30,35,40,45,50,55 * * * * /root/online_db/sum_insTrgCnt >> /root/online_db/trgCnt.log
First script copies daqFileTag table from online db to local 'trigger' database. Second script calculates trigger counts for FileCatalog (Lidia). Please make sure that both migration and trigger counting work before you enable it in the crontab. There is no monitoring to enable for this service.
--- dbbak.starp.bnl.gov ---
1. ONLINE BACKUPS: make sure that mysql-zrm is taking backups from onl10.starp.bnl.gov for all three ports. It should take raw backups daily and weekly, and logical backups once per month or so. It is generally recommended to periodically store weekly / monthly backups to HPSS, for long-term archival using /star/data07/dbbackup directory as temporary buffer space.
II. The following paragraphs should be examined *after* the data taking stops:
1. DB MERGE: Online databases from onldb.starp (all three ports) and onl11.starp (port 3606) should be merged into one. Make sure you keep mysql privilege tables from onldb.starp:3501. Do not overwrite it with 3502 or 3503 data. Add privileges allowing read-only access to mq_collector_<bla> tables from onl11.starp:3606 db.
2. DB ARCHIVE PART ONE: copy merged database to dbbak.starp.bnl.gov, and start it with incremented port number. Compress it with mysqlpack, if needed. Don't forget to add 'read-only' option to mysql config. It is generally recommended to put an extra copy to NAS archive, for fast restore if primary drive crashes.
3. DB ARCHIVE PART TWO: archive merged database, and split resulting .tgz file into chunks of ~4-5 GB each. Ship those chunks to HPSS for long-term archival using /star/data07/dbbackup as temporary(!) buffer storage space.
4. STOP MIGRATION macros at onl13.starp.bnl.gov - there is no need to run that during summer shutdown period.
5. STOP trigger count calculations at db03.star.bnl.gov for the reason above.
HOW-TO: access CDEV data (copy of CAD docs)
As of Feb 18th 2011, previously existing content of this page is removed.
If you need to know how to access RHIC or STAR data available through CDEV interface, please read official CDEV documentation here : http://www.cadops.bnl.gov/Controls/doc/usingCdev/remoteAccessCdevData.html
Documentation for CDEV access codes used in Online Data Collector system will be available soon in appropriate section of STAR database documentation.
-D.A.
HOW-TO: compile RunLogDb daemon
- Login to root@onldb.starp.bnl.gov
- Copy latest "/online/production/database/Run_[N]/" directory contents to "/online/production/database/Run_[N+1]/"
- Grep every file and replace "Run_[N]" entrances with "Run_[N+1]" to make sure daemons pick up correct log directories
- $> cd /online/production/database/Run_9/dbSenders/online/Conditions/run
- $> export DAEMON=RunLogDb
- $> make
- /online/production/database/Run_9/dbSenders/bin/RunLogDbDaemon binary should be compiled at this stage
TBC
HOW-TO: create a new Run RunLog browser instance and retire previous RunLog
1. New RunLog browser:
- Copy the contents of the "/var/www/html/RunLogRunX" to "/var/www/html/RunLogRunY", where X is the previous Run ID, and Y is the current Run ID
- Change symlink "/var/www/html/RunLog" pointing to "/var/www/html/RunLogX" to "/var/www/html/RunLogY"
- TBC
2. Retire Previous RunLog browser:
- Grep source files and replace all "onldb.starp : 3501/3503" with "dbbak.starp:340X", where X is the id of the backed online database.
- TrgFiles.php and ScaFiles.php contain reference "/RunLog/", which should be changed to "/RunLogRunX/", where X is the run ID
- TBC
3. Update /admin/navigator.php immediately after /RunLog/ rotation! New run range is required.
HOW-TO: enable Online to Offline migration
Migration macros reside on stardb@onllinux6.starp.bnl.gov .
$> cd dbcron/macros-new/
(you should see no StRoot/StDbLib here, please don't check it out from CVS either - we will use precompiled libs)
First, one should check that Load Balancer config env. variable is NOT set :
$> printenv|grep DB
DB_SERVER_LOCAL_CONFIG=
(if it says =/afs/... .xml, then it should be reset to "" in .cshrc and .login scripts)
Second, let's check that we use stable libraries (newest) :
$> printenv | grep STAR
...
STAR_LEVEL=SL08e
STAR_VERSION=SL08e
...
(SL08e is valid for 2009, NOTE: no DEV here, we don't want to be affected by changed or broken DEV libraries)
OK, initial settings look good, let's try to load Fill_Magnet.C macro (easiest to see if its working or not) :
$> root4star -b -q Fill_Magnet.C
You should see some harsh words from Load Balancer, that's exactly what we need - LB should be disabled for our macros to work. Also, there should not be any segmentation violations. Initial macro run will take some time to process all runs known to date (see RunLog browser for run numbers).
Let's check if we see the entries in database:
$> mysql -h robinson.star.bnl.gov -e "use RunLog_onl; select count(*) from starMagOnl where entryTime > '2009-01-01 00:00:00' " ;
(entryTime should be set to current date)
+----------+
| count(*) |
+----------+
| 1589 |
+----------+
Now, check the run numbers and magnet current with :
$> mysql -h robinson.star.bnl.gov -e "use RunLog_onl; select * from starMagOnl where entryTime > '2009-01-01 00:00:00' order by entryTime desc limit 5" ;
+--------+---------------------+--------+-----------+---------------------+--------+---------+----------+----------+-----------+------------+------------------+
| dataID | entryTime | nodeID | elementID | beginTime | flavor | numRows | schemaID | deactive | runNumber | time | current |
+--------+---------------------+--------+-----------+---------------------+--------+---------+----------+----------+-----------+------------+------------------+
| 66868 | 2009-02-16 10:08:13 | 10 | 0 | 2009-02-15 20:08:00 | ofl | 1 | 1 | 0 | 10046008 | 1234743486 | -4511.1000980000 |
| 66867 | 2009-02-16 10:08:13 | 10 | 0 | 2009-02-15 20:06:26 | ofl | 1 | 1 | 0 | 10046007 | 1234743486 | -4511.1000980000 |
| 66866 | 2009-02-16 10:08:12 | 10 | 0 | 2009-02-15 20:02:42 | ofl | 1 | 1 | 0 | 10046006 | 1234743486 | -4511.1000980000 |
| 66865 | 2009-02-16 10:08:12 | 10 | 0 | 2009-02-15 20:01:39 | ofl | 1 | 1 | 0 | 10046005 | 1234743486 | -4511.1000980000 |
| 66864 | 2009-02-16 10:08:12 | 10 | 0 | 2009-02-15 19:58:20 | ofl | 1 | 1 | 0 | 10046004 | 1234743486 | -4511.1000980000 |
+--------+---------------------+--------+-----------+---------------------+--------+---------+----------+----------+-----------+------------+------------------+
If you see that, you are OK to start cron jobs (see "crontab -l") !
HOW-TO: online databases, scripts and daemons
Online db enclave includes :
primary databases: onldb.starp.bnl.gov, ports : 3501|3502|3503
repl.slaves/hot backup: onldb2.starp.bnl.gov, ports : 3501|3502|3503
read-only online slaves: mq01.starp.bnl.gov, mq02.starp.bnl.gov 3501|3502|3503
trigger database: db01.star.bnl.gov, port 3316, database: trigger
Monitoring:
http://online.star.bnl.gov/Mon/
(scroll down to see online databases. db01 is monitored, it is in offline slave group)
Tasks:
1. Slow Control data collector daemons
$> ssh stardb@onldb.starp.bnl.gov;
$> cd /online/production/database/Run_11/dbSenders;
./bin/ - contains scripts for start/stop daemons
./online/Conditions/ - contains source code for daemons (e.g. ./online/Conditions/run is RunLogDb)
See crontab for monitoring scripts (protected by lockfiles)
Monitoring page :
http://online.star.bnl.gov/admin/daemons/
2. Online to Online migration
- RunLogDb daemon performs online->online migration. See previous paragraph for details (it is one of the collector daemons, because it shares the source code and build system). Monitoring: same page as for data collectors daemons;
- migrateDaqFileTags.pl perl script moves data from onldb.starp:3503/RunLog_daq/daqFileTag to onldb.starp:3501/RunLog/daqFileTag table (cron-based). This script is essential for OfflineQA, so RunLog/daqFileTag table needs to be checked to ensure proper OfflineQA status.
3. RunLog fix script
$> ssh root@db01.star.bnl.gov;
$> cd online_db;
sum_insTrgCnt is the binary to perform various activities per recorded run, and it is run as cron script (see crontab -l).
4. Trigger data migration
$> ssh root@db01.star.bnl.gov
/root/online_db/cron/fillDaqFileTag.sh <- cron script to perform copy from online trigger database to db01
BACKUP FOR TRIGGER CODE:
1. alpha.star.bnl.gov:/root/backups/db01.star.bnl.gov/root
2. bogart.star.bnl.gov:/root/backups/db01.star.bnl.gov/root
5. Online to Offline migration
$> ssh stardb@onl13.starp.bnl.gov;
$> cd dbcron/macros-new; ls;
Fill*.C macros are the online->offline migration macros. There is no need in local/modified copy of the DB API, all macros use regular STAR libraries (see tcsh init scripts for details)
Macros are cron jobs. See cron for details (crontab -l). Macros are lockfile-protected to avoid overlap/pileup of cron jobs.
Monitoring :
http://online.star.bnl.gov/admin/status/
MQ-based Online API
MQ-based Online API
Intro
New Online API proposal: Message-Queue-based data exchange for STAR Online domain;
Purpose
Primary idea is to replace current DB-centric STAR Online system with industrial-strength Message Queueing service. Online databases will, then, take a proper data storage role, leaving information exchange to MQ server. STAR, as an experiment in-progress, is still growing every year, so standard information exchange protocol is required for all involved parties to enable efficient cross-communications.
It is proposed to leave EPICS system as it is now for Slow Controls part of Online domain, and allow easy data export from EPICS to MQ via specialized epics2mq services. Further, data will be stored to MySQL (or some other storage engine) via mq2db service(s). Clients could retrieve archived detector conditions either via direct MySQL access as it is now, or through properly formatted request to db2mq service.
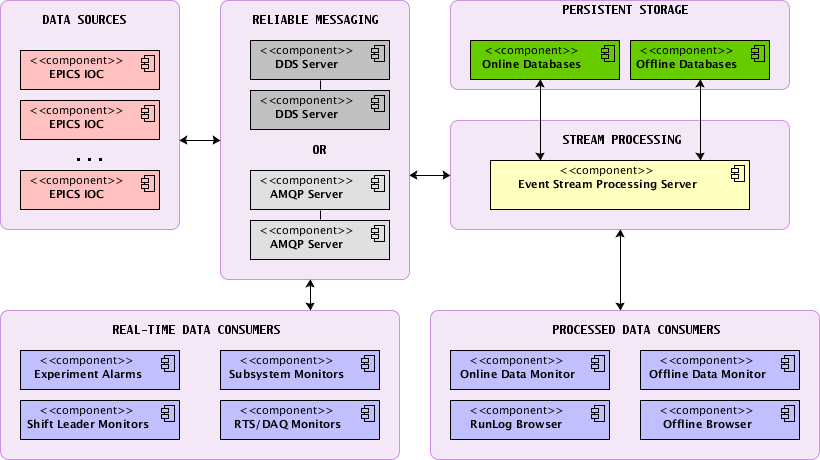
[introduction-talk] [implementation-talk]
Primary components
- qpid: AMQP 0.10 server [src rpm] ("qpid-cpp-mrg" package, not the older "qpidc" one);
- python-qpid : python bindings to AMQP [src rpm] (0.7 version or newer);
- Google Protobuf: efficient cross-language, cross-platform serialization/deserialization library [src rpm];
- EPICS: Experimental Physics and Industrial Control System [rpm];
- log4cxx: C++ implementation of highly successful log4j library standard [src rpm];
Implementation
- epics2mq : service, which queries EPICS via EasyCA API, and submits Protobuf-encoded results to AMQP server;
- mq2db : service, which listens to AMQP storage queue for incoming Protobuf-encoded data, decodes it and stores it to MySQL (or some other backend db);
- db2mq : service, which listens to AMQP requests queue, queries backend database for data, encodes it in Protobuf format and send it to requestor;
- db2mq-client : example of client program for db2mq service (requests some info from db);
- mq-publisher-example : minimalistic example on how to publish Protobuf-encoded messages to AMQP server
- mq-subscriber-example : minimalistic example on how to subscribe to AMQP server queue, receive and decode Protobuf messages
Use-Cases
- STAR Conditions database population: epics2mq -> MQ -> mq2db; db2mq -> MQ -> db2mq-client;
- Data exchange between Online users: mq-publisher -> MQ -> mq-subscriber;
How-To: simple usage example
- login to [your_login_name]@onl11.starp.bnl.gov ;
- checkout mq-publisher-example and mq-subscriber-example from STAR CVS (see links above);
- compile both examples by typing "make" ;
- start both services, in either order. obviously, there's no dependency on publisher/subscriber start order - they are independent;
- watch log messages, read code, modify to your needs!
How-To: store EPICS channels to Online DB
- login to onl11.starp.bnl.gov;
- checkout epics2mq service from STAR CVS and compile it with "make";
- modify epics2mq-converter.ini - set proper storage path string, add desired epics channel names;
- run epics2mq-service as service: "nohup ./epics2mq-service epics2mq-converter.ini >& out.log &"
- watch new database, table and records arriving to Online DB - mq2db will automatically accept messages and create appropriate database structures!
How-To: read archived EPICS channel values from Online DB
- login to onl11.starp.bnl.gov;
- checkout db2mq-client from STAR CVS, compile with "make";
- modify db2mq-client code to your needs, or copy relevant parts into your project;
- enjoy!
MQ Monitoring
QPID server monitoring hints
To see what service is connected to our MQ server, one should use qpid-stat. Example:
$> qpid-stat -c -S cproc -I localhost:5672 Connections client-addr cproc cpid auth connected idle msgIn msgOut ======================================================================================================== 127.0.0.1:54484 db2mq-service 9729 anonymous 2d 1h 44m 1s 2d 1h 39m 52s 29 0 127.0.0.1:56594 epics2mq-servic 31245 anonymous 5d 22h 39m 51s 4m 30s 5.15k 0 127.0.0.1:58283 epics2mq-servic 30965 anonymous 5d 22h 45m 50s 30s 5.16k 0 127.0.0.1:58281 epics2mq-servic 30813 anonymous 5d 22h 49m 18s 4m 0s 5.16k 0 127.0.0.1:55579 epics2mq-servic 28919 anonymous 5d 23h 56m 25s 1m 10s 5.20k 0 130.199.60.101:34822 epics2mq-servic 19668 anonymous 2d 1h 34m 36s 10s 17.9k 0 127.0.0.1:43400 mq2db-service 28586 anonymous 6d 0h 2m 38s 10s 25.7k 0 127.0.0.1:38496 qpid-stat 28995 guest@QPID 0s 0s 108 0
MQ Routing
QPID server routing (slave mq servers) configuration
MQ routing allows to forward selected messages to remote MQ servers.
$> qpid-route -v route add onl10.starp.bnl.gov:5672 onl11.starp.bnl.gov:5672 amq.topic gov.bnl.star.#
$> qpid-route -v route add onl10.starp.bnl.gov:5672 onl11.starp.bnl.gov:5672 amq.direct gov.bnl.star.#
$> qpid-route -v route add onl10.starp.bnl.gov:5672 onl11.starp.bnl.gov:5672 qpid.management console.event.#
ORBITED automatic startup fix for RHEL5
HOW TO FIX "ORBITED DOES NOT LISTEN TO PORT XYZ" issue
/etc/init.d/orbited needs to be corrected, because --daemon option does not work for RHEL5 (orbited does not listen to desired port). Here what is needed:
Edit /etc/init.d/orbited and :
1. add
ORBITED="nohup /usr/bin/orbited > /dev/null 2>&1 &"
to the very beginning of the script, just below "lockfile=<bla>" line
2. modify "start" subroutine to use $ORBITED variable instead of --daemon switch. It should look like this :
daemon --check $prog $ORBITED
Enjoy your *working* "/sbin/service/orbited start" command ! Functionality could be verified by trying lsof -i :[your desired port], (e.g. ":9000") - it should display "orbited"
Online Recipes
- Restore RunLog Browser
- Restore Migration Code
- Restore Online Daemons
MySQL trigger for oversubscription protection
How-to enable total oversubscription check for Shift Signup (mysql trigger) :
delimiter |
CREATE TRIGGER stop_oversubscription_handler BEFORE INSERT ON Shifts
FOR EACH ROW BEGIN
SET @insert_failed := "";
SET @shifts_required := (SELECT shifts_required FROM ShiftAdmin WHERE institution_id = NEW.institution_id);
SET @shifts_exist := (SELECT COUNT(*) FROM Shifts WHERE institution_id = NEW.institution_id);
IF ( (@shifts_exist+1) >= (@shifts_required * 1.15)) THEN
SET @insert_failed := "oversubscription protection error";
SET NEW.beginTime := null;
SET NEW.endTime := null;
SET NEW.week := null;
SET NEW.shiftNumber := null;
SET NEW.shiftTypeID := null;
SET NEW.duplicate := null;
END IF;
END;
|
delimiter ;
Restore Migration Macros
The Migration Macros are monitored here, if they have stopped the page will display values in red.
- Call Database Expert 356-2257
- Log onto onlinux6.starp.bnl.gov - as stardb: Ask Michael, Wayne, Gene, Jerome for password
- check for runaway processes - for example, these are run as crons so a process starts before its previous exectution finishes, the process never ends and they build up
- If this is the case kill each of the processes
- cd to dbcron
Restore RunLog Browser
If the Run Log Browser is not Updating...
- make sure all options are selected and deselect "filter bad"
often - people will complain about missing runs and they are just not selected - Call DB EXPERT: 349-2257
- Check onldb.star.bnl.gov
- log onto node as stardb (password known by Michael, Wayne, Jerome, Gene)
- df -k ( make sure a disk did not fill) - If it did: cd into the appropriate data directory
(i.e. /mysqldata00/Run_7/port_3501/mysql/data) and copy /dev/null into the large log file onldb.starp.bnl.gov.log
`cp /dev/null > onldb.starp.bnl.gov.log` - make sure back-end runlog DAEMON is running
- execute /online/production/database/Run_7/dbSenders/bin/runWrite.sh status
Running should be returned - restart deamon - execute /online/production/database/Run_7/dbSenders/bin/runWrite.sh start
Running should be returned - if Not Running is returned there is a problem with the code or with daq
- contact DAQ expert to check their DB sender system
- refer to the next section below as to debugging/modifying recompiling code
- execute /online/production/database/Run_7/dbSenders/bin/runWrite.sh status
- Make sure Database is running
- mysql -S /tmp/mysql.3501.sock
- To restart db
- cd to /online/production/database/config
- execute `mysql5.production start 3501`
- try to connect
- debug/modify Daemon Code (be careful and log everything you do)
- check log file at /online/production/database/Run_7/dbSenders/run this may point to an obvious problem
- Source code is located in /online/production/database/Run_7/dbSenders/online/Condition/run
- GDB is not Available usless the code is recompiled NOT as a daemon
- COPY Makefile_debug to Makefile (remember to copy Makefile_good back to Makefile when finished)
- setenv DAEMON RunLogSender
- make
- executable is at /online/production/database/Run_7/dbSenders/bin
- gdb RunLog
Online Server Port Map
Below is a port/node mapping for the online databases both Current and Archival
Archival
| Run/Year | NODE | Port |
| Run 1 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3400 |
| Run 2 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3401 |
| Run 3 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3402 |
| Run 4 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3403 |
| Run 5 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3404 |
| Run 6 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3405 |
| Run 7 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3406 |
| Run 8 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3407 |
| Run 9 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3408 |
| Run 10 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3409 |
| Run 11 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3410 |
| Run 12 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3411 |
| Run 13 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3412 |
| Run 14 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3413 |
| Run 15 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3414 |
| Run 16 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3415 |
| Run 17 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3416 |
| Run 18 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3417 |
| Run 19 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3418 |
| Run 20 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3419 |
| Run 21 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3420 |
| Run 22 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3421 |
| Run 23 | dbbak.starp.bnl.gov / db04.star.bnl.gov | 3422 |
CURRENT (RUN 24)
| DATABASE | NODE | Port |
| [MASTER] Run Log, Conditions_rts, Shift Signup, Shift Log | onldb.starp.bnl.gov | 3501 |
| [MASTER] Conditions | onldb.starp.bnl.gov | 3502 |
| [MASTER] Daq Tag Tables | onldb.starp.bnl.gov | 3503 |
| [SLAVE] Run Log, Conditions_rts, Shift Signup, Shift Log | onldb2.starp.bnl.gov onldb3.starp.bnl.gov onldb4.starp.bnl.gov mq01.starp.bnl.gov mq02.starp.bnl.gov |
3501 |
| [SLAVE] Conditions | onldb2.starp.bnl.gov onldb3.starp.bnl.gov onldb4.starp.bnl.gov mq01.starp.bnl.gov mq02.starp.bnl.gov |
3502 |
| [SLAVE] Daq Tag Tables | onldb2.starp.bnl.gov onldb3.starp.bnl.gov onldb4.starp.bnl.gov mq01.starp.bnl.gov mq02.starp.bnl.gov |
3503 |
| [MASTER] MQ Conditions DB | mq01.starp.bnl.gov | 3606 |
| [SLAVE] MQ Conditions DB | mq02.starp.bnl.gov onldb2.starp.bnl.gov onldb3.starp.bnl.gov onldb4.starp.bnl.gov |
3606 |
| RTS Database (MongoDB cluster) | mongodev01.starp.bnl.gov mongodev02.starp.bnl.gov mongodev03.starp.bnl.gov |
27017 |
End of the run procedures:
1. Freeze databases (especially ShiftSignup on 3501) by creating a new db instance on the next sequential port from the archival series and copy all dbs from all three ports to this port.
2. Move the previous run to dbbak.starp
3. Send email announcing the creation of this port, so web pages can be changed.
4. Tar/zip the directories and ship them to HPSS.
Prior to the next Run:
1. Clear out the dbs on the "current" ports. NOTE: do not clear out overhead tables (e.g., Nodes, NodeRelations, blahIDs etc.). There is a script on onldb /online/production/databases/createTables which does this. Make sure you read the README.
UPDATE: more advanced script to flush db ports is attached to this page (chdb.sh). Existing " createPort350X.sql " files do not care about overhead tables!
UPDATE.v2: RunLog.runTypes & RunLog.detectorTypes should not be cleared too // D.A.
UPDATE.V3: RunLog.destinationTypes should not be cleared // D.A.
Confirm all firewall issues are resolved from both the IP TABLES on the local host and from an institutional networking perspective. This should only really need to be addressed with a new node, but it is good to confirm prior to advertising availability.
Update the above tables.
2. Verify that Online/Offline Detector ID list matches to RunLog list (table in RunLog db) :
http://www.star.bnl.gov/cgi-bin/protected/cvsweb.cgi/StRoot/RTS/include/rtsSystems.h
Online to Offline migration monitoring
ONLINE TO OFFLINE MIGRATION
online.star.bnl.gov/admin/status.php
If all entries are red - chances are we are not running - or there is a
gap between runs e.g., a beam dump.
In this case please check the last run and or/time with the RunLog or
Shift Log to confirm that the last run was migrated (This was most
likely the case last night).
If one entry is red - please be sure that the latest value is _recent_
as some dbs are filled by hand once a year.
So we have a problem if ....
If an entry is red, other values are green, the of the red last value
was recent.
All values are red and you know we have been taking data for more than
.75 hours, This a rough estimate of time, but keep in mind migration of
each db happens at different time intervals so entries won't turn red
all at once nor will they turn green all at once. In fact RICH scalars
only get moved once an hour so it will not be uncommon to see this red
for a while after we just start taking data.
code is on stardb@onl13.starp.bnl.gov (formerly was on onllinux6.starp):
~/stardb/dbcron/macrcos
Below is an output of cron tab to start the processes uncomment the crons in stardbs cron tab
Times of transfers are as follows:
1,41 * * * * TpcGas
0,15,30,45 * * * * Clock
5,20,35,50 * * * * RDO
10,40 * * * * FTPCGAS
15 * * * * FTPCGASOUT
0,30 * * * * Trigger
25 * * * * TriggerPS
10,40 * * * * BeamInfo
15 * * * * Magnet
3,23,43 * * * * MagFactor
45 * * * * RichScalers
8,24,44 * * * * L0Trigger
6,18,32,48 * * * * FTPCVOLTAGE
10,35,50 * * * * FTPCTemps
check the log file in ../log to make sure the crons are moving data.
Backups of migration scripts and crontab are located here :
1. alpha.star.bnl.gov:/root/backups/onl13.starp.bnl.gov/dbuser
2. bogart.star.bnl.gov:/root/backups/onl13.starp.bnl.gov/dbuser
Standard caGet vs improved caGet comparison
Standard caGet vs. improved caGet comparison
here is my summary of caget's performance studies done yesterday+today : 1. Right now, "normal" (sequential mode) caget from CaTools package takes 0.25 sec to fetch 400 channels, and, according to callgrind, it could be made even faster if I optimize various printf calls (40% speedup possible, see callgrind tree dump) : http://www.star.bnl.gov/~dmitry/tmp/caget_sequential.png [Valgrind memcheck reports 910kb RAM used, no memory leaks] 2. At the same time, "bulk" (parallel mode) caget from EzcaScan package takes 13 seconds to fetch same 400 channels. Here is a callgrind tree again: http://www.star.bnl.gov/~dmitry/tmp/caget_parallel.png [Valgrind memcheck reports 970kb RAM used, no memory leaks] For "parallel" caget, most of the time is spent on Ezca_getTypeCount, and Ezca_pvlist_search. I tried all possible command-line options available for this caget, with same result. This makes me believe that caget from EzcaScan package is even less optimized in terms of performance. It could be better optimized in terms of network usage, though (otherwise those guys won't even mention "improvement over regular caget" in their docs). Another thing is that current sequential caget is *possibly* using same "bulk" mode internally (that "ca_array_get" function is seen for both cagets).. Oh, if this matters, for this test I used EPICS base 3.14.8 + latest version of EzcaScan package recompiled with no/max optimizations in gcc.
Offline Databases
Offline Databases
Offline databases are :
robinson.star.bnl.gov:3306 - master database
All hosts below are replication slaves.
db16.star.bnl.gov:3316 - production group nodes
db17.star.bnl.gov:3316
db11.star.bnl.gov:3316
db12.star.bnl.gov:3316 - user node pool
db15.star.bnl.gov:3316
db18.star.bnl.gov:3316
db06.star.bnl.gov:3316
db07.star.bnl.gov:3316 - these hosts belong to dbx.star.bnl.gov RR
db08.star.bnl.gov:3316 (visible to users, external to BNL)
db10.star.bnl.gov:3316
db13.star.bnl.gov:3316 - expert user pool
db14.star.bnl.gov:3316
db03.star.bnl.gov:3316 - online 2 offline buffer node
Database Snapshot Factory
STAR Offline Database Snapshot Factory
Snapshot factory consists of three scripts (bash+php), located at omega.star.bnl.gov. Those scripts are attached to cron, so snapshots are produced four times per day at 6:00, 12:00, 18:00, 24:00 respectively. Those snapshots are exposed to outer world by special script, located at STAR web server (orion), which allows single-stream downloads of snapshot archive file (lock-file protection) to avoid www overload.
Details
1. omega.star.bnl.gov :
- primary script is /db01/offline_snapshot_copy/scripts/run, which is started four times per day by /etc/cron.d/db-snapshot.sh cron rule;
- resulting file is copied to /var/www/html/factory/snapshot-2010.tgz, to be served to orion via http means;
- each (un)successful snapshot run sends an email to arkhipkin@bnl.gov, so database administrator is always aware on how things are going;
- run script is protected against multiple running instances (lock file + bash signal traps), thus preventing build-up of failed script instances at omega;
2. orion.star.bnl.gov :
- snapshot download script is located at /var/www/html/dsfactory/tmp/get_snapshot.sh, which is started every hour by /etc/cron.d/db-snapshot-factory cron rule;
- get_snapshot.sh is also protected against multiple running instances, + it will not download same file twice (if no changes since last download), thus conserving network traffic and keepin node load low;
- resulting file - actual database snapshot - could be accessed at http://drupal.star.bnl.gov/dsfactory/ link, which has internal protection against multiple downloads: only 1 download stream is allowed, other clients will receive HTTP 503 error, accompanied by explanations message (busy);
Recommended way to download snapshots
The following bash script could be used to safely download database snapshot :
#!/bin/bash
#
# Database snapshot download script (omega to orion)
# If you need help with this script, please contact
# "Dmitry Arkhipkin" <arkhipkin@bnl.gov>
#
set -u
set +e
# defaults
lockfile=/tmp/db-snapshot-factory.lock
EMAILMESSAGE=/tmp/emailmessage.txt
DOWNLOAD_DIR=http://www.star.bnl.gov/dsfactory
DOWNLOAD_FILE=snapshot-2010.tgz
LOCAL_DIR=/tmp/dsfactory
LOCAL_TMP_DIR=/tmp/dsfactory/tmp
LOCAL_NAME=db-snapshot-2010.tgz
SUBJECT="gridified database snapshot 2010 download completed"
EMAIL=arkhipkin@bnl.gov
if ( set -o noclobber; echo "$$" > "$lockfile") 2> /dev/null;
then
trap '/bin/rm -f "$lockfile"; exit $?' INT TERM EXIT
# protected area starts here :
cd $LOCAL_TMP_DIR
echo "This is an automated email message, please do not reply to it!" > $EMAILMESSAGE
START=$(date +%s)
echo "*** database snapshot update started at" `date` >> $EMAILMESSAGE
# Attempt to download the file. --progress=dot:mega is used to prevent
# WGET_OUTPUT from getting too long.
WGET_OUTPUT=$(2>&1 wget -O $DOWNLOAD_FILE --timestamping --progress=dot:mega \
"$DOWNLOAD_DIR/")
# Make sure the download went okay.
if [ $? -ne 0 ]
then
# wget had problems.
# send "FAILED" notification email
echo "*** wget output: $WGET_OUTPUT" >> $EMAILMESSAGE
SUBJECT="gridified database snapshot 2010 download FAILED"
/bin/mail -s "$SUBJECT" "$EMAIL" < $EMAILMESSAGE
echo 1>&2 $0: "$WGET_OUTPUT" Exiting.
exit 1
fi
# Copy the file to the new name if necessary.
if echo "$WGET_OUTPUT" | /bin/fgrep 'saved' &> /dev/null
then
/bin/cp -f "$LOCAL_TMP_DIR/$DOWNLOAD_FILE" "$LOCAL_DIR/$LOCAL_NAME"
# calculate time
END=$(date +%s)
DIFF=$(( $END - $START ))
HRS=$(( $DIFF / 3600 ))
MNT=$(( $DIFF % 3600 / 60 ))
SEC=$(( $DIFF % 3600 % 60 ))
echo "*** database snapshot download took $HRS:$MNT:$SEC HH:MM:SS to complete (TOTAL: $DIFF seconds)" >> $EMAILMESSAGE
# send "SUCCESSFUL" notification email
echo "*** database snapshot $LOCAL_NAME successfully updated." >> $EMAILMESSAGE
/bin/mail -s "$SUBJECT" "$EMAIL" < $EMAILMESSAGE
else
echo "!!! database snapshot $LOCAL_NAME does not need to be updated - same file." >> $EMAILMESSAGE
fi
# end of protected area
/bin/rm -f "$lockfile"
trap - INT TERM EXIT
else
echo "Failed to acquire lockfile: $lockfile."
echo "Held by $(cat $lockfile)"
fi
# end of scriptPerformance testing'13
I. Intro
Three nodes tested: my own laptop with home-quality SSD drive, reserve1.starp.bnl.gov (old db node), db04.star.bnl.gov (new node).
II. hdparm results:
extremely basic test of sequential read - baseline and sanity check [passed]
1. Dmitry's laptop (SSD):
/dev/disk/by-uuid/88ba7100-0622-41e9-ac89-fd8772524d65:
Timing cached reads: 1960 MB in 2.00 seconds = 980.43 MB/sec
Timing buffered disk reads: 532 MB in 3.01 seconds = 177.01 MB/sec
2. reserve1.starp.bnl.gov (old node):
/dev/md1:
Timing cached reads: 2636 MB in 2.00 seconds = 1317.41 MB/sec
Timing buffered disk reads: 252 MB in 3.02 seconds = 83.34 MB/sec
3. db04.star.bnl.gov (new node):
/dev/disk/by-uuid/53f45841-0907-41a0-bfa3-52cd269fdfb6:
Timing cached reads: 5934 MB in 2.00 seconds = 2969.24 MB/sec
Timing buffered disk reads: 884 MB in 3.00 seconds = 294.19 MB/sec
III. MySQL bench test results: test suite to perform "global" health check, without any particular focus, single thread..
1. laptop:
connect: Total time: 113 wallclock secs (44.75 usr 16.29 sys + 0.00 cusr 0.00 csys = 61.04 CPU)
create: Total time: 221 wallclock secs ( 7.22 usr 1.96 sys + 0.00 cusr 0.00 csys = 9.18 CPU)
insert: Total time: 894 wallclock secs (365.51 usr 64.07 sys + 0.00 cusr 0.00 csys = 429.58 CPU)
select: Total time: 240 wallclock secs (33.26 usr 3.86 sys + 0.00 cusr 0.00 csys = 37.12 CPU)
2. reserve1.starp.bnl.gov:
connect: Total time: 107 wallclock secs (44.85 usr 14.88 sys + 0.00 cusr 0.00 csys = 59.73 CPU)
create: Total time: 750 wallclock secs ( 6.37 usr 1.52 sys + 0.00 cusr 0.00 csys = 7.89 CPU)
insert: Total time: 1658 wallclock secs (378.28 usr 47.53 sys + 0.00 cusr 0.00 csys = 425.81 CPU)
select: Total time: 438 wallclock secs (48.92 usr 4.50 sys + 0.00 cusr 0.00 csys = 53.42 CPU)
3. db04.star.bnl.gov:
connect: Total time: 54 wallclock secs (18.63 usr 11.44 sys + 0.00 cusr 0.00 csys = 30.07 CPU)
create: Total time: 1375 wallclock secs ( 1.94 usr 0.91 sys + 0.00 cusr 0.00 csys = 2.85 CPU) [what's this??]
insert: Total time: 470 wallclock secs (172.41 usr 31.71 sys + 0.00 cusr 0.00 csys = 204.12 CPU)
select: Total time: 185 wallclock secs (16.66 usr 2.00 sys + 0.00 cusr 0.00 csys = 18.66 CPU)
IV. SysBench IO test results: random reads, small block size, many parallel threads
 t
t
est


DB05.star.bnl.gov, with "noatime" option:
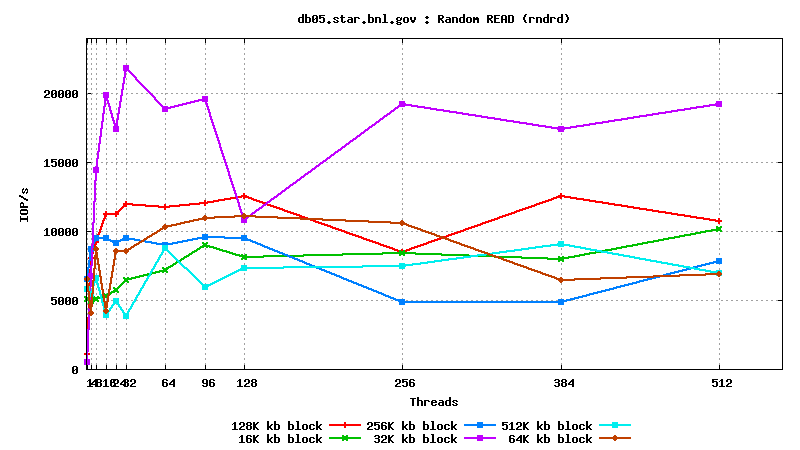

V. SysBench SQL test results: synthetic read-only
Interestingly, new system beats old one by a factor of x7 up to 128 clients, and is only marginally better at 128+ parallel threads..
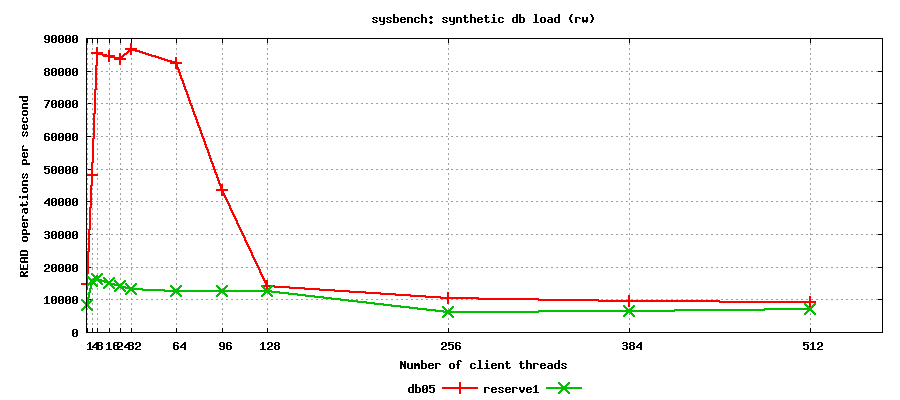
V. STAR production chain testing (nightly test BFC):
Test setup:
- auau200, pp200, pp500 x 10 jobs each, run using db05 (new node) and db10 (old node, equivalent to reserve1.starp);
- jobs run in a single-user mode: one job at a time;
- every server was tested in two modes: query cache ON, and query cache OFF (cache reset between tests);
- database maker statistics was collected for analysis;
RESULTS:
auau200, old -> new :
qc_off: Ast = 2.93 -> 2.79 (0.1% -> 0.1%), Cpu = 0.90 -> 1.15 (0% -> 0%)
qc_on : Ast = 2.45 -> 2.26 (0.1% -> 0.1%), Cpu = 0.88 -> 0.86 (0% -> 0%)
pp200, old -> new :
qc_off: Ast = 2.72 -> 6.49 (5.59% -> 10.04%), Cpu = 0.56 -> 0.86 (1.36% -> 1.83%)
qc_on : Ast = 2.24 -> 3.20 (4.90% -> 6.49%), Cpu = 0.60 -> 0.55 (1.46% -> 1.32%)
pp500, old -> new:
qc_off: Ast = 2.65 -> 2.41 (15.9% -> 15.4%), Cpu = 0.55 -> 0.79 (5.05% -> 6.2%)
qc_on : Ast = 2.09 -> 1.94 (13.8% -> 14.8%), Cpu = 0.53 -> 0.53 (4.87% -> 4.88%)
Summary for this test:
- as expected, databases with query cache enabled were processing requests faster than databases;
- new node (having query cache on) is performing at the level very similar to old node, difference is not noticable/significant within test margins;
Additional studies: db11 (very new node):
![]()
FileCatalog Databases
FileCatalog databases
Current Filecatalog databases are :
fc1.star.bnl.gov:3336 - this is FC master database server
fc2.star.bnl.gov:3336 - FC slave
fc4.star.bnl.gov:3336 - FC slave
fc3.star.bnl.gov:3336 - DB backup node, also there is a Tomcat serving Logger db interface (portal?)
Multi-master setup, BNL-PDSF
Current multi-master FC setup scheme:
- one master server at BNL + two local slaves attached to it;
- one master server at PDSF + one local slave attached to it;
- both BNL FC master and PDSF FC master are slaves to each other;
BNL master : fc1.star.bnl.gov:3336
PDSF master : pdsfdb05.nersc.gov:3336
MySQL config details :
- BNL master has the following extra lines in my.cnf
- auto_increment_increment = 10
- auto_increment_offset = 1
- log-bin = mysql.bin
- log-slave-updates
- expire_logs_days = 7
- binlog-ignore-db = mysql
- binlog-ignore-db = test
- PDSF master has the following extra lines in my.cnf
- auto_increment_increment = 10
- auto_increment_offset = 2
- log-bin = mysql.bin
- log-slave-updates
- expire_logs_days = 7
- binlog-ignore-db = mysql
- binlog-ignore-db = test
All local slaves should have "read-only" parameter in my.cnf to avoid occasional writes to slaves.
Privileged user, for replication :
BNL:
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* to 'fcrepl'@'%.nersc.gov' IDENTIFIED BY 'starreplica';
FLUSH PRIVILEGES;
PDSF:
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* to 'fcrepl'@'%.bnl.gov' IDENTIFIED BY 'starreplica';
FLUSH PRIVILEGES;
server-id: at STAR, we assign mysql server id using the following scheme: [xx.yy].[port number], where xx.yy is the last half of server IP address. So, for server running at [ip-130.100.23.45]:[port-3306], server id is "23453306".
SETUP PROCESS FOR LBNL
- copy FC snapshot from dbuser@alpha.star.bnl.gov:/db01/zrm-backup/daily-fc-logical/20091015135118/ to pdsf;
- install mysql 5.0.77 and equip it with /etc/init.d/mysqld_multi script (see attached file);
- configure my.cnf for one master running at port 3336, and one slave running at port 3306 (example my.cnf is attached). Don't forget to change server-id to some other unique numeric id - it should not overlap with existing STAR ids;
- start master at pdsfdb05.nersc.gov:3336 (command: "service mysqld_multi start 3336"), and load snapshot .sql file; DO NOT START SLAVE MODE YET!
- grant privileges to BNL/local replication user (fcrepl, see above);
- issue "GRANT SHUTDOWN ON *.* TO 'myadmin'@'localhost' IDENTIFIED BY PASSWORD '*20843655CB400AA52C42FF5552B9BA26DE401B4B' " to enable automatic mysqld_multi script access;
- start slave at pdsfdb05.nersc.gov:3306, and load same snapshot .sql file, run "CHANGE MASTER TO <bla>" to setup LOCAL replication process using same "fcrepl" user;
- issue "GRANT SHUTDOWN ON *.* TO 'myadmin'@'localhost' IDENTIFIED BY PASSWORD '*20843655CB400AA52C42FF5552B9BA26DE401B4B' ";
- start local replication and check its state with "SHOW SLAVE STATUS\G" command;
- start BNL->PDSF replication on master, check its state with "SHOW SLAVE STATUS\G" command;
- stop replication ("STOP SLAVE"), and send results of "SHOW MASTER STATUS" command to Dmitry.
Software Infrastructure Databases
There are several applications in STAR, which use databases as back-end. Those databases are not directly related to data analysis. They serve specific purpose like monitoring, logging or keep content management system data (dynamic web page content).
Currently we have :
orion.star.bnl.gov:3306 - Drupal CMS database;
orion.star.bnl.gov:3346 - SSH Key Management System database;
heston.star.bnl.gov:3306 - Logger, Nova databases;
alpha.star.bnl.gov - central node for various db-related service tasks: mysql-zrm backups, monitoring;
omega.star.bnl.gov - FileCatalog slave at port 3336, Offline slave at port 3316, both attached to ZRM backup system;
Maintenance
Database maintenance tasks: monitoring, backup, upgrades, performance issues, server list etc...
Backups
<placeholder> Describes STAR's database backup system. </placeholder>
Sept. 5, 2008, WB -- seeing no documentation here, I am going to "blog" some as I go through dbbak to clean up from a full disk and restore the backups. (For the full disk problem, see http://www.star.bnl.gov/rt2/Ticket/Display.html?id=1280 .) I expect to get the details in and then come back to clean it up...
dbbak.starp.bnl.gov has Perl scripts running in cron jobs to get mysql dumps of nearly all of STAR's databases and store them on a daily basis. The four nightly (cron) backup scripts are attached (as of Nov. 24, 2008).
The scripts keep the last 10 dumps in /backups/dbBackups/{conditions,drupal,duvall,robinson,run}. Additionally, on the 1st and 15th of each month, the backups are put in "old" directories within each respective backup folder.
The plan of action as Mike left it was to, once or twice each year, move the "old" folders to RCF and from there put them into HPSS (apparently into his own HPSS space)
We have decided to revive the stardb RCF account and store the archives via that account. /star/data07/db has been suggested as the temporary holding spot, so we have a two-step sequence like this:
- As stardb on an rcas node, scp the "old" directories to /star/data07/db/<name>
- Use htar to tar each "old" directory and store in HPSS.
Well, that's "a" plan anyway. Other plans have been mentioned, but this is what I'm going to try first. Let's see how it goes in reality...
- Login to an interactive rcas node as stardb (several possible ways to do this - for this manual run, I login to rssh as myself, then ssh to stardb@rcas60XX . I added my ssh key to the stardb authorized_keys file, so no password is required, even for the scp from dbbak.)
- oops, first problem -- /star/data07/db/ is owned by deph and does not have group or world write permission, so "mkdir /star/data07/db_backup_temp" then make five subdirectories (conditions, drupal, duvall, robinson, run)
- [rcas6008] ~/> scp -rp root@dbbak.starp.bnl.gov:/backups/dbBackups/drupal/old /star/data07/db_backup_temp/drupal/
- [rcas6008] /star/data07/db_backup_temp/> htar -c -f dbbak_htars/drupal.09_05_2008 drupal/old
- Do a little dance for joy, because the output is: "HTAR: HTAR SUCCESSFUL"
- Verify with hsi: [rcas6008] /star/data07/db_backup_temp/> hsi
Username: stardb UID: 3239 CC: 3239 Copies: 1 [hsi.3.3.5 Tue Sep 11 19:31:24 EDT 2007]
? ls
/home/stardb:
drupal.09_05_2008 drupal.09_05_2008.index
? ls -l
/home/stardb:
-rw------- 1 stardb star 495516160 Sep 5 19:37 drupal.09_05_2008
-rw------- 1 stardb star 99104 Sep 5 19:37 drupal.09_05_2008.index
- So far so good. Repeat for the other 4 database bunches (which are a couple of orders of magnitude bigger)
Update, Sept. 18, 2008:
This was going fine until the last batch (the "run" databases). Attempting to htar "run/old" resulted in an error:
[rcas6008] /star/data07/db_backup_temp/> htar -c -f dbbak_htars/run.09_16_2008 run/old
ERROR: Error -22 on hpss_Open (create) for dbbak_htars/run.09_16_2008
HTAR: HTAR FAILED
I determined this to be a limit in *OUR* HPSS configuration - there is a 60GB max file size limit, which the run databases were exceeding at 87GB. Another limit to be aware of, however, is an 8GB limit on member files ( see the "File Size" bullet here: https://computing.llnl.gov/LCdocs/htar/index.jsp?show=s2.3 -- though this restriction was removed in versions of htar after Sept. 10, 2007 ( see the changelog here: https://computing.llnl.gov/LCdocs/htar/index.jsp?show=s99.4 ), HTAR on the rcas node is no newer than August 2007, so I believe this limit is present.)
There was in fact one file exceeding 8 GB in these backups (RunLog-20071101.sql.gz, at 13 GB). I used hsi to put this file individually into HPSS (with no tarring).
Then I archived the run database backups piecemeal. All in all, this makes a small mess of the structure and naming convention. It could be improved, but for now, here is the explanation:
| HPSS file (relative to /home/stardb) | Corresponding dbbak path (relative to /backups/dbBackups ) | Description | single file or tarball? |
| dbbak_htars/conditions.09_08_2008 | conditions/old/ | twice monthly conditions database backups (Jan. - Aug. 2008) | tarball |
| dbbak_htars/drupal.09_05_2008 | drupal/old | twice monthly drupal database backups (Nov. 2007 - Aug. 2008) | tarball |
| dbbak_htars/duvall.09_13_2008 | duvall/old | twice monthly duvall database backups (Jan. - Aug. 2008) | tarball |
| dbbak_htars/robinson.09_15_2008 | robinson/old | twice monthly robinson database backups (Jan. 2007 - Aug. 2008) | tarball |
| RunLog-20071101.sql.gz | run/old/RunLog-20071101.sql.gz | RunLog database backup (Nov. 1, 2007) | single file (13GB) |
| dbbak_htars/RunLog_2007.09_18_2008 | run/old/RunLog-2007* | twice monthly RunLog database backups (Jan. - Mar. 2007, Nov. 15 2007 - Dec. 2007 ) | tarball |
| dbbak_htars/RunLog_Jan-Feb_2008.09_18_2008 | run/old/RunLog-20080[12]* | twice monthly RunLog database backups (Jan. - Feb. 2008) | tarball |
| dbbak_htars/run.09_18_2008 | run/old/RunLog-20080[345678]* | twice monthly run database backups (Mar. - Aug. 2008) | tarball |
| dbbak_htars/Missing_Items.txt | N/A | a text file explaining that there are no backups for Sept. 1 or Sept 15, 2008. | single file |
Contact persons for remote db mirrors
| N | Server type | Server | Contact | Active? | |
|---|---|---|---|---|---|
| 1 | Offline | rhic23.physics.wayne.edu:3306 | Peter Chen | pchen@sun.science.wayne.edu | YES |
| 2 | Offline | pstardb1.nersc.gov:3306 | Jeff Porter | rjporter@lbl.gov | YES |
| 3 | Offline | stardb.ujf.cas.cz:3306 | Michal Zerola | zerola@matfyz.cz | NO |
| 4 | Offline | sampa.if.usp.br | Alex Suaide | suaide@dfn.if.usp.br | NO |
| 5 | Offline | star1.lns.mit.edu | TBD | NO | |
| 6 | Offline | rhilxs.ph.bham.ac.uk | Lee Barnby | lbarnby@bnl.gov | NO |
| 7 | Offline | stardb.tamu.edu | TBD | NO | |
| 8 | Offline | rhig.physics.yale.edu | Christine Nattrass | nattrass@rhig.physics.yale.edu | NO |
| 9 | Offline | hvergelmir.mslab.usna.edu:3316 | Richard Witt |
witt@usna.edu |
YES |
| 10 | FileCatalog | pstardb4.nersc.gov:3336, PDSF M/S | Jeff Porter | rjporter@lbl.gov | YES |
| 11 | Offline | MIT slave | Mattew Walker | mwalker@mit.edu | NO |
| 12 | Offline | osp2.lbl.gov:3316, LBL slave | Doug Olsen | dlolson@lbl.gov | YES |
| 13 | Offline | stardb2.sdfarm.kr:3316, KISTI slave | Xianglei Zhu | zhux@tsinghua.edu.cn | YES |
Monitoring
Database monitoring
Following tools are available for replication check:
1. Database health monitoring: Mon package, which allows to see what is going on with database health, integrity, and replication state at this very moment. It sends email notifications if it sees unreachable or overloaded hosts, along with replication error notifications.

2. Server-side replication check made by M.DePhillips. This script checks which slaves are connected to master (robinson) on daily basic. List of connected slaves is compared to the known slave list (stored at dbAdmin database at heston.star.bnl.gov)......
MySQL Version Upgrades
This section contains information about MySQL version upgrades and related issues. Mostly, it is required to keep track of nuances..
ChangeLog:
2010-03-08: all mysql servers upgraded to 5.0.77 version, using default rpms from SL5 package. Overview of existing mysql server versions is available through Mon interface.
MySQL ver 5 Update
This page describes rational for upgrading to version 5 of Mysql.
Change log for 5.0.x can be found here....
dev.mysql.com/doc/refman/5.0/en/news-5-0-x.html
Upgrade Rational:
1) 4.1.x will be deprecated very shortly - bugs no longer pursued.
2)Current release is 5.1 - 5.0. is one still major release behind with a shorten shelf life
3) 5.0 is in production mode at PDSF and RCF there are compatibility issues.
Issues with Client:
1) the only comment I would have that native
SL3 mysql version includes version 4 of mysql client (4.0.26 to
be exact) aka the same than under SL3.0.5. SL5 (much later in the
game) 4.1.11 so again from the V4 series.
2) Possibly, you will have to deal with special patching procedure
on nodes where you deploy V5 as it will unlikely be part of the
baseline erratas for V4 ... but that is probably a detail [as mysql
release the patches too]
3) There seem to be a few issues with the clients which need
upgrading (perl DBI being one).
--This issue is with the 4.1 client accessing the 5.0 servers...(Pavel trying to access rcf) I was not able to reproduce
The question is compatibility with
SL native distribution versions ... It would be an issue if our
PHP tools would break ... A full evaluation welcomed (with caveats).
Do you think you could get a PHP view of things?
--Tested and our PHP works fine with 5.0
4) With regard to prepared statements....
- client MySQL libs version 5.x: LIMIT ? would pass a quoted
string.
- client MySQL libs version 4.x: LIMIT ? would pass an integer
and ensure type SQL_INTEGER in bind
Additional information
+ server version 5.x: would allow LIMIT ? and treated differently
than in version 4.x (hence the client version behavior difference)
+ client version 4 / server version 4: all is fine
+ INSERT NOW()+0 used to work but now fails with MySQL version 5 and up
Evaluations:
So far I have tested the 4 client with 5 server and 5 client with 5 server - with regard to PHP, perl
and command line (script) access. Modulo the prepared statement issue stated above (limit ?) tests are successful and are in fact in production i.e., DRUPAL is php accessing a 5 server and the file catalog on heston is perl from a 4 client accessing a 5 server.
MySQL servers optimization
[Before optimization – current state]
-
orion.star.bnl.gov (3306, 3346), Apache, Drupal, SKM
-
duvall.star.bnl.gov (3336, 3306), FC slave, operations (many databases)
-
brando.star.bnl.gov (3336), FC slave
-
heston.star.bnl.gov (3306), Nova, logger, gridsphere + some outdated/not used dbs
-
connery.star.bnl.gov – Tomcat server
-
alpha.star.bnl.gov – test node (zrm backup, Monitoring, mysql 5.0.77)
-
omega.star.bnl.gov (3316) – Offline backup (mysql 5.0.77)
-
omega.star.bnl.gov (3336) – FC backup (mysql 5.0.77)
Most servers have bin.tgz MySQL 5.0.45a
[After optimization]
new orion, duvall, brando = beefy nodes
-
orion : Apache server, JBoss server (replaces Tomcat), FC slave db, drupal db, SKM db, Nova;
-
duvall: FC slave, copy of web server, drupal db slave, operations db, logger, gridsphere, jboss copy;
-
brando: FC slave, copy of web server, drupal db slave, operations db slave, jboss copy
-
alpha : test node (mysql upgrade, infobright engine, zrm backup(?));
-
omega : Offline backup slave, FC backup slave, operations db backup slave;
All servers will have MySQL 5.0.77 rpm – with possible upgrade to 5.1.35 later this year.
[free nodes after replacement/optimization]
-
connery
-
orion
-
duvall
-
brando
-
dbslave03
-
dbslave04
-
+ several nodes from db0x pool (db04, db05, db06, db11, bogart, etc...)
Non-root access to MySQL DB nodes
As outlined in Non-user access in our enclaves and beyond, and specifically "Check on all nodes the existence of a mysql account. Make sure the files belong to that user + use secondary groups wherever applies", the following work has been done recently:
ToDo list. To allow DB admin tasks under 'mysql' account (non-standard configuration), the following set of changes has been identified:
- add the mysql user account on each DB server to the STAR SSH key management system and add the DB administrator's SSH key;
- full read/write access to /db01/<..> - mysql data files;
- read/write access to /etc/my.cnf - mysql configuration file;
- read access to /var/log/mysqld.log - mysql startup/shutdown logs;
- standard /etc/init.d/mysqld startup script is removed and /etc/init.d/mysql_multi startup script (non-standard, allows multi-instance mysql) is installed;
- the mysqld_multi init script's start and stop functions check who is executing the script - if it is the mysql user, then nothing special is done, but if it is another user, then it uses "su - mysql -c <command>" to start and stop the MySQL server. The root user can do this without any authentication. If any other user tries it, it would require the mysql account password, which is disabled.;
- to prevent reinstallation of the /etc/init.d/mysqld script by rpm update procedure, specially crafted "trigger"-rpm is created and installed. It watches for rpm updates, and invokes "fix" procedure to prevent unwanted startup script updates;
- extra user with shutdown privilege is added to all mysql instances on a node, to allow safe shutdowns by mysql_multi;
- mysql accout (unix account) was configured to have restricted file limits (2k - soft, 4k - hard) [FIXME: for multi-instance nodes it needs to be increased];
Upgrade timeline. STAR has four major groups of database nodes: Offline, FileCatalog, Online and SOFI. Here is a coversion plan [FIXME: check with Wayne]:
- Offline db nodes (namely, dbXY.star series) are fully converted and tested (with the exceptions of db03 and db09);
- FileCatalog db nodes (fc1, fc2, fc4) are done (completed 8/7/2012);
- 8/7/2012: note that the rpm is being updated to clean up some triggering problems recently discovered and should be updated on all the hosts done previously
- SOFI db nodes (backups, archival, logger, library etc, including robinson, heston, omega, fc3, db09, db03) - conversion start date TBD;
- Online nodes (onldb.starp, onldb2.starp, dbbak?) - conversion start date is ~Sep 2012;
- additional nodes TBD: orion
Performance
Below is a listing of adjustable mysql performance parameters, their descriptions and their current settings. Where applicable, the reasons and decisions that went into the current setting is provied. Also presented is the health of the parameter with the date the study was done. These parmaters should be reveiwed every six months or when the system warrents a review.
| Parameter | Setting | Definition | Mysql Default | Reasoning | Health | Last Checked | ||
|---|---|---|---|---|---|---|---|---|
| bulk_insert_buffer_size | 8388608 | |||||||
| join_buffer_size | 131072 | |||||||
| table_cache | 1024 | Increases the amount of table that can be held open | 64 | |||||
| key_buffer_size | 268435456 | amount of memory available for index buffer | 523264 | |||||
| myisam_sort_buffer_size | 67108864 | |||||||
| net_buffer_length | 16384 | |||||||
| read_buffer_size | 1044480 | |||||||
| read_rnd_buffer_size | 262144 | |||||||
| sort_buffer_size | 1048568 | Each thread that needs to do a sort allocates a buffer of this size. Increasing the variable gives faster ORDER BY or GROUP BY operations |
"old" vs "new" nodes comparison, Jan-Feb 2011
"Old" vs "new" nodes comparison, Jan-Feb 2011
1. HARDWARE
| PARAMETER | OLD NODE | NEW NODE |
|---|---|---|
| CPU | ||
| Type | 2 x Intel(R) Xeon(TM) CPU 3.06GHz +HT | Quad-core Intel(R) Xeon(R) CPU X3450 @ 2.67GHz, +HT |
| Cache Size | 512 KB | 8 MB |
| Bogomips | 6110.44 / processor | 5319.95 / core |
| Arch | 32 bit | 64 bit |
| RAM | ||
| Total | 3 GB | 8GB |
| ECC Type | Multi-bit ECC | Multi-bit ECC |
| Type | DDR | DDR3 |
| Speed | 266 MHz | 1333 MHz |
| Slots | 4 (4 max), 2x512, 2x1024 MB | 4 (6 max), 4 x 2048 MB |
| DISKS | ||
| HDD | 3 x SEAGATE Model: ST3146807LC | 3 x SEAGATE Model: ST3300657SS-H |
| Size | 146.8 GB | 146.8 GB |
| Cache | 8 MB | 16 MB |
| Spin Rate | 10K RPM | 15K RPM |
| RAID | Software RAID | Software RAID |
2. Database Performance: First Pass, mostly Synthetics + random STAR Jobs
Test results : - unconstrained *synthetic* test using SysBench shows that new nodes perform ~x10 times better than old ones (mostly due to x2 more ram available per core => larger mysql buffers, fs cache etc); - real bfc job tests (stress-test of 100 simultaneous jobs, random stream daqs) show performance similar to old nodes, with ~5% less time spent in db (rough estimation, only able to run that 100 jobs test twice today). Similar disk performance assumes similar db performance for those random streams, I guess.. - nightly tests do not seem to affect performance of those new nodes (negligible load vs. twice the normal load for old nodes).
| PARAMETER | OLD NODE | NEW NODE |
|---|---|---|
| Temporary tables created on disk | 44% | 22% |
| Sorts requiring temporary tables | 2% | 1% |
| Table locks acquired immediately | 99% | 100% |
| Average system load during "stream"test |
60-80 | 2.0-3.5 |
| Average CPU consumption | 100% | 30-40% |
MySQL Performance Tuning
MySQL performance tuning
Primary purpose:
a) performance optimization of the existing Offline and FileCatalog databases at MySQL level (faster response time, more queries per second, less disk usage etc);
b) future db needs projections, e.g. what hardware we should use (or buy) to meet desired quality of service for STAR experiment in next few years;
c) STAR DB API performance bottlenecks search;
Expected speed-up factor from MySQL optimizations (buffers, query modes) is about 20-50%, API optimization gain *potentially* could be much higher than that.
Test node(s)
OFFLINE: dbslave03.star.bnl.gov, which is not included in Offline DB activies (backup-only); OFFLINE DB is READ-HEAVY.
FILECATALOG: dbslave04.star.bnl.gov, which is not included in FC DB activies (backup-only); FILECATALOG DB is WRITE-HEAVY.
Measured db response values
1. Queries Per Second (QPS) - defined as QPS = (Total Queries / Uptime ) for cold start, and QPS = (dQueries/dUptime) for hot start;
2. Time to process typical reco sample - a) 5, 50, 500 events single job; b) several parallel jobs 500 events each (N jobs - tbd) - defined as TPS = (first job start time - last job stop time) for both cold and hot regimes;
Both parameters would be estimated in two cases :
a) cold start - sample runs just after mysql restart - all buffers and caches are empty;
b) hot start - 1000 events already processed, so caches are full with data;
MySQL varied parameters
per thread buffers : preload_buffer_size, read_buffer_size, read_rnd_buffer_size, sort_buffer_size, join_buffer_size, thread_stack;
global buffers : key_buffer_size, query_cache_size, max_heap_table_size, tmp_table_size;
insert parameters : bulk_insert_buffer_size, concurrent_insert [e.g.=2 vs =1], pack_keys (enabled, disabled)
compression features : do we need compression for blobs at API level?
DNS parameters : HOST_CACHE_SIZE (default = 128);
Initial parameter values are :
| Per Thread Buffers | Default Value | Default HighPerf | Modified Value | Description |
|---|---|---|---|---|
| preload_buffer_size | 32K | 32K | The size of the buffer that is allocated when preloading indexes. | |
| read_buffer_size | 128K | 1M | Each thread that does a sequential scan allocates a buffer of this size (in bytes) for each table it scans. | |
| read_rnd_buffer_size | 256K | 256K | When reading rows in sorted order following a key-sorting operation, the rows are read through this buffer to avoid disk seeks.Setting the variable to a large value can improve ORDER BY performance by a lot. However, this is a buffer allocated for each client, so you should not set the global variable to a large value. Instead, change the session variable only from within those clients that need to run large queries. |
|
| sort_buffer_size | 2M | 2M | Each thread that needs to do a sort allocates a buffer of this size. Increase this value for faster ORDER BY or GROUP BY operations. |
|
| myisam_sort_buffer_size | 8M | 64M | The size of the buffer that is allocated when sorting MyISAM indexes during a REPAIR TABLE or when creating indexes with CREATE INDEX or ALTER TABLE. |
|
| join_buffer_size | 128K | 128K | The size of the buffer that is used for plain index scans, range index scans, and joins that do not use indexes and thus perform full table scans. Normally, the best way to get fast joins is to add indexes. Increase the value of join_buffer_size to get a faster full join when adding indexes is not possible. |
|
| thread_stack | 192K | 192K | The stack size for each thread. |
| Global Buffers | Default Value | Default HighPerf | Modified Value | Description |
|---|---|---|---|---|
| key_buffer_size | 8M | 256M | Index blocks for MyISAM tables are buffered and are shared by all threads. key_buffer_size is the size of the buffer used for index blocks. The key buffer is also known as the key cache. |
|
| query_cache_size | 0 | 0 | The amount of memory allocated for caching query results. The default value is 0, which disables the query cache. The allowable values are multiples of 1024; other values are rounded down to the nearest multiple. | |
| max_heap_table_size | 16M | 16M | This variable sets the maximum size to which MEMORY tables are allowed to grow. The value of the variable is used to calculate MEMORY table MAX_ROWS values. |
|
| tmp_table_size | system-dependent | 32M | The maximum size of internal in-memory temporary tables. If an in-memory temporary table exceeds the limit, MySQL automatically converts it to an on-disk MyISAM table. Increase the value of tmp_table_size (and max_heap_table_size if necessary) if you do many advanced GROUP BY queries and you have lots of memory. |
| Write operations | Default Value | HighPerf Value | Modified Value | Description |
|---|---|---|---|---|
| bulk_insert_buffer_size | 8M | 8M | MyISAM uses a special tree-like cache to make bulk inserts faster for INSERT ... SELECT, INSERT ... VALUES (...), (...), ..., and LOAD DATA INFILE when adding data to non-empty tables. This variable limits the size of the cache tree in bytes per thread. Setting it to 0 disables this optimization. |
|
| concurrent_insert | 1 | 1 | 0 = Off 1 = (Default) Enables concurrent insert for MyISAM tables that don't have holes2 = Enables concurrent inserts for all MyISAM tables, even those that have holes. For a table with a hole, new rows are inserted at the end of the table if it is in use by another thread. Otherwise, MySQL acquires a normal write lock and inserts the row into the hole. |
"concurrent_insert" is interesting for FileCatalog database - we do many inserts quite often.
DNS
Quote from MySQL manual : "If you have a very slow DNS and many hosts, you can get more performance by either disabling DNS lookop with --skip-name-resolve or by increasing the HOST_CACHE_SIZE define (default: 128) and recompile mysqld." - we definitely have more than 128 hosts accessing our databases simultaneously, which means that we need to increase it to something like 2048 or so (to account for RCF farm nodes). Currently, both stock mysql distribution and HighPerformance version have 128 hosts set as buffer default.
Node FileSystem parameters
1. We should check "dir_index" feature of ext3 filesystem, which allows
Brando $> tune2fs -l /dev/hdb1 | grep "dir_index" => dir_index enabled
Duvall $> tune2fs -l /dev/sdc1 |grep "dir_index" => dir_index disabled
2. "noatime" mount option for /db0X disks, to reduce IO load a little bit. Both Duvall and Brando have no "noatime" attribute set (11 May 2009).
3. /tmp location (same disk, separate disk, RAM disk).
FC Duvall at duvall is using /dbtemp (ext. disk, raid?);
FC Brando is not using /dbtemp, because there's no /dbtemp defined in system yet;
Node varied parameters
Number of CPUs scaling (1,2,4);
CPU power dependence;
RAM capacity dependence (1 Gb, 2Gb, 2+ Gb);
HDD r/w speed;
FileCatalog DB performance study
FileCatalog DB is ~ 30% READ / 70% WRITE database. Spiders frequently update file locations (on local disks), new files constantly appear during Run period etc.. Therefore, INSERT/UPDATE performance will be studied first.
Typical R/W percentage could be seen here :
Duvall profile information,
or here :
Brando profile information
Offline DB performance study
Offline Database is READ-heavy (99% reads / 1% writes due to replication), therefore it should benefit from various buffers optimization, elimination of key-less joins and disk (ram) IO improvements.
Typical Oflline slave R/W percentage could be seen here :
db08 performance profile
First results :
================================================================================ Sample | 50 BFC events, pp500.ittf chain --------+----------------+------------------------------------------------------ Host | dbslave03.star.bnl.gov:3316 - Offline --------+----------------+------------------------------------------------------ Date | Fri, 08 May 2009 16:01:12 -0400 ================================================================================ SERVER GLOBAL VARIABLES ================================================================================ Variable Name | Config Value | Human-Readable Value ================================================================================ preload_buffer_size | 32768 | 32 KB -------------------------+------------------------------------------------------ read_buffer_size | 1048576 | 1 MB -------------------------+------------------------------------------------------ read_rnd_buffer_size | 262144 | 256 KB -------------------------+------------------------------------------------------ sort_buffer_size | 1048576 | 1 MB -------------------------+------------------------------------------------------ myisam_sort_buffer_size | 67108864 | 64 MB -------------------------+------------------------------------------------------ join_buffer_size | 131072 | 128 KB -------------------------+------------------------------------------------------ thread_stack | 196608 | 192 KB ================================================================================ key_buffer_size | 268435456 | 256 MB -------------------------+------------------------------------------------------ query_cache_size | 33554432 | 32 MB -------------------------+------------------------------------------------------ max_heap_table_size | 16777216 | 16 MB -------------------------+------------------------------------------------------ tmp_table_size | 33554432 | 32 MB ================================================================================ bulk_insert_buffer_size | 8388608 | 8 MB -------------------------+------------------------------------------------------ concurrent_insert | 1 | 1 ================================================================================ PERFORMANCE PARAMETERS ================================================================================ PARAMETER | Measured Value | Acceptable Range ================================================================================ Total number of queries | 6877 | > 1000. -------------------------+------------------------------------------------------ Total time, sec | 1116 | any -------------------------+------------------------------------------------------ Queries/second (QPS) | 6.16 | > 100. -------------------------+------------------------------------------------------ Queries/second - SELECT | 5.89 | > 100.0 -------------------------+------------------------------------------------------ Queries/second - INSERT | 0.17 | any -------------------------+------------------------------------------------------ Queries/second - UPDATE | 0 | any -------------------------+------------------------------------------------------ Query cache efficiency | 45 % | > 20% -------------------------+------------------------------------------------------ Query cache overhead | 6 % | < 5% -------------------------+------------------------------------------------------
Initial test revealed strange things: there seem to be too many queries (~7000 queries for only two real db sessions??!), and Query Cache efficiency is 45%! Logs revealed the mystery - we somehow allow many repetitive queries in our API. Further investigation found more issues - see below.
a) Repetitive ID requests (they are queried one after another, no changes or queries in between):
....
3 Query select elementID from ladderIDs
3 Query select elementID from ladderIDs
....
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
....
3 Query select elementID from SectorIDs where Sector=1
3 Query select elementID from SectorIDs where Sector=1
3 Query select elementID from SectorIDs where Sector=1
3 Query select elementID from SectorIDs where Sector=1
....
3 Query select elementID from HybridIDs where Barrel=1 AND Ladder=1 AND Wafer=1 AND Hybrid=1
3 Query select elementID from HybridIDs where Barrel=1 AND Ladder=1 AND Wafer=1 AND Hybrid=1
3 Query select elementID from HybridIDs where Barrel=1 AND Ladder=1 AND Wafer=1 AND Hybrid=1
3 Query select elementID from HybridIDs where Barrel=1 AND Ladder=1 AND Wafer=1 AND Hybrid=1
3 Query select elementID from HybridIDs where Barrel=1 AND Ladder=1 AND Wafer=1 AND Hybrid=1
c) Repetitive date/time conversions via mysql function, like those below :
4 Query select from_unixtime(1041811200) + 0 as requestTime
4 Query select unix_timestamp('20090330040259') as requestTime
b) Repetitive DB Initializations for no real reason :
3 Init DB Geometry_tpc
3 Init DB Geometry_ftpc
3 Init DB Geometry_tof
3 Init DB Geometry_svt
3 Init DB Geometry_ssd
3 Init DB Geometry_tpc
(that's what was need to do a query agains Geometry_tpc database)
Full logs could be found in attachment to this page.
PLOTS - Query Cache
Query cache does not seem to help under 150 connections.....
Note different Y axis for Bogart
Bogart - No Query Cache

Bogart - Query Cache DEMAND Size = 26255360

DB02- No Query Cache

DB02- Query Cache DEMAND Size = 26255360

Plots - DB02 old/new Compare
Penguin Relion 230 vrs. Dell Precision 530 (specs here link to be added....)
Note the different time scales on the Y axis.
Summary: The new penguin has faster db access under 150 connection but responds much slower than the dell
when connections are greater than 150 connection.
There is an additional point under the htemp box for 350 connections, @~11000 seconds. This point was taken with 8 clients (instead of 4 clients) to see if the clients where influencing results, slope is the same, apparently not.
There are two plots of the Penguin each showing a differnent RAID array. The results are essentially identical under 150 connections. Over 150 connections the first RAID array is much better.
The first plot is of the Penguin with first RAID array (Wayne please edit with specifics:

Penguin with Second RAID Array
Dell:

Plots - Key Buffer = 52
This plot shows x=number of connections , y=time it takes for the StDbLib to retrun a complete data set for all the Star Offline databases. This set of plot returns the key_buffer_size from the STAR defualt of 268435456 to the mysql defualt of 523264.
Bogart
DB02
DB03

DB08
Plots - Star Default
This plot shows x=number of connections , y=time it takes for the StDbLib to retrun a complete data set for all the Star Offline databases. This set of plot uses the STAR defualt parameters as described one page up. This is to be used as a baseline for comparisions.
Bogart
DB02
DB03

DB08
Plots = Table Cache 64
This plot shows x=number of connections , y=time it takes for the StDbLib to retrun a complete data set for all the Star Offline databases. This set of plot returns the table_cache from the STAR defualt of 1024 to the mysql defualt of 64.
Bogart
DB02

DB03

DB08
Replication
Replication enables data from one MySQL database server (called the master) to be replicated to one or more MySQL database servers (slaves). Replication is asynchronous - your replication slaves do not need to be connected permanently to receive updates from the master, which means that updates can occur over long-distance connections and even temporary solutions such as a dial-up service. Depending on the configuration, you can replicate all databases, selected databases, or even selected tables within a database.
The target uses for replication in MySQL include:
-
Scale-out solutions - spreading the load among multiple slaves to improve performance. In this environment, all writes and updates must take place on the master server. Reads, however, may take place on one or more slaves. This model can improve the performance of writes (since the master is dedicated to updates), while dramatically increasing read speed across an increasing number of slaves.
-
Data security - because data is replicated to the slave, and the slave can pause the replication process, it is possible to run backup services on the slave without corrupting the corresponding master data.
-
Analytics - live data can be created on the master, while the analysis of the information can take place on the slave without affecting the performance of the master.
-
Long-distance data distribution - if a branch office would like to work with a copy of your main data, you can use replication to create a local copy of the data for their use without requiring permanent access to the master.
Fixing Slave Replication In A STAR Offline Database Mirror
Mike's trick for fixing an offline database slave when it won't sync with the master is to be carried out as follows:
cd /var/run/mysqld
ls -lh | grep "mysqld-relay-bin"
Find the relay file with the largest number at the end (this is the latest one)
Make sure the first line of the text file "/db01/offline/data/relay-log.info" contains that file
ie:
ls -lh | grep "mysqld-relay-bin"
mysqld-relay-bin.000001
mysqld-relay-bin.000002
so this means that /db01/offline/data/relay-log.info should contain:
"/var/run/mysqld/mysqld-relay-bin.000002"
as the first line
Then login to mysql via "mysql -S /tmp/mysql.3316.sock -p -u root"
and issue the command "slave start;"
then check the status with "show slave status \G"
Slave_IO_Running should show "Yes"
Slave_SQL_Running should show "Yes"
You may need to repeat this procedure if you get an error the first time.
Master/Slave syncronization issues,tools,solutions etc...
This page is dedicated to variety of master/slave syncronization issues, tools and solutions used at STAR. It is made for internal usage, tutorial for offsite facilities would be created later.
Maatkit (formerly MySQL Toolkit) is a bunch of Perl scripts, designed to make MySQL daily management tasks easier. STAR makes use of 'mk-table-checksum' to get lock-free reliable checksumming of FileCatalog and Offline database tables, and 'mk-table-sync' to fix inconsistent tables on slaves.
I. FileCatalog replication checksums
Master server: robinson.star.bnl.gov:3336
mk-table-checksum uses "repl.checksum" (database.table) to store checksum results. If FC slave was added after Nov.2008, then such table should be created manually. If not done exactly as described, checksums will not work properly, and slave will stop replicating with error message stating that "table repl.checksum does not exist".
CREATE DATABASE repl;
CREATE TABLE checksum (
db char(64) NOT NULL,
tbl char(64) NOT NULL,
chunk int NOT NULL,
boundaries char(64) NOT NULL,
this_crc char(40) NOT NULL,
this_cnt int NOT NULL,
master_crc char(40) NULL,
master_cnt int NULL,
ts timestamp NOT NULL,
PRIMARY KEY (db, tbl, chunk)
);
HOW-TO calculate checksums for all FileCatalog tables on Master, results and queries will propagate to slaves :
shell> nohup ./mk-table-checksum --emptyrepltbl --replicate=repl.checksum --algorithm=BIT_XOR \ h=robinson.star.bnl.gov,P=3336,u=root,p=XYZ -d FileCatalog_BNL >> checkrepl.log.txt 2>&1
At this moment (Nov.2008), it takes about 20 min to checksum all FC tables.
HOW-TO show if there are any differences between master (robinson) and slaves (duvall, brando), when checksumming process is finished :
shell> mysql -u root --host duvall.star.bnl.gov --port 3336 -pXYZ -e "USE repl; SELECT db, tbl, chunk, this_cnt-master_cnt AS cnt_diff, this_crc <> master_crc OR ISNULL(master_crc) <> ISNULL(this_crc) AS crc_diff FROM checksum WHERE master_cnt <> this_cnt OR master_crc <> this_crc OR ISNULL(master_crc) <> ISNULL(this_crc);" > duvall.tablediff.txt shell> mysql -u root --host brando.star.bnl.gov --port 3336 -pXYZ -e "USE repl; SELECT db, tbl, chunk, this_cnt-master_cnt AS cnt_diff, this_crc <> master_crc OR ISNULL(master_crc) <> ISNULL(this_crc) AS crc_diff FROM checksum WHERE master_cnt <> this_cnt OR master_crc <> this_crc OR ISNULL(master_crc) <> ISNULL(this_crc);" > brando.tablediff.txt
HOW-TO show the differences (by row) between master and slave for selected table. In the example below, changes for table "TriggerWords" is requested for duvall.star.bnl.gov :
shell> ./mk-table-sync --print --synctomaster --replicate repl.checksum h=duvall.star.bnl.gov,P=3336,u=root,p=XYZ,D=FileCatalog_BNL,t=TriggerWords
To make an actual syncronization, one should replace "--print" option with "--execute" (please make sure you have a valid db backup first!). It is often good to check how many rows need resync and how much time it would take, because it might stop replication process for this time.
Replication monitoring
Following tools are available for replication check:
1. Basic monitoring script, which allows to see what is going on with replication at this very moment. It does not send any notifications and cannot be thought as complete solution to replication monitoring. Mature tools (like Nagios) should be used in near future.
2. Server-side replication check made by M.DePhillips. This script checks which slaves are connected to master (robinson) on daily basic. List of connected slaves is compared to the known slave list (stored at dbAdmin database at heston.star.bnl.gov).
Server list and various parameters
Here will be a server list (only those servers participating in various replication scenarios)
1. FileCatalog master db server : fc1.star.bnl.gov:3336, ID: 880853336
slaves:
- fc2.star.bnl.gov:3336, ID: 880863336
- fc3.star.bnl.gov:3336, ID: 880873336 [ backup server, not used in round-robin ]
- fc4.star.bnl.gov:3336, ID: 880883336
2. Offline master db server: robinson.star.bnl.gov:3306, ID: 880673316
slaves:
- db01.star.bnl.gov:3316, ID: 880483316
- db02.star.bnl.gov:3316, ID: 880493316 - FAST rcf network
- db03.star.bnl.gov:3316, ID: 880503316 [ 23 Jul 09, new ID: 881083316 ] - FAST rcf network
- db04.star.bnl.gov:3316, ID: 880513316 [ 14 Jul 09, new ID: 881043316 ] - FAST rcf network
- db05.star.bnl.gov:3316, ID: 880523316 [ 16 Jul 09, new ID: 881053316 ] - FAST rcf network
- db06.star.bnl.gov:3316, ID 881023316 [old ID: 880533316 ]
- db07.star.bnl.gov:3316, ID: 880543316
- db08.star.bnl.gov:3316, ID: 880613316
- db10.star.bnl.gov:3316, ID: 880643316 [ 20 Jul 09, new ID 881063316 ]
- db11.star.bnl.gov:3316, 881033316 [ old ID: 880663316 ]
- db12.star.bnl.gov:3316, ID: 881013316, as of Apr 28th 2010, ID: 880253316
- db13.star.bnl.gov:3316 (former bogart), ID: 880753316 [ 22 Jul 09, new ID 881073316 ]
- omega.star.bnl.gov:3316, ID: 880843316 [3 Dec 09, backup server]
- db14.star.bnl.gov:3316, ID: 541043316
- db15.star.bnl.gov:3316, ID: 541053316
- db16.star.bnl.gov:3316, ID: 541063316
- db17.star.bnl.gov:3316, ID: 541073316
- db18.star.bnl.gov:3316, ID: 541083316
- onldb.starp.bnl.gov:3601, ID: 600043601 | resides in ONLINE domain
- onldb2.starp.bnl.gov:3601, ID: 600893601 | resides in ONLINE domain
External slaves :
Seo-Young Noh <rsyoung@kisti.re.kr>? KISTI (first server) : 990023316
Xianglei Zhu <zhux@tsinghua.edu.cn> KISTI (second server) : 991013316
Richard Witt <witt@usna.edu> : hvergelmir.mslab.usna.edu, 992073316 | USNA
Kunsu OH <kunsuoh@gmail.com> : 992083316 | Pusan National University
Peter Chen <pchen@sun.science.wayne.edu> : rhic23.physics.wayne.edu, 991063316| Wayne State University
Matt Walker <mwalker@mit.edu> : glunami.mit.edu, 992103316 | MIT
Jeff Porter <rjporter@lbl.gov>, pstardb1.nersc.gov, 1285536651 | PDSF
Douglas Olson <dlolson@lbl.gov> : 992113316 | LBNL
Server ID calculation :
SERVER_ID is created from the following scheme: [subnet][id][port], so 880613316 means 88 subnet, 061 id, 3316 port...
subnet '99' is reserved for external facilities, which will have something like 99[id][port] as server_id.
Setting Up A Star Offline Database Mirror
Set up an environment consistent with the STAR db environments.
- Create a user named 'mysql' and a group 'mysql' on the system.
- Create a directory for the mysql installation and data. The standard directory for STAR offline is /db01/offline
- In /db01/offline place the tarball of mysql version 5.0.51a (or greater) downloaded from here.
- Untar/zip it. Use "--owner mysql" in the tar command, or recursively chown the untarred directory so that mysql is the owner (eg. 'chown mysql:mysql mysql-5.0.51a-linux-i686-glibc23'). Delete the tarball if desired.
- Still in /db01/offline, create a soft link named 'mysql' that points to the mysql directory created by the untar (ln -s mysql-5.0.51a-linux-i686-glibc23 mysql'). /db01/offline should now have two items: mysql (a link), and mysql-standard-5.0.51a-linux-i686-glibc23.
- Create a directory /var/run/mysqld and set the owner to mysql, with 770 permissions. (This may be avoideable with a simple change to the my.cnf file (to be verified). If this change is made to the "official" my.cnf, then this step should be removed.)
Next, acquire a recent snapshot of the offline tables and a my.cnf file
There will be two files that need to be transfered to your server; a tarball of the offline database files (plus a handful of other files, some of which are discussed below) and a my.cnf file.
If you have access to RCF, a recent tar of the offline databases can be found here: /star/data07/db/offline_08xxxxx.tar.gz. Un-tar/zip the tarball (with "--owner mysql") in /db01/offline on your server to get a 'data' directory. (/db01/offline/data).
The my.cnf file can be found in /star/data07/db/my.cnf, and should be put in /etc/my.cnf. Before your server is started, either the master information should be commented out, or the server-id should be adjusted to avoid clashing with an existing production slave. Contact Dmitry Arkhipkin to determine an appropriate server-id.
Start the server
At this point you should be able to start the mysql server process. It should be as simple as the following command:
cd /db01/offline/mysql && ./bin/mysqld_safe --user=mysql &
The data directory
The databases
You will now find a complete snapshot of STARs offline data. We use MYSQLs MYISAM storage engine which stores its tables in three files under a directory that is the database name. For example, for database Calibrations_ftpc you will see a directory of the same name. If you descend into that directory you will see three files for each table name. The files are MYD which contain the data, MYI which contain the indexes and FRM which describes the table structure.
Other files
- master.info - This files contains information about the slaves master (aptly named). This includes who the master is, how to connect, and what was the last bit of data passed from the master to the slave. This is stored as an integer in this file.
- You will also find log files, bin files and their associated index files.
S&C Infrastructure Servers
| NAME | BASE HARDWARE | LINUX DISTRO | PROCESSOR(S) | RAM | NETWORK INFO | DISKS | PORTS: PURPOSES | LOCATION | HEALTH MONITORING |
ORIGINAL PURCHASE DATE |
Notes |
| robinson | Dell PowerEdge R420 | Sc.Linux 7.x | 2x Intel Xeon E5-2430 (Hex-core, 2.2GHz, 15MB cache, HT available but disabled) | 64GB + 32GB swap | 130.199.148.90: LACP: 2 x 1Gb/s |
PERC H710P RAID controller with 8 600GB 10K SAS drives (2.5") 6 drives form a RAID 10, with the remaining 2 drives set as hot spares /boot (1GB) / (150GB) swap (32GB) /db01 (1.5TB) |
3306: rh-mysql57-mysql-server, offline production/analysis master |
BCF Rack 4-10 | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
May 2014 (inherited from RACF in 2018) | offline database master |
| db01 | Dell PowerEdge R410 | Sc.Linux 7.x | 2x Intel Xeon X5650 (Hex-core, 2.67GHz, 12MB cache, HT available but disabled) | 64GB + 24GB swap | 130.199.148.101: LACP: 2 x 1Gb/s |
PERC H700 with four 600GB 15K 3.5" SAS drives in a RAID 10, with four partitions: /boot: 1GB /: 200GB swap: 24GB /db01: 900GB (approx.) |
3316: rh-mysql57-mysql-server, offline production/analysis slave | BCF | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
September 2011 (inherited from RACF in 2018) |
|
| db02 | Dell PowerEdge R710 | Sc.Linux 7.x | 2x Intel Xeon X5660 (Hex-core, 2.80GHz, 12 MB cache, HT available but disabled) | 96GB + 24GB swap | 130.199.148.102: LACP: 2 x 1Gb/s |
PERC H700 RAID controller with 6 2TB GB 7200RPM SAS drives in a RAID 10, partitioned as /boot (1GB) /db01 (5.3TB) / (187GB) swap (24GB) |
3316: rh-mysql57-mysql-server, offline production/analysis slave | BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) No Icinga |
February 2012 | |
| db04 | Dell PowerEdge R410 | Sc.Linux 7.x | 2x Intel Xeon X5650 (Hex-core, 2.67GHz, 12 MB cache, HT available but disabled) | 64GB + 32GB swap | 130.199.148.104: LACP: 2 x 1Gb/s |
PERC H700 RAID controller with 4 2TB GB 7200RPM SAS drives in a RAID 10, partitioned as /boot (1GB) /db01 (934GB) / (150GB) swap (32GB) |
3316: rh-mysql57-mysql-server (el7.x86_64) offline production/analysis slave | BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) No Icinga |
February 2012 | |
| ovirt-sdmz5 (old db05) | Dell PowerEdge R410 | Sc.Linux 7.x | 2x Intel Xeon X5650 (Hex-core, 2.67 GHz, 12MB cache, HT available but disabled) | 64GB + 32GB swap | 130.199.148.116: 1 x 1Gb/s |
PERC H700 RAID controller with 4 1 TB 7200RPM SAS drives, 2 in a RAID 1, partitioned as /boot (1GB) /data (794GB) / (99GB) swap 2 drives each in their own RAID 0 for GlusterFS bricks |
Ovirt GlusterFS |
BCF | smartd (starsupport) disk space mon (starsupport) MegaRAID Storage Manager (17.05.00.02) (starsupport) Ganglia Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
October 2011 (inherited from RACF in 2018) | Ovirt Hypervisor Gluster storage host |
| db06 | Dell PowerEdge R610 | Sc. Linux 7.x | 2x Intel Xeon X5670 (Hex-core, 2.93 GHz, 12MB cache, HT available but disabled) | 48 GB + 24GB swap | 130.199.148.106: LACP: 2 x 1Gb/s |
PERC H700 RAID controller with 6 2.5" 600 GB 10K SAS drives in a RAID 10, partitioned as /boot (1GB) /db01 (1.5TB) / (187GB) swap |
3316: rh-mysql57-mysql-server (el7.x86_64) offline production/analysis slave | BCF | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
June 2011 | 1. part of the dbx.star.bnl.gov DNS round-robin |
|
db07 |
Dell PowerEdge R610 | Sc.Linux 7.x | 2x Intel Xeon X5670 (Hex-core, 2.93 GHz, 12 MB cache, HT available but disabled) | 48 GB + 24GB swap | 130.199.148.107: LACP: 2 x 1Gb/s |
PERC H700 RAID controller with 6 2.5" 600 GB 10K SAS drives in a RAID 10, partitioned as /boot (1GB) /db01 (1.5TB) / (187GB) swap |
3316: rh-mysql57-mysql-server (el7.x86_64) offline production/analysis slave |
BCF | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
February 2011 | 1. part of the dbx.star.bnl.gov DNS round-robin |
| db08 | Dell PowerEdge R610 | Sc.Linux 7.x | 2x Intel Xeon X5670 (Hex-core, 2.93 GHz, 12 MB cache, HT available but disabled) | 48 GB + 24GB swap | 130.199.148.108: LACP: 2 x 1Gb/s |
PERC H700 RAID controller with 6 2.5" 600 GB 10K SAS drives in a RAID 10, partitioned as |
3316: rh-mysql57-mysql-server (el7.x86_64) offline production/analysis slave |
BCF | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
February 2011 | 1. part of the dbx.star.bnl.gov DNS round-robin |
| db10 | Dell PowerEdge R610 | Sc.Linux 7.x | 2x Intel Xeon X5660 (Hex-core, 2.80GHz, 12MB cache, HT available but disabled) | 96GB + 32GB swap | 130.199.148.110: LACP: 2 x 1Gb/s |
PERC H700 RAID controller with 6 300 GB 15K SAS drives. Two form a RAID1 with /boot (500MB), swap, and / (244GB) Four drives are in a RAID 10 for /db01 (549GB) |
3316: rh-mysql57-mysql-server, offline production/analysis slave | BCF | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
November 2012 (inherited from RACF in 2018) |
1. Core team offline db server (see STAR DB XML) |
| Dell PowerEdge R710 | Sc.Linux 7.x | 2x Intel Xeon X5550 (Quad-core, 2.67GHz, 8MB cache, HT available but disabled) | 48GB + 24GB swap | 130.199.148.111: LACP: 2 x 1Gb/s |
PERC H200 RAID controller |
3316: rh-mysql57-mysql-server, offline production/analysis slave | BCF | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
April 2010 | ||
| ovirt-sdmz1 (old db12) | Dell PowerEdge R410 | Sc.Linux 7.x | 2x Intel Xeon X5650 (Hex-core, 2.67GHz, 12MB cache, HT available but disabled) | 64GB + 24GB swap | 130.199.148.105: 1 x 1Gb/s |
PERC H700 RAID controller with 4 1 TB 7200RPM SAS drives, 2 in a RAID 1, partitioned as /boot (1GB) /data (794GB) / (99GB) swap 2 drives each in their own RAID 0 for GlusterFS bricks
|
Ovirt GlusterFS |
BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) No Icinga |
February 2012 | Ovirt Hypervisor Gluster storage host |
| ovirt-sdmz2 (old db13) | Dell PowerEdge R410 | Sc.Linux 7.x | 2x Intel Xeon X5650 (Hex-core, 2.67GHz, 12MB cache, HT available but disabled) | 64GB + 24GB swap | 130.199.148.112: 1 x 1Gb/s |
PERC H700 RAID controller with 4 1 TB 7200RPM SAS drives, 2 in a RAID 1, partitioned as /boot (1GB) /data (794GB) / (99GB) swap 2 drives each in their own RAID 0 for GlusterFS bricks |
Ovirt GlusterFS |
BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) No Icinga |
February 2012 | Ovirt Hypervisor Gluster storage host |
| ovirt-sdmz3 (old db15) | Dell PowerEdge R410 | Sc.Linux 7.x | 2x Intel Xeon X5650 (Hex-core, 2.67GHz, 12MB cache, HT available but disabled) | 64GB + 24GB swap | 130.199.148.113: 1 x 1Gb/s |
PERC H700 RAID controller with 4 1 TB 7200RPM SAS drives, 2 in a RAID 1, partitioned as /boot (1GB) /data (794GB) / (99GB) swap 2 drives each in their own RAID 0 for GlusterFS bricks |
Ovirt GlusterFS |
BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) No Icinga |
February 2012 | Ovirt Hypervisor Gluster storage host |
| ovirt-sdmz4 (old db16) | Dell PowerEdge R410 | Sc.Linux 7.x | 2x Intel Xeon X5650 (Hex-core, 2.67GHz, 12MB cache, HT available but disabled) | 64GB + 24GB swap | 130.199.148.115: 1 x 1Gb/s |
PERC H700 RAID controller with 4 1 TB 7200RPM SAS drives, 2 in a RAID 1, partitioned as /boot (1GB) /data (794GB) / (99GB) swap 2 drives each in their own RAID 0 for GlusterFS bricks |
Ovirt GlusterFS |
BCF | smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) SKM |
February 2012 | Ovirt Hypervisor Gluster storage host |
| IBM System x3650 M3 -[7945AC1]- | Sc.Linux 7.x | 2x Intel Xeon E5645 (Hex-core, 2.40GHz, 12MB cache, HT available but disabled) | 96GB + 24GB swap | 130.199.148.117: LACP: 2 x 1Gb/s |
ServeRAID M1015 SAS/SATA Controller 2 160GB SATA 2.5" drives in a RAID 1 with: /boot: 1GB /: 125GB swap: 24GB 4 147GB SAS 15K RPM 2.5" drives in a RAID 10 with: /db01: 268GB |
3316: rh-mysql57-mysql-server, offline production/analysis slave | BCF | smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) SKM |
August 2011 | ||
| IBM System x3650 M3 -[7945AC1]- | Sc.Linux 7.x | 2x Intel Xeon E5645 (Hex-core, 2.40GHz, 12MB cache, HT available but disabled) | 96GB + 24GB swap | 130.199.148.118: LACP: 2 x 1Gb/s |
ServeRAID M1015 SAS/SATA Controller 2 160GB SATA 2.5" drives in a RAID 1 with: /boot: 1GB /: 125GB swap: 24GB 4 147GB SAS 15K RPM 2.5" drives in a RAID 10 with: /db01: 268GB |
3316: rh-mysql57-mysql-server, offline production/analysis slave | BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) SKM |
August 2011 | ||
| duvall (and db09 is an alias for duvall) | ASA/SuperMicro 1U, X9DRW motherboard | RHEL Workstation 6.x (64-bit) | 2x Intel Xeon E5-2620 v2 (6 cores each, 2.1GHz, 16MB cache, w/HT) |
32 GB+ 16GB swap | 130.199.148.93: LACP: 2 x 1Gb/s |
10 2.5" drive bays (0-7 on one controller, 8 & 9 on a different controller) 3x 1TB , each with 3 partitions for RAID 1 arrays (/, /boot and swap) - 2 active drives, 1 hot spare 2x 240GB SSD with 1 partition each. RAID1 array for /db01 |
3306: mysql-5.1.73 (RH), offlineQA, nova, LibraryJobs, OCS Inventory database (tbc), etc. | BCF | smartd (starsupport) disk space mon (starsupport) Ganglia Logwatch (WB) SKM OCS Inventory Osiris (starsupport) LogWatch (WB) No Icinga |
February 2015 | |
|
heston |
Penguin Relion 2600SA | RHEL Workstation 6.x (64-bit) | 2x Intel Xeon E5335 (Quad-core, 2.00GHz, 8MB cache) |
8GB + 10GB swap |
130.199.148.91: |
Six 750 GB (or 1TB) SATA drives identically partitioned: /db01: 2.6TB, ext4, RAID5 (5 drives + 1 spare) swap: 10GB, RAID5 (5 drives + 1 spare) |
3306: mysqld-5.1.73-8.el6_8 (RH) |
BCF |
mdmonitor (starsupport) smartd (starsupport) disk space mon. (starsupport) Ganglia (yes) Osiris (starsupport) LogWatch (WB) SKM |
August or November 2007 | former duvall, now a slave to duvall |
| |
130.199.148.92: LACP: 2 x 1Gb/s |
|
|||||||||
| onldb | IBM System x3650 M3 -[7945AC1]- | Sc.Linux 7.x | 2x Intel Xeon E5645 (hex-core, 2.4GHz, 12 MB cache, HT disabled at BIOS) | 96GB + 24GB swap |
130.199.60.70: 1Gb/s 172.16.0.10: 1Gb/s |
ServeRAID M1015 SAS/SATA controller with 12 disks: 2 x 150 GB SATA in a RAID 1 with: - /boot (1GB) - / (125GB) - swap 4 x 146 GB 15K SAS in a RAID 10 with /db01 (268GB) 6 x 900 GB 10K SAS in RAID 10 with /db02 (2.5TB) |
online current run DB master server | DAQ Room | MSM 17.05.00.02 (starsupport) smartd (starsupport) disk space mon. (starsupport) Ganglia Osiris (starsupport) LogWatch (WB) OCS Inventory (link needed) Icinga |
August 2011 | |
| onldb5 (former onldb) | Dell PowerEdge R510 | RHEL 6.x (64-bit) | Intel Xeon E5620 (quad-core, 2.4GHz, 12MB cache w/HT) | 8GB + 8GB swap |
130.199.60.29: 1Gb/s 172.16.128.10: 1Gb/s |
2 x 147 GB SAS (10K): -RAID 1, 8GB swap -RAID 1, 200MB /boot -RAID 1, 125 GB / 6 x 300 GB SAS (15K): -RAID 5, 550GB /mysqldata01 -RAID 5, 550GB /mysqldata02
|
former online current run DB server |
DAQ Room |
mdmonitor (starsupport) smartd (starsupport) disk space mon. (starsupport) Osiris (no) LogWatch (WB) SKM (no) Icinga |
December 2011 | |
| onldb2 | Dell Power Edge R310 | RHEL 6.x (64-bit) | Quad core (plus HT) Intel Xeon X3460 @ 2.80 GHz | 8GB + 8GB swap | em1: 130.199.60.89: 1Gb/s | 4x 2 TB SATA drives with four active partitions each. Four software RAID arrays across the four disks, used as follows: /boot: RAID1 (477MB ext4) swap: RAID10 (8GB) /: RAID10 (192GB ext4) /mysqldata00: RAID10 (3.4TB ext4) |
current run online DB server slave | DAQ Room | October 2010 | ||
| onldb3 | Dell PowerEdge 2950 | Sc.Linux 7.x | 2x Quad core Intel Xeon E5440 @ 2.83 GHz | 16GB + 8GB swap | 130.199.60.165: 1Gb/s | 6x 1TB 3.5" SATA drives with 4 partitions each, forming four software RAID arrays mounted as: /boot: 1GB /: 140GB /db01: 2.6TB swap: 8GB |
3316: rh-mysql57-mysql-server, offline production/analysis slave docker container with ScLinux 6 environment and mysql-5.1.73 for online database slaves |
DAQ Room |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) |
January 2009 | |
| onldb4 | Dell PowerEdge 2950 | Sc.Linux 7.x | 2x Quad core Intel Xeon E5440 @ 2.83 GHz | 16GB + 8GB swap | 130.199.60.203: 1Gb/s | 6x 1TB 3.5" SATA drives with 4 partitions each, forming four software RAID arrays mounted as: /boot: 1GB /: 140GB /db01: 2.6TB swap: 8GB |
3316: rh-mysql57-mysql-server, offline production/analysis slave docker container with ScLinux 6 environment and mysql-5.1.73 for online database slaves |
DAQ Room |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) |
January 2009 | |
| dbbak | Dell PowerEdge R320 | RHEL 6.x (64-bit) | Quad Core Intel E5-1410 @2.8GHz, w/HT | 24GB + 8GB swap |
dbbak: |
online past run DB server | DAQ | December 2013 | Osiris master | ||
| Dell OptiPlex 755 | Sc.Linux 6.x (64-bit) | Core2 Duo E8300 @ 2.83GHz | 4GB + 2GB swap | 130.199.60.168: 1Gb/s | Intel RAID Matrix Storage Manager with two 500GB disks mirrored | DAQ | June 2008 | ||||
| mongodev01-03 | |||||||||||
| dashboard1 | Dell PowerEdge R320 | RHEL 6.x (64-bit) | Quad Core Intel E5-1410 @2.8GHz, w/HT | 24GB + 8GB swap | 130.199.60.91: 1Gb/s | S&C operations monitoring host | DAQ | December 2013 | Icinga and sFlow | ||
| mq01-mq03 | |||||||||||
| cephmon01-03 | |||||||||||
| fc1 | IBM System x3650 M3 -[7945AC1]- | Sc.Linux 7.x | 2x Intel Xeon E5645 (Hex-core, 2.40GHz, 12MB cache, HT available but disabled) | 96GB + 24GB swap | 130.199.148.86: LACP: 2 x 1Gb/s |
ServeRAID M1015 SAS/SATA Controller 2x 147GB 2.5" 15K RPM SAS in a RAID 1 with: /boot: 1GB /: 113GB swap: 24GB 6x 300GB 2.5" 15K RPM SAS in a RAID 10 with: /db01: 823GB |
3336: rh-mysql57-mysql-server, master File Catalog server | BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) SKM |
August 2011 | |
| fc2 | IBM System x3650 M3 -[7945AC1]- | Sc.Linux 7.x | 2x Intel Xeon E5649 (Hex-core, 2.53GHz, 12MB cache, HT available but disabled) | 96GB + 24GB swap | 130.199.148.87: LACP: 2 x 1Gb/s |
ServeRAID M1015 SAS/SATA Controller 4x 300GB SAS 15K RPM 2.5" drives in a RAID 10 with: /boot: 1GB /: 120GB swap: 24GB /db01: 411GB |
3336: rh-mysql57-mysql-server, File Catalog slave | BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) SKM |
August 2011 | |
| fc3 | Dell PowerEdge R610 | Sc.Linux 7.x | 2x Intel Xeon X5660 (Hex-core, 2.80GHz, 12MB cache, HT available but disabled) | 96GB + 8GB swap | 130.199.148.88: LACP: 2 x 1Gb/s |
PERC H700 RAID Controller with 6 600GB 10K SAS (2.5") in a RAID 10 with / (150GB) /boot (1GB) swap (8GB) /db01 (1.5TB) |
rh-mysql57-mysql-server UCM monitoring node? |
BCF | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
February 2012 (inherited from RACF in 2018) | |
| fc4 | IBM System x3650 M3 -[7945AC1]- | Sc.Linux 7.x | 2x Intel Xeon E5649 (Hex-core, 2.53GHz, 12MB cache, HT available but disabled) | 96GB + 24GB swap | 130.199.148.89: LACP: 2 x 1Gb/s |
ServeRAID M1015 SAS/SATA Controller 4x 300GB SAS 15K RPM 2.5" drives in a RAID 10 with: /boot: 1GB /: 120GB swap: 24GB /db01: 411GB |
3336: rh-mysql57-mysql-server, File Catalog slave | BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) SKM |
August 2011 | |
| Dell PowerEdge R310 | RHEL Workstation 7.x (64-bit) | Intel Xeon X3460 (quad core) 2.8GHz, w/HT | 8GB + 6GB swap | 130.199.162.175: 1Gb/s |
4 software RAID arrays spread over four identically partitioned 2 TB SATA disks: swap: 6 GB, RAID 10 /boot: xfs, 236 MB, RAID 1 /: xfs, 46 GB, RAID 5 /export: xfs, 5.5 TB, RAID 5 |
80, 443: former primary online web server (replaced by ovirt virtual machine in late 2017) | DAQ |
mdmonitor (starsupport) smartd (no) disk space mon. (no) Ganglia (yes) Osiris (starsupport) LogWatch (no) SSH Key Mgmt. (yes) DB start-up scripts (N/A) |
December 2010 | online Ganglia gmetad and web interface OCS Inventory Tomcat for ESL and SUMS scheduler stats NFS server for online web content generation |
|
| stardns1 | Dell PowerEdge SC440 | Sc.Linux 6.x (64-bit) | Dual Core Intel Pentium D 2.80GHz | 2GB + 4GB swap | 130.199.60.150: 1Gb/s | One 200 GB and one 250 GB SATA disk, partitioned identically (so the larger disk is not fully used): |
53: BIND (named, DNS server)
|
DAQ | December 2006 | secondary DNS server, supplementing daqman and onlldap (slave to daqman for all zones) | |
| sun (aka drupal and www) | Dell PowerEdge R610 | RHEL WS 6.x (64-bit) | Quad Core Intel Xeon E5520, 2.26GHz, 8M cache, w/HT | 12GB + 10GB swap | 130.199.59.200: 1Gb/s |
Six 15K SAS drives of 73GB each on a PERC 6/i integrated (LSI megaraid) controller. first two are in a RAID 1, which contains /boot, / and swap (8GB) remaining four are in RAID 5 mounted under /data (200GB) |
80, 443: STAR primary webserver 25: postfix (SMTP server) |
BCF |
mdmonitor (N/A - HW RAID) smartd (starsupport) disk space mon. (WB) Ganglia (yes) Osiris (starsupport) LogWatch (no) SSH Key Mgmt. (yes) DB start-up scripts (N/A) |
July 2009 | STAR Webserver, eg: -- Drupal -- RT -- Ganglia STAR Hypernews |
| sunbelt | Penguin Relion 2600SA |
RHEL Workstation 6.x (64-bit) | 2x Intel Xeon E5335 (Quad-core, 2.00GHz, 8MB cache) | 16GB + 4GB swap | 130.199.59.199: 1Gb/s |
/boot 200MB RAID1 /db01 on 3.3TB RAID5 4GB swap on RAID5 array Five 750GB, 7200 RPM SATA - RAID 5. Plus one spare 750GB (6 disks total) |
BCF |
mdmonitor (WB, MA, DA) smartd (WB, MA, DA) disk space mon. (WB, DA) Ganglia (yes) Osiris (WB, MA) LogWatch (WB) SSH Key Mgmt. (yes) DB start-up scripts (yes) |
August or November 2007 | sun Webserver & MYSQL emergency backup use | |
| stargw3 | Dell Precision WorkStation T3400 | Sc.Linux 6.x (64-bit) | Intel Core2 Quad CPU Q9550 @ 2.83GHz | 8GB + 6GB swap | 130.199.60.93: 1Gb/s | Two 500GB SATA drives partitioned identically with RAID 1 arrays for: /boot: 239 MB, ext4 /: 453 GB, ext4 swap: 6GB |
22: OpenSSH server 9619-9620: Condor-CE |
DAQ | May 2009 | Online Grid gatekeeper | |
| stargw4 | Dell OptiPlex 755 | Sc.Linux 6.x (64-bit) | Intel Core2 Duo CPU E8400 @ 3.00GHz | 6GB + 6GB swap | 130.199.60.74: 1Gb/s | One 250GB and one 400GB SATA drive. The drives are partitioned identically with RAID 1 arrays (so only 250 GB is being used from the 400 GB disk): /boot: 500MB, ext4 /: 223 GB, ext4 swap: 6GB |
22: OpenSSH server | DAQ | January 2009 | SSH gateway to starp, part of "stargw.starp.bnl.gov" DNS round-robin | |
| stargw5 | Dell OptiPlex 755 | Sc.Linux 6.x (64-bit) | Intel Core2 Duo CPU E8500 @ 3.16GHz | 4GB + 6GB swap | 130.199.60.76: 1Gb/s | Two 160 GB SATA drives partitioned identically with RAID 1 arrays: /boot: 500MB, ext4 /: 141 GB, ext4 swap: 6GB |
22: OpenSSH server | DAQ | September 2008 | SSH gateway to starp, part of "stargw.starp.bnl.gov" DNS round-robin | |
| onlldap | Dell PowerEdge R310 | Sc.Linux 6.x (64-bit) | Intel Xeon X3440 (quad-core) @ 2.53GHz | 8GB + 8GB swap | 130.199.60.57: 2Gb/s (bonded 1Gb/s NICs) | Four 1.2TB SAS (10K, 2.5") HDD, identically partitioned with RAID arrays: /boot: 388MB, ext4, RAID1 /: 118GB, ext4, RAID5 /ldaphome: 3.1TB, ext4, RAID5 swap: 8GB, RAID1 |
53: named (BIND/DNS) NFS NIS |
DAQ | December 2011 | Online Linux Pool home directory NFS server online NIS server master |
|
| onlam3 | Dell PowerEdge R310 | Sc.Linux 6.x (64-bit) | Intel Xeon X3440 (quad-core) @ 2.53GHz | 8GB + 8GB swap | 130.199.60.153: 1Gb/s | Four 1.2TB SAS (10K, 2.5") HDD, identically partitioned with RAID arrays: /boot: 388MB, ext4, RAID1 /: 118GB, ext4, RAID5 /ldaphome: 3.1TB, ext4, RAID5 swap: 8GB, RAID1 |
DAQ | December 2011 | backup Online Linux Pool home directories (cron'ed rsyncs) online NIS server slave online HTCondor Central Manager (collector/negotiator) |
||
| cephnfs | |||||||||||
| dean and dean2 | oVirt Virtual Machines | ||||||||||
| ovirt1, ovirt2, ovirt3 | |||||||||||
| onlcs | |||||||||||
| onlcs2 | |||||||||||
| onlhome | |||||||||||
| onlhome2 |
There is a fairly comprehensive monitoring system for the database servers at http://online.star.bnl.gov/Mon/
Notes about the health and configuration monitoring items listed in the table:
(If a particular tool notifies anybody directly (email), then the initials of the notified parties are included.)
Failing disks and filling disks have led to most of the db problems that this writer is aware of. Towards that end, we have several basic monitoring tools:
1. smartd -- if it starts indicating problems, the safest thing to do is replace the disk. However, SMART frequently assesses a disk as healthy when it is not. Also, the configurations in use have yet to be demonstrated to actually detect anything - I've no way to simluate a gradually failing disk. Also, SMART's abilities and usefulness are highly dependent on the disk itself - even 2 similar disks from the same manufacturer can have very different SMART capabilities. In any case, if we do have more disk failures, it will be interesting to learn if smartd gives us any warning. At this point, it is a bit of crossing-the-fingers and hoping. Any warning is a good warning...
2. mdmonitor or MegaRAID Storage Manager -- monitors software or hardware RAID configurations.
3. disk space monitoring -- We have a perl disk space monitoring script run via cron job. The iniital warning point is any partition more than 90% full.
Other monitoring and configuration details:
Ganglia -- doesn't need much explanation here.
Osiris -- change detection system, in the manner of TripWire, but with additional details that can be monitored, such as users and network ports.
SSH Key management -- doesn't need much explanation here.
Security
This section contains references to database security-related topics like security scan information, access to db from outside of BNL firewall, user account privileges etc.
DB & Docker
Docker-based STAR database installations and related tools
1. Offline Databases
Non-replicated installation of the STAR database service could be achieved using the interactive script attached to this page. It is "offline-database-docker.sh", renamed to .txt for the attachment security reasons. Replicated offline database slave installation script is in plans.Interactive installation script will do the following:
- verify that docker package is installed in the system (as well as other needed packages)
- download mysql 5.7 image from dockerhub
- download STAR offline db snapshots from the www.star.bnl.gov web site into the specified db data directory
- start docker container using the downloaded db snapshot
2. Online Databases
Currently, online databases ( :3501, :3502, :3503, :3606 ) are installed into docker container manually. Nodes onldb3.starp and onldb4.starp have been upgraded to SL7, and equipped with dockerized versions of the online databases (mysql 5.1) along with the standard setup of the offline database (mysql 5.7). Old database (5.1) has been installed via docker to ease the maintenance of the databases and to prevent the mix of old/new mysql libraries and system level.Dockerized DB installation procedure is described below:
- verify that fresh docker-ce package is installed and is running, if not - install it and run docker service
- install mysql 5.1 image from dockerhub via "docker pull <image-name>" command
- stop existing db slave at some existing/donor db slave node, copy its data files to the target node, /db01/online/<port>/data directory, start existing/donor slave again
- change ownership of /db01/online/<port>/data files to mysql:mysql using "chown -R /db01/online/*"
- rename master.info file into master.info.old, remove replication-related logs and files
- start container from mysql 5.1 image, having proper mapping of /db01/online/<port>/data to the /var/lib/mysql path inside of the container, and port mapping (i.e. 3501:3306 means "map internal port 3306 to external port 3501).
- open bash shell inside of the container, connect to 127.0.0.1:3306 db instance, verify that all databases are seen via "show databases", exit mysql and shell (exit container)
- tweak my.cnf file (see attached sample) to your liking, including server-id change, then copy this file to the /etc/my.cnf location inside of the contaner (see example docker command below).
- stop container, then start it again. Open up bash shell inside of the container, connect to the database as root, verify that it actually found /etc/my.cnf and server-id variable is properly set.
- use the information from the master.info.old file to initialize replication slave (CHANGE MASTER TO...), then start replication (START SLAVE). Verify that both replication threads are running and there are no errors (SHOW SLAVE STATUS \G). Exit mysql and container
- make sure that docker is set to auto-start or tell systemd to start it automatically via "systemctl enable docker"
- make sure that docker containers are started automatically upon docker start, via "docker update --restart=always <container-id>" command
NOTES:
- allow db access after the initial setup: $mysql> grant select on *.* to ''@'%';
- run usual 'CHANGE MASTER TO ...' after start
3. Helpful list of Docker commands:
# list all running containers
$> docker container list
# stop container
$> docker stop <container-id>
# start container
$> docker start <container-id>
# fetch MySQL 5.1 image from dockerhub:
$> docker pull vsamov/mysql-5.1.73
# init container from image, run it, arrange port mapping and data directory mapping:
$> docker run --name <container-name> -v /db01/online/3501/data:/var/lib/mysql -p 3501:3306 -e MYSQL_ROOT_PASSWORD='<pass>' -d vsamov/mysql-5.1.73:latest
# open bash shell inside of the running container
$> docker exec -it <container-name> bash
# add my.cnf to the running container to allow replication (set server-id first!):
$> docker cp ./my.cnf <container-id>:/etc/my.cnf
# set running container to auto-start upon boot:
$> docker update --restart=always <container-id>
Development
The links below lead to projects being worked on for the ongoing delevopment of the STAR database system.
Advanced DB Infrastructure : Hecate project
Hecate : integrated db infrastructure project
- Statistics Agent (MySQL) - collects CPU, RAM, Load, MySQL statistics and ships this to Pool Registry service via SOAP call (see attached src.rpm);
- Pool Registry service - keeps track of database pools (stats per node), provides load balancing and data transfer capabilities via exposed SOAP interface;
- Pool Manager - keeps track of database pools;
- Pool Registry Web UI - displays currently available pool list, node status, works as monitoring UI for collaboration;
- Fast In-Memory Cache - reduces the Pool Registry <-> Data Source Adapter communications burden;
- Data Source Adapter - announces Pools to Pool Registry, converts "generic" requests for datasets into db-specific commands, sends serialized data back to Pool Registry;
- (de)serialization Factory - converts dataset requests into DB queries, serializes DB response;
- DB native cache - provides caching capabilities, native to DB used in Pool;
- Local Disk Cache - persistent local cache
- Client Application - makes requests for data, using SOAP calls to Pool Registry. Data is fetched from either local or remote pool, transparently.
- Two-way db access - direct local db access interface + distributed data access interface;
- Local Load Balancing Interface - direct db access interface requires local load balancing information, retrieved from Pool Registry;
- Local Disk Cache - persistent local cache, reduces the Client App <-> Pool Registry communications burden;

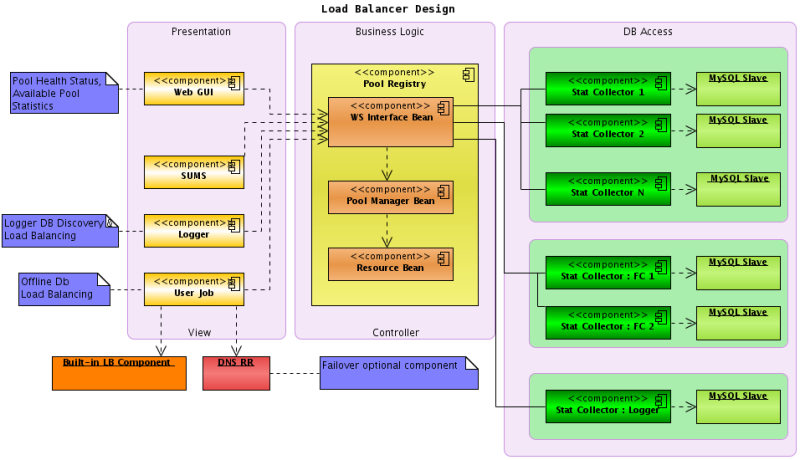
Archive: unsorted documents
Temporary placeholder for two presentations made on :
a) Online data processing review
b) FileCatalog performance improvement
Please see attached files
Bridging EPICS and High-Level Services at STAR
Bridging EPICS and High-Level Services at STAR
Outline:
- Introduction: STAR, EPICS, MQ and MIRA/DCS
- R&D Topics
- Integration of EPICS, RTS and DAQ using MIRA
- Remote Access Capabilities (web+mobile)
- Advanced Alarm Handler
- Historical Data Browser
- Experiment Dashboard
- Advanced Data Archiver: Pluggable Storage Adapters
- SQL: MySQL
- DOC: MongoDB
- NoSQL: HyperTable
- Complex Event Processing
- Esper Engine
- WSO2 middleware
- Summary and Outlook
- Figures
1. General Concepts: STAR, EPICS, MQ and DCS/MIRA
An acronym for the Solenoidal Tracker At RHIC (Relativistic Heavy Ion Collider), STAR detector tracks thousands of particles produced by ion collision, searching for signatures of a state of matter called the quark-gluon plasma (QGP), a form that is thought to have existed just after the Big Bang, at the dawn of the universe. A primary goal of STAR is to bring about a better understanding of the universe in its earliest stages, by making it possible for scientists to better understand the nature of the QGP. The STAR collaboration consists of over 500 scientists and engineers representing 60 institutions in 12 countries. As the size of the collaboration and the scope of its work continues to grow, so does the challenge of having the computing power and data processing resources to carry out that work efficiently.STAR's detector control system (also referred as Slow Controls) is based on EPICS toolkit. EPICS is a set of Open Source software tools, libraries and applications developed collaboratively and used worldwide to create distributed soft real-time control systems for scientific instruments such as a particle accelerators, telescopes and other large scientific experiments. The STAR experiment started in 1999, with just one Time-Projection Chamber and a few trigger detectors, but today it is equipped of 18 subsystems. Initially, STAR Slow Control system had 40,000 control variables, now it is expanded to over 60,000 variables and this list is still growing due to the RHIC II upgrade, beam energy scan program, and possible upgrade to eRHIC in future. STAR had just 120 types of structures to migrate to the calibrations database at the early days of the experiment, and we now migrate over 3,000 types of structures annually. STAR’s Data Acquisition (DAQ) – physics data taking component – was upgraded three times, adding one order of magnitude to the rates each time.
STAR’s Messaging Interface and Reliable Architecture framework (MIRA), was created as an attempt to improve meta-data archiver operations in 2010. It relies on an advanced message-queuing middleware, which provides the asynchronous, payload-agnostic messaging, and has adapters to get data from EPICS- and CDEV-based data sources. We have selected AMQP as a messaging middleware standard for High-Level services, as well as MQTT for low-level intra-service communications. It allowed us to design a loosely coupled, modular framework architecture, resulting in a scalable service, suitable for a highly concurrent online environment. During the deployment validation phase in 2010, just three subsystems used the MIRA framework. By 2014, all eighteen subsystems were completely integrated, with over sixty collector services deployed and continuously monitored by the framework. The total number of messages passing through the system reached three billion messages per year, with rates varying between one hundred and fifty messages per second to over two thousand messages per second. MIRA provided STAR with a solution to handle the growing number of channels (x15), and data structures (x25), allowing smooth operation during Runs 10-15. In 2014 we have extended MIRA with the stream-based Complex Event Processing capability, which successfully passed our tests. A few alarms implemented for Run 14 saved months of work for the core team and collaborators.
The MIRA framework is still evolving. In near future, we are planning to add features, commonly encountered in the Detector Control Systems domain: experiment workflow and hardware control, as well as many High-Level Services, extending and generalizing the functionality of the underlying framework(s). This document is focused on the proposed R&D related to futher development of MIRA framework and related services.
2. R&D Topics
We expect STAR to double the number of channels in the next five years, hence, system scalability is our primary objective. To allow seamless migration from wide variety of existing legacy hardware to the modern detector control equipment, at the same time keeping the existing Detector Control system based on EPICS fully operational to avoid interruption of service, we propose a gradual functionality upgrade of existing tools and services. This means, our primary objective is to extend existing services like experiment's EPICS-based Alarm Handler, Meta-data Collectors, RTS- and DAQ-components and to provide improved ways to orchestrate this growing set of services.2.1 Integration of EPICS, RTS and DAQ using MIRA
The intent to integrate vide variety of STAR Online services is driven by the growth of the STAR experiment's complexity, and greatly increased data processing rates. We have identified the requirements for the software infrastructure, desired to maintan STAR for the next decade. The upgrade team has collected the following key demands from collaborational users and detector experts: Scalable Architecture, Low-overhead Inter-operable Messaging Protocol, Payload-agnostic Messaging, Quality of Service, Improved Finite State Machine, Real-time, web and mobile-friendly Remote Access. While some of these features are already covered by by MIRA framework, others require R&D studies to accomplish our goals.2.2 Remote Access Capabilties
With web and mobile-based data access and visualization, MIRA, as the Detector Control framework, can provide data when and where the user needs it, and tailor that data for specific user requirements. This will lead to the rapid sharing, knowledge creation, engaged users, and more opportunities for the efficient scientific data processing. As operators become more fully engaged, they are apt to grow their involvement, contributing in unexpected ways that could ultimately decrease operational overhead.Advanced Alarm Handler
Due to the geographically distributed nature of STAR collaboration users and detector experts, one of the highly demanded upgrade targets is the Alarm Handler improvement. It is desired to provide a real-time, web (and/or mobile) version of the existing alarm handler application, which is currently based on EPICS-MEDM interface. To accomplish this task, we need to investigate the following opportunities:
(a) bi-directional propagation of alarm messages to/from EPICS to MQ/MIRA
(b) create a web/mobile interface, resemblng the existing MEDM-based Alarm Handler, keeping the overall look and feel to reduce the learning curve for the detector operators and subsystem experts
Estimated Efforts: 6 months / 1 FTE (2 x 0.5)
Historical Data Browser
Both EPICS and MIRA framework have their versions of Historical Archive interfaces. While EPICS Archiver provides a detailed access to all meta-data collected by the experiment, and MIRA's interface is appraised by the users for an easy categorization and expanded set of plotting features, there is a demand for the user-customizable interface which may/should include scripting features for advanced users.
Estimated Efforts: 4 months / 0.5 FTE
Experiment Dashboard
The process of unification of STAR's components leads to the need of the creation of Experiment's Dashboard (EDash), which will provide a high-level summary of the activies happening in STAR Online domain. EDash will serve as a single entry-point for the aggregated status summaries coming from Slow Control System, Data Acquisition System, Run-Time System and other systems integrated via MIRA messaging capabilities.
Estimated Efforts: 8 months / 0.5 FTE
Images

Figure 1. Component diagram for MQ-based Alarm Handler. Green components - existing infrastructure. Pink components - to be developed in a course of this R&D. Blue components - existing EPICS services, serving as data source for the test bed.
C++ DB-API
Work in progress. Page is located here .
Introduction
| The purpose of the C++ API is to provide a set of standardized access methods to Star-DB data from within (client) codes that is independent of specific software choices among groups within STAR. The standardized methods hide the "client" code from most details of the storage structure, including all references to the low-level DB infrastructure such as (My)SQL query strings. Specifically, the DB-API reformulates requests for data by name, timestamp, and version into the necessary query structure of the databases in order to retrieve the data requested. None of the low-level query structure is seen by the client.
The API is contained withing a shared library StDbLib.so. It has two versions built from a common source. The version in Offline (under $STAR/lib) contains additional code generated by "rootcint" preprocessor in order to provide command line access to some methods. The Online version does not contain the preprocessed "rootcint" code. In addition to standard access methods, the API provides the tools needed to facilitate those non-standard access patterns that are known to exist. For example, there will be tasks that need special SQL syntax to be supplied by client codes. Here, a general use C++MySQL object can be made available to the user code on an as needed basis. The following write-up is intended as a starting point for understanding the C++ API components. Since most clients of database data have an additional software-layer between their codes and the DB-API (e.g St_db_Maker in offline), none of these components will be directly seen by the majority of such users. There will, however, be a number of clients which will need to access the API directly in order to perform some unique database Read/Write tasks. Click here To view a block diagram of how the C++ API fits general STAR code access. Click here To view a block diagram of how the C++ API classes work together to provide data to client codes The main classes which make up the C++ DB-API are divided here into four categories.
|
Access Classes
StDbManager | StDbServer | tableQuery & mysqlAccessor | StDbDefs
| StDbManager: (Available at Root CLI)
The StDbManager class acts as the principle connection between the DB-API and the client codes. It is a singleton class that is responcible for finding Servers & databases, providing the information to the StDbServer class in order that it may connect with the database requested, and forwarding all subsequent (R/W) requests on to the appropriate StDbServer object. Some public methods that are important to using the DB-API via the manager:
Some public methods that are primarily used internally in the DB-API:
The StDbServer class acts as the contact between the StDbManager and the specific Server-&-Database in which a requested data resides. It is initialized by the StDbManager with all the information needed to connect to the database and it contains an SQL-QueryObject that is specifically structured to navigate the database requested. It is NOT really a user object except in specific situations that require access to a real SQL-interface object which can be retrieved via this object. Public methods accessed from the StDbManager and forwarded to the SQL-Query Object:
The tableQuery object is an interface of database queries while mysqlAccessor object is a real implementation based on access to MYSQL. The real methods in mysqlAccessor are those that contain the specific SQL content needed to navigate the database structures. Public methods passed from StDbServer :
Not a class but a header file containing enumerations of StDbType and StDbDomain that are used to make contact to specific databases. Use of such enumerations may disappear in favor of a string lookup but the simple restricted set is good for the initial implementation.
|
Data Classes
| StDbTable: (Available at Root CLI)
The StDbTable class contains all the information needed to access a specific table in the database. Specifically, it contains the "address" of the table in the database (name, version, validity-time, ...), the "descriptor" of the c-struct use to fill the memory, the void* to the memory, the number of rows, and whether the data can be retrieved without time-stamp ("BaseLine" attribute). Any initial request for a table, either in an ensemble list or one-by-one, sets up the StDbTable class instance for the future data request without actually retrieving any data. Rather the database-name, table-name, version-name, and perhaps number of rows & id for each row, are assigned either by the ensemble query via the StDbConfigNode or simply by a single request. In addition, an "descriptor" object can also be requested from the database or set from the client code. After this initial "request", the table can be used with the StDbManager's timestamp information to read/write data from/to the database. if no "descriptor" is in the StDbTable class, the database provides one (the most recent one loaded in the database) upon the first real data access attempted. Some usefull public methods in StDbTable
StDbConfigNode: (Available at Root CLI) The StDbConfigNode class provides 2 functions to the C++ API. The first is as a container for a list of StDbTable objects over which codes can iterate. In fact, the StDbTable constructor need not be called directly in the user codes as the StDbConfigNode class has a method to construct the StDbTable object, add it to its list, and return to the user a pointer to the StDbTable object created. The destructor of the StDbConfigNode will delete all tables within its list. The second is the management of ensembles of data (StDbTables) in a list structure for creation (via a database configuration request) and update. The StDbConfigNode can build itself from the database and a single "Key" (version string). The result such a "ConfigNode" query will be several lists of StDbTables prepared with the necessary database addresses of name, version, & elementID as well as any characteristic information such as the "descriptor" and the baseline attribute. Some usefull public methods in StDbConfigNode
|
Mysql Utilities
MysqslDb class provides infrastructure (& sometimes client) codes easy use of SQL queries without being exposed to any of the specific/particular implementations of the MySQL c-api. That is, the MySQL c-api has specific c-function calls returning mysql-specific c-struct (arrays) and return flags. Handling of these functions is hidden by this class.
Essentially there are 3 public methods used in MysqlDb
-
- // Accept an SQL string: NOTE the key "endsql;" (like C++ "endl;") signals execute query
- MysqlDb &operator<<(const char *c);
-
- // Load Buffer with results of SQL query
- virtual bool Output(StDbBuffer *aBuff);
- // Read into table (aName) contents of Buffer
- virtual bool Input(const char *aName,StDbBuffer *aBuff);
The StDbBuffer class inherits from the pure virtual StDbBufferI class & implements MySQL I/O. The syntax of the methods were done to be similar with TBuffer as an aid in possible expanded use of this interface. The Buffer handles binary data & performs byte-swapping as well as direct ASCII I/O with MySQL. The binary data handler writes all data in Linux format into MySQL. Thus when accessing the buffer from the client side, one should always set it to "ClientMode" to ensure that data is presented in the architecture of the process.
Public methods used in StDbBufferI
-
- // Set & Check the I/O mode of the buffer.
- virtual void SetClientMode() = 0;
- virtual void SetStorageMode() = 0;
- virtual bool IsClientMode() = 0;
- virtual bool IsStorageMode() = 0;
-
- // Read-&-Write methods.
- virtual bool ReadScalar(any-basic-type &c, const char *aName) = 0;
- virtual bool ReadArray(any-basic-type *&c, int &len, const char *name) = 0;
- virtual bool WriteScalar(any-basic-type c, const char * name) = 0;
- virtual bool WriteArray(any-basic-type *c, int len, const char * name) = 0;
-
- // Not impemented but under discussion (see Tasks List)
- virtual bool ReadTable(void *&c, int &numRows, Descriptor* d, const char * name) = 0;
- virtual bool WriteTable(void *c, int numRows, Descriptor* d, const char * name) = 0;
SSL + Compression check
STAR MySQL API: SSL (AES 128/AES 256), Compression tests.
IDEAS:
a) SSL encryption will allow to catch mysterious network problems eary (integrity checks).
b) Data compression will allow more jobs to run simultaneously (limited network bandwidth);
BFC chain used to measure db response time: bfc.C(5,"pp2009a,ITTF,BEmcChkStat,btofDat,Corr3,OSpaceZ2,OGridLeak3D","/star/rcf/test/daq/2009/085/st_physics_10085024_raw_2020001.daq")
time is used to measure 20 sequential BFC runs :
1. first attempt:
SSL OFF, COMPRESSION OFF : 561.777u 159.042s 24:45.89 48.5% 0+0k 0+0io 6090pf+0w
WEAK SSL ON, COMPRESSION OFF : 622.817u 203.822s 28:10.64 48.8% 0+0k 0+0io 6207pf+0w
STRONG SSL ON, COMPRESSION OFF : 713.456u 199.420s 28:44.23 52.9% 0+0k 0+0io 11668pf+0w
STRONG SSL ON, COMPRESSION ON : 641.121u 185.897s 29:07.26 47.3% 0+0k 0+0io 9322pf+0w
2. second attempt:
SSL OFF, COMPRESSION OFF : 556.853u 159.315s 23:50.06 50.0% 0+0k 0+0io 4636pf+0w
WEAK SSL ON, COMPRESSION OFF : 699.388u 202.783s 28:27.83 52.8% 0+0k 0+0io 3389pf+0w
STRONG SSL ON, COMPRESSION OFF : 714.638u 212.304s 29:54.05 51.6% 0+0k 0+0io 5141pf+0w
STRONG SSL ON, COMPRESSION ON : 632.496u 157.090s 28:14.63 46.5% 0+0k 0+0io 1pf+0w
3. third attempt:
SSL OFF, COMPRESSION OFF : 559.709u 158.053s 24:02.37 49.7% 0+0k 0+0io 9761pf+0w
WEAK SSL ON, COMPRESSION OFF : 701.501u 199.549s 28:53.16 51.9% 0+0k 0+0io 7792pf+0w
STRONG SSL ON, COMPRESSION OFF : 715.786u 203.253s 30:30.62 50.2% 0+0k 0+0io 4560pf+0w
STRONG SSL ON, COMPRESSION ON : 641.293u 164.168s 29:06.14 46.1% 0+0k 0+0io 6207pf+0w
Preliminary results from 1st run :
SSL OFF, COMPRESSION OFF : 1.0 (reference time)
"WEAK" SSL ON, COMPRESSION OFF : 1.138 / 1.193 / 1.201
"STRONG" SSL ON, COMPRESSION OFF : 1.161 / 1.254 / 1.269
"STRONG" SSL ON, COMPRESSION ON : 1.176 / 1.184 / 1.210
Compression check:
1. bfc 100 evts, compression ratio : 0.74 [compression enabled / no compression]. Not quite what I expected, probably I need to measure longer runs to see effect - schema queries cannot be compressed well...
First impression: SSL encryption and Data compression do not significantly affect operations. For only ~15-20% slow-down per job, we get data integrity check (SSL) and 1.5x network bandwidth...
WORK IN PROGRESS...
Addendum :
1. Found an interesting article at mysql performance blog:
http://www.mysqlperformanceblog.com/2007/12/20/large-result-sets-vs-compression-protocol/
"...The bottom line: if you’re fetching big result sets to the client, and client and MySQL are on different boxes, and the connection is 100 Mbit, consider using compression. It’s a matter of adding one extra magic constant to your application, but the benefit might be pretty big..."
Database types
DB-Type Listing
listed items are linked to more detailed discussions on:
- Description & Use Cases
|
Conditions Database
| Description:
The Conditions Database serves to record the experimental running conditions. The database system is a set of "subsystem" independent databases written to by Online "subsystems" and used to develop calibration and diagnostic information for later analyses. Some important characteristics of the Conditions/DB are:
There are essentially 4 types of use scenarios for the Conditions/DB. (1) Online updates: Each Online sub-system server (or subsystem code directly) needs the capability to update thier database with the data representing the sub-system operation. These updates can be triggered by a periodic (automated) sub-system snap-shots, a manually requested snap-shot, or an alarm generated recording of relevant data. In any of these cases, the update record includes the TimeStamp associated with the measurement of the sub-system data for future de-referencing. (2) Online diagnostics: The snap-shots, which may include a running histogram of Conditions data, should be accessible from the sub-system monitors to diagnose the stability of the control & detector systems and correlations between detector performance and system conditions. (3) Offline diagnostics: The same information as (2) is needed from Offline codes (running, for example, in the Online-EventPool environment) to perform more detailed analyses of the detector performance. (4) Offline calibrations: The conditions/DB data represent the finest grained & most fundamental set of data from which detector calibrations are evaluated (excepting, of course, for the event data). The Conditions data is input to the production of Calibration data and, in some cases, Calibration data may simply be the re-time-stamp of Conditions data by the time interval of the Calibration's stability rather than that of some automated snap-shot frequency. |
Configurations Database
| Description:
The Configuration Database serves as the repository of detector-hardware "set-points". This repository is used to quickly configure the systems via several standard "named" configurations. The important characteristics of the Configuration/DB are;
There are essentially 3 types of use scenarios for the configurations database. (1) Online Registration: A configuration for a sub-system is created through the Online SubSystem Server control by direct manipulation of the subsystem operator. That is, a "tree-structured" object catalog is edited to specify the "named" objects included in the configuration. The individual named objects can, if new, have input values specified or, if old, will be loaded as they are stored. The formed configuration can then be registered for later access by configuration name. There exists an Online GUI to perform these basic tasks (2) Online Configuration: Once registered, a configuration is made available for enabling the detector sybsystem as specified by the configuration's content. The Online RunServer control can requesta named configuration under the Online protocols and parse the subsytem Keys (named collection) to the subsystem servers which access the Configurations/DB directly. (3) Offline use: In general Offline codes will use information derived from the conditions/DB to perform reconstruction/analysis tasks (e.g. not the set-points but the measured points). However, some general information about the setup can be quickly obtained from the Configurations/DB as referenced from the RunLog. This will tell, for example, what set of detectors were enabled for the period in question. |
Calibrations Database
| Description:
The Calibration/DB contains data used to correct signals from the detectors into their physically interpretable form. This data is largely derived from the conditions/DB information and event data by reformulating such information into usefull quantities for reconstruction &/or analysis tasks. There are essentially 3 types of use scenarios for the calibrations database. (1) Offline in Online: It is envisioned that much of the calibration data will be done produced via Offline processing running in the Online Event-Pool. These calibration runs will be fed some fraction of the real data produced by the DAQ Event-Builder. This data is then written or migrated into the Calibration/DB for use in Offline production and analyses. (2) Offline in Offline: Further reprocessing of the data in the Offline environment, again with specific calibration codes, can be done to produce additional calibration data. This work will include refinements to original calibration data with further iterations or via access on data not available in the Online Event Pool. Again the calibration data produced is written or migrated to the calibration database which resides in Offline. (3) Offline reconstruction & analyses: The calibration data is used during production and analysis tasks in, essentially, a read-only mode. |
Geometry Database
| Description:
The Geometry database stores the geometrical description of the STAR detectors and systems. It is really part of the calibration database except that the time-constant associated with valid entries into the database will be much longer than typical calibration data. Also, it is expected that many applications will need geometrical data from a variety of sub-systems while not needing similar access to detector-specific (signal) calibration data. Thus the access interface to the geometry database should be segragated from the calibration database in order to optimize access to its data. There are a few generic categories of geometry uses that while not independent may suggest indecate differen access scenarios. (1) Offline Simulations: (2) Offline Reconstruction: (3) Offline Analyses & Event Displays: |
RunLog Database
| Description:
The RunLog holds the summary information describing the contents of an experimental run and "pointers" to the detailed information (data files) that are associated with the run. A more complete description can be found on the Online web pages. (1) Online Generation: The RunLog begins in Online which the run is registered, stored when the run is enabled, and updated when the run has ended. Furhter updates from Online may be necessary e.g. once verification is made as to the final store of the event data on HPSS. (2) Online (& Offline) Summaries: The RunLog can be loaded and properties displayed in order to assertain progress toward overall goals that span Runs. (3) Offline Navigation : The RunLog will have a transient representation in the offline infrustructure which will allow the processes to navigate to other database entities (i.e. Configurations & Scalers) |
Distributed Control System - Conditions
Distributed Control System - Conditions
1. Intro: Conditions Database protocols using MQ-powered services. Typical workflow: sensor is booted, then it requests initial values from Conditions database, then it starts publishing updates on Conditions. At the same time, Web UI user may request to change Conditions for a specific sensor, and receive real-time updates on changes made by sensor.
2. Participating entities: Sensor, Storage service, Web UI (+ mq broker, mysql database)
2.1 Physical deployment details:
- Sensor = code running in the online domain (daq network), TBD
- Storage Service = C++ daemon, storage adapter handling MySQL (+MongoDB later on). Runs at onl16.starp.bnl.gov under 'dmitry' account
- Web UI = can be run from anywhere, given that it has access to https://dashboard1.star.bnl.gov/mqtt/ for mqtt proxy service. E.g. https://dashboard1.star.bnl.gov/dcs/ . Allows to read and update (time-series versioned, so all updates are inserts) predefined Conditions structures.
- MQ Broker = multi-protocol broker (Apache Apollo), running at onl16.starp.bnl.gov
- MySQL service, holding Conditions database. For now, online conditions database is used. It runs at onldb.starp.bnl.gov:3501, Conditions_fps/<bla>
3. Protocols:
- transport protocol: MQTT (sensors, storage), WebSocket + MQTT (web ui)
- message serialization protocol: JSON
4. Data Request API:
- REGISTER, SET, GET, STORAGE, SENSOR
(see examples below the service layout image)

4.1 Example: to SET value (received by sensor and storage) :
topic: dcs/set/Conditions/fps/fps_fee
message:
{
dcs_id: "<client_unique_id>",
dcs_uid: "<authenticated_login>",
dcs_header: ["field1", "field2", ... "fieldN"],
dcs_values: {
<row_id1>: [ value1, value2, ... valueN ],
...
<row_idN>: [ value1, value2, ... valueN ]
}
}
NOTE: one can set any combination of fields vs row ids, including one specific field and one specific row id.
4.2 Example: to GET values:
topic: dcs/get/Conditions/fps/fps_fee
message:
{
dcs_id: "<client_unique_id>",
dcs_uid: "<authenticated_login>",
dcs_header: ["field1", "field2" ... "fieldN"], // alternatively, ["*"] to get all available fields
dcs_values: {
"1": true, // <-- request row_id = 1, alternatively, do dcs_values = {} to get all avaliable rows
"2": true,
...
"N": true
}
}
NOTE: one can request any combination of fields vs row ids, including one specific field and one specific row id.
4.3 Example: subscribe to response from storage:
topic: dcs/storage/Conditions/fps/fps_fee
message:
{
dcs_id: "<client_unique_id>",
dcs_uid: "<authenticated_login>",
dcs_header: ["field1", "field2", ... "fieldN"],
dcs_values: {
<row_id1>: [ value1, value2, ... valueN ],
...
<row_idN>: [ value1, value2, ... valueN ]
}
}
DCS Interface & Behaviors
1. Hardware / PLC commands:
Format: COMMAND ( parameter1, parameter2, ... parameterN) = <description>
PV GET / SET:
- GET ( <list of PV names>, <reply-to address>)
- Requests cached value information.
- Reply instantly with the value from the in-memory copy, with name-value pairs for the requested PVs.
- If reply-to address exists, reply to the private address instead of a public channel.
- SET ( <list of PV name-value pairs> )
- Set values for the provided channels, if allowed to by internal configuration
PV SCANS:
- SCAN ( <list of PV names>, <group_reply = true|false>, <time_interval>, <reply-to address> )
- Requests one-time (if time_interval = 0) or periodic (if time_interval != 0) scan of live values.
- Register SCAN in a scan list: read out live values one by one.
- If group = true, reply once when all channels are scanned, otherwise send out individual updates.
- Reply instantly with registered SCAN_ID. If reply-to address provided, reply to the private channel instead of a public one.
- SCAN_CANCEL ( <SCAN_ID> )
- cancel existing scan for SCAN_ID if exists
- SCAN_MODIFY ( <SCAN_ID>, <group_reply = true|false>, <time_interval = milliseconds>, <reply-to address> )
- modify parameters of the defined scan
INFORMATIONAL:
- INFO_SYSTEM ()
- return the following:
- current state of the HW;
- configuration information for this HW;
- return the following:
- INFO_PV ( < pv_name = undefined | list of pv names > )
- if < pv_name = undefined >, return list of all configured PVs and their types;
- INFO_SCAN ( < scan_id = undefined | list of scan_ids > )
- if < scan_id = undefined > return list of all configured periodic scans from scan list, otherwise return specified scan details;
- if < scan_id = undefined > return list of all one-time scans remaining in a scan queue, otherwise return specified scan details;
OPERATIONAL:
- RESET ()
- clear all internal state variables, re-read configuration, restart operations from clean state.
- REBOOT ()
- request physical reboot of the device, if possible.
- reply with "confirmed" / "not available"
- ON ()
- request power up the device, if possible
- reply with "confirmed" / "not available"
- OFF ()
- request power off the device, if possible
- reply with "confirmed" / "not available"
2. HW internal organization:
NOTE: global variables, related to controller operations
- CONFIGURATION = list of [ < pv_name = STR > , <pv_type = INT | DBL | STR > , <pv_initial_value> , <pv_current_value> , <pv_flag = READ | WRITE | RW > ]
- i.e. list of controlled parameters;
- SCAN_LIST = list of < scan_item = [ ID, list of PV names, group = true | false, time_interval != 0, reply-to address, last_scan_ts ] >
- List/vector of registered periodic scans;
- SCAN_QUEUE = queue of <scan_item = [ ID, list of PV names, group = true | false, time_interval = 0, reply-to address ] >
- Queue of requested one-time scans;
- DEVICE_STATE = < int = ON | OFF >
- current global state of the controlled device
- DEVICE_OPERATION = < IDLE | GETTING | SETTING | SCANNING | POWERING_UP | POWERING_DOWN | RESETTING | REBOOTING >
- device current operation flag
- DEVICE_ID = < char_string >
- unique id of the controlled device
3. HW internal operations:
NOTE: implemented using FSM
I. BOOT sequence
- INITIALIZE core parameters (device info, scan list/queue, device state)
- POPULATE list of controlled variables
- SETUP persistent scans, if requested
- GO to OPERATING sequence
II. OPERATING sequence
- LISTEN for incoming commands for <N> microseconds (aka IDLE)
- if NETWORK ERROR occurs = pause OPERATING sequence, try RECONNECT to MQ in <N> seconds
- if RECONNECT succeeded = resume OPERATING sequence
- else GO to (1.1)
- IF external <comand> received within time interval, call <command> processing code
- ELSE proceed with <scan_queue> and <scan_list> processing
- LOOP to (1)
III. SHUTDOWN sequence
- CLEANUP internal state
- DESTROY internal objects
- DISCONNECT from MQ service
- call POWER OFF routine
DCS protocol v1
DCS protocol v1
modeled after RESTful principles and Open Smart Grid Protocol
courtesy of Yulia Zulkarneeva, Quinta Plus Technologies LLC
I. TOPIC: <site_uid> / <protocol> / <version> / <method> / <Process_Variable_URI>
topic example: BNLSTAR / DCS / 1 / GET / Conditions / fps / fee
II. MESSAGE contents: request body, encoded as JSON/txt or MsgPack/bin formats
a) message example: {
"uid": "<client-uid>",
"header": [ <column_name_A>, <column_name_B> ],
"values": {
"<offset_0>" : [ <value_for_A>,<value_for_B> ]
"<offset_N>" : [ <value_for_A>,<value_for_B> ]
}
}
..or..
b) message: {
"uid": "<client-uid>",
"values": {
"<column_name_A>.<offset_A>" : 3,
"<column_name_B>.<offset_B>.<offset_B_at_bit_level>" : 1
}
}
example: BNLSTAR / DCS / 1.0 / GET / Conditions / fps / fee
message: { "uid": "unique-identifier-of-the-client", "ts": 12345678 }
example: BNLSTAR / DCS / 1.0 / SET / Conditions / fps / fee
message: { "uid": "<client-uid>", "header": [A,B], "values": { "0" : [1,2] } }
message: { "uid": "<client-uid>", "values": { "A.0" : 1, "B.0" : 2 } }
III. METHODS
| METHOD | DESCRIPTION | NOTES |
|---|---|---|
| standard methods | ||
| GET | get latest entry => either storage or sensor may reply via personal REPLY | |
| PUT | store new entry | |
| POST | sensor entry change update | |
| DELETE | delete [latest] entry | |
| HEAD | request schema descriptor only, without data | |
| PATCH | modify schema descriptor properties | |
| OPTIONS | get supported methods | |
| extra methods | ||
| REPLY | personal reply address in REQUEST / RESPONSE pattern. Ex. topic: DCS / REPLY / <CLIENT_UID>. Example: COMMAND acknowledgements, GET replies | |
| COMMAND | commands from control system: ON / OFF / REBOOT / POWEROFF | |
| STATUS | retrieve status of the device: ON / OFF / REBOOT / POWEROFF / BUSY | |
Search capabilities
Search (essentially, Filter) Capabilities and Use-Cases
To request filtering of the result, special field could be added to the request body: "dcs_filter". Contents of the "dcs_filter" define the rules of filtering - see below.
-------------------------------------------------------------
[x] 1. Constraint: WHERE ( A = B )
dcs_filter: { "A" : B }
[x] 2. Constraint: WHERE ( A = B && C = "D" )
dcs_filter: { "A": B, "C": "D" }
[x] 3. Constraint: WHERE ( A = B || C = "D" )
dcs_filter: {
'_or': { "A": B, "C": "D" }
}
[x] 4. Constraint: WHERE ( A = B || A = C || A = D )
dcs_filter: {
"A": {
'_in': [ B, C, D ]
}
}
[x] 5. Constraint: WHERE ( A = B && ( C = D || E = F ) )
dcs_filter: {
"A": B,
"_or" : { C: D, E: F }
}
-------------------------------------------------------------
[x] 6.1 Constraint: WHERE ( A > B )
dcs_filter: {
A: { '_gt': B }
}
[x] 6.2 Constraint: WHERE ( A >= B )
dcs_filter: {
A: { '_ge': B }
}
[x] 7.1 Constraint: WHERE ( A < B )
dcs_filter: {
A: { '_gt': B }
}
[x] 7.2 Constraint: WHERE ( A <= B )
dcs_filter: {
A: { '_ge': B }
}
[x] 8. Constraint: WHERE ( A > B && A < C )
dcs_filter: {
A: { '_gt': B, '_lt': C }
}
-------------------------------------------------------------
...To Be Continued
Enhanced Logger Infrastructure
Enhanced Logger Infrastructure
Use-Case Diagram

Deployment Diagram

IRMIS
Irmis
Instalation Recipe
- install MySQL & setup (set admin password, set user, set user password, set database called irmis, etc)
- download and install Java (/home/sysuser/jre-1_5_0_09-linux-i586-rpm.bin)
- download and install Mysql connector/j (I installed that in /usr/java/jre1.5.0_09/lib)
- download and install irmis somewhere (I installed in /usr/local/irmisBase)
- download and install ant 1.6 (apache-ant-1.6.5-bin.zip in /usr/local/apache-ant-1.6.5/)
- setup MySQL:
- mysql -u root -p < ./create_aps_ioc_table.sql
- mysql irmis -u root -p < ./create_component_enum_tables.sql
- mysql irmis -u root -p < ./create_component_tables.sql
- mysql irmis -u root -p < ./create_pv_client_enum_tables.sql
- mysql irmis -u root -p < ./create_pv_client_tables.sql
- mysql irmis -u root -p < ./create_pv_enum_tables.sql
- mysql irmis -u root -p < ./create_pv_tables.sql
- mysql irmis -u root -p < ./create_shared_enum_tables.sql
- mysql irmis -u root -p < ./create_shared_tables.sql
- mysql irmis -u root -p < ./alter_aps_ioc_table.sql
- mysql irmis -u root -p < ./alter_component_tables.sql
- mysql irmis -u root -p < ./alter_pv_client_tables.sql
- mysql irmis -u root -p < ./alter_pv_tables.sql
- mysql irmis -u root -p < ./alter_shared_tables.sql
- mysql irmis -u root -p < ./populate_form_factor.sql
- mysql irmis -u root -p < ./populate_function.sql
- mysql irmis -u root -p < ./populate_mfg.sql
- mysql irmis -u root -p < ./populate_component_type_if_type.sql
- mysql irmis -u root -p < ./populate_base_component_types.sql
- mysql irmis -u root -p < ./populate_core_components.sql
- edit site.build.properties file to reflect the local configuration.
- db.connection.host=localhost
- db.connection.database=irmis
- db.connection.url=jdbc:mysql://localhost:3306/irmis
- db.trust-read-write.username=MySQL user name
- db.trust-read-write.password=MySQL user password
- irmis.codebase=http://localhost/irmis2/idt
- build irmis as described in the README file:
- cd db
- ant deploy
- cd apps
- ant deploy
- run irmis desktop:
- cd apps/deploy
- tar xvf irmisDeploy.tar
- java -jar irmis.jar
- untar various crawlers located at /usr/local/irmisBase/db/deploy as well as make whatever necessary local changes accordingly.
Load Balancer
---
Configuration File
Load Balancer Configuration File
Local Configuration:
This file is for sites that have a pool of database servers they would like to load balance between (e.g., BNL, PDSF).
This file should be pointed to by the environmental variable DB_SERVER_LOCAL_CONFIG.
Please replace the DNS names of the nodes in the pools with your nodes/slave. Pools can be added and removed with out any problems but the needs to be at least one pool of available slaves for general load balancing.
Below is a sample xml with annotations:
<!--Below is a pool of servers accessble only by user priv2 in read only mode
This pool would be used for production or any other type of operation that needed
exclusive access to a group of nodes
--!>
<Server scope="Production" user="priv2" accessMode="read">
<Host name="db02.star.bnl.gov" port="3316"/>
<Host name="db03.star.bnl.gov" port="3316"/>
<Host name="db04.star.bnl.gov" port="3316"/>
<Host name="db05.star.bnl.gov" port="3316"/>
</Server>
<!--Below is a pool of servers access by ANYBODY in read only mode
This pool is for general consumption
--!>
<Server scope="Analysis" accessMode="read">
<Host name="db07.star.bnl.gov" port="3316"/>
<Host name="db06.star.bnl.gov" port="3316"/>
<Host name="db08.star.bnl.gov" port="3316"/>
</Server>
<!--Below is an example of Pool (one in this case) of nodes that Only becone active at "Night"
Night is between 11 pm and 7 am relative to the local system clock
--!>
<Server scope="Analysis" whenActive="night" accessMode="read">
<Host name="db01.star.bnl.gov" port="3316"/>
</Server>
<!--Below is an example of Pool (one in this case) of nodes that is reserved for the for users assigned to it.
This is useful for a development node.
--!>
<Server scope="Analysis" user="john,paul,george,ringo" accessMode="read">
<Host name="db01.star.bnl.gov" port="3316"/>
</Server>
<!--Below is an example of Pool (one in this case) of nodes that is reserved for write. Outside of BNL, this should only be allowed on
nodes ONLY being used for development and debugging. At BNL this is reserved for the MASTER. The element accessMode corresponds
to an environmental variable which is set to read by default
--!>
<Server scope="Analysis" accessMode="write">
<Host name="robinson.star.bnl.gov" port="3306"/>
</Server>
</Scatalog>
The label assigned to scope does not matter to the code, it is for bookkeeping purposes only.
Nodes can be moved in and out of pools at the administrators discretion. A node can also be a member of more than one pool.
a list of possible features is as follows:
for Sever - attributes are:
- scope
- accessMode
- whenActive
- user
host - attributes are:
- name
- port
- machinePower
- cap
Machine power is a weighting mechanism - determining the percentage of jobs that an administrator wants to direct to a particular node. The default value =1, So
a machine power of 100 means most requests will go to that node also a machinePower of 0.1 means propotional to the other nodes very few requests will go to that node.
For example
<Server scope="Analysis" whenActive="night" accessMode="read">
<Host name="db1.star.bnl.gov" port="3316" machinePower = 90/>
<Host name="db2.star.bnl.gov" port="3316"/>
<Host name="db3.star.bnl.gov" port="3316" machinePower = 10/>
</Server>
says that node db1 will get most requests
db2 almost nothing (default value = 1)
db3 very few requests
Cap is a limit of connections allowed on a particular node
Please refer to the attached paper for detailed discussion about each of these attributes/features.

Load Balancer Connection
The load balancer makes its decision as to which node to connect to, based on the number of active connections on each node.
It will choose the node with the least number of connections.
In order to do this it must make a connection to each node in a group.
The load balancer will need an account on the database server with a password associated with it.
The account is:
user = loadbalancer
please contact an administrator for the password associated with the account.
631-344-2499
The load this operation creates is minimal.
so
something like
grant process on *.* to 'loadbalancer'@'%.bnl.gov' identified by 'CALL 631-344-2499';
of coarse the location should be local.
MIRA: Fake IOC Development
Minutes from the meeting ( 2016-05-16 )
Attendees: Jerome, Tonko, Dmitry A.Discussion Topic: MIRA upgrade related to the Run 17 TPC controls upgrade planned by Tonko
Brief summary: Tonko wants Dmitry to create a Fake EPICS IOC service in MIRA, which will allow to emulate the existing EPICS IOCs controllling TPC gating grid. Internally, this emulator will convert all EPICS requests into MQTT calls, which allows Tonko to use MIRA/MQTT functionality directly while keeping EPICS/MEDM TPC Control UI as is for the transition period.
=========================================================
1. Details:
Current conditions: TPC gating grid hardware is controlled by EPICS TPC IOC. Users issue commands using EPICS/MEDM graphical interface (desktop app).
Proposed upgrade: replace EPICS TPC IOC with new MIRA-compatible service developed by Tonko, while keeping EPICS UI functional until we come up with proper replacement, likely web-based MIRA interface.
Action Item: Dmitry needs to develop an emulator of EPICS IOC, which will transparently convert EPICS requests into MQTT/MIRA requests and vice versa.
Deadline: Tonko wants to see draft version implemented by December 2016, so we can test it before the Run 17. Final version (both DAQ side and Controls side) is expected to be delivered by the beginning of first physics events of Run 17.
Possible Show-stopper: Currently, MIRA is limited to two nodes - mq01,mq02. Both nodes serve multiple roles, and have the following set of services installed: MQTT server, AMQP server, MIRA EPICS->MQ collectors, CDEV->MQ collectors, MQ->DB logger, MQTT->WebSocket forwarding service. Functioning EPICS IOC emulator will require a permanent binding to EPICS-specific TCP/UDP ports, which may (TBC) prevent existing EPICS->MQ collectors from being functional as they also use those ports. If this suspicion is confirmed (Dmitry), then IOC emulator service will require a separate node to be provided.
2. Diagrams:
Existing MIRA setup (before) :
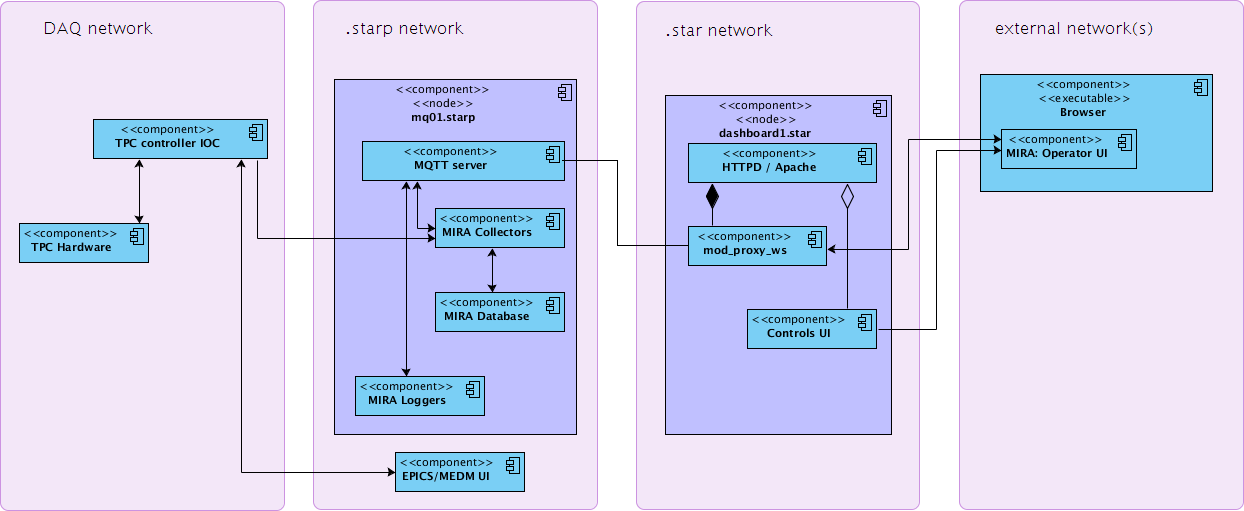
Proposed MIRA upgrade (after) :

Online API
---
PXL database design
Pixel Status Mask Database Design
I. Overall stats:
- 400 sensors (10 sectors, 4 ladders per sector, 10 sensors per ladder)
- 960 columns vs 928 rows per sensor
- 400 x 960 x 928 = 357M individual channels in total
II. Definitions :
PXL status may have the following flags (from various sources):
1. Sensors:
- good
- perfect
- good but hot (?)
- bad (over 50% hot/missing)
- hot (less than 5% hot?)
- dead (no hits)
- other
- missing (not installed)
- non-uniform (less than 50% channels hot/missing)
- low efficiency (num entries very low after masking)
- good
- bad (over 20% bad pixels hot)
- expect: ~30 bad row/columns per sensor
- good
- bad (hot fires > 0.5% of the time)
- what exactly is hot pixel? Is it electronic noise or just background (hits from soft curlers)?
- is it persistent across runs or every run has its own set of hot individual pixels?
- is it possible to suppress it at DAQ level?
1. Generic observations:
- PXL status changes a lot in-between runs, thus "only a few channels change" paradigm cannot be aplied => no "indexed" tables possible
- Original design is flawed:
- we do not use .C or .root files in production mode, it is designed for debugging purposes only and has severe limitations;
- real database performs lookups back in time for "indexed" tables, which means one has to insert "now channel is good again" entries => huge dataset;
- hardcoded array sizes rely on preliminary results from Run 13, but do not guarantee anything for Run 14 (i.e. what if > 2000 pixels / sector will be hot in Run 14?);
- uchar/ushort sensors[400]; // easy one, status is one byte, bitmask with 8/16 overlapping states;
- matches the one from original design, hard to make any additional suggestions here..
- observations:
- seems to be either good or bad (binary flag)
- we expect ~10 masked rows per sector on average (needs proof)
- only bad rows recorded, others are considered good by default
- ROWS: std::vector<int row_id> => BINARY OBJ / BLOB + length => serialized list like "<id1>,<id2>..<idN>" => "124,532,5556"
- row_id => 928*<sensor_id> + k
- insert into std::map<int row_id, bool flag> after deserialization
- COLS: std::vector<int col_id> => BINARY OBJ / BLOB + length => ..same as rows..
- col_id => 960*<sensor_id> + k
- insert into std::map<int col_id, bool flag> after deserialization
- observation:
- seems to be either good or bad (binary flag)
- no "easy'n'simple" way to serialize 357M entries in C++
- 400 sensors, up to 2000 entries each, average is 1.6 channels per sector (???)
- store std::vector<uint pxl_id> as BINARY OBJ / BLOB + length;
- <pxl_id> = <row_id>*<col_id>*<sensor_id> => 357M max
- it is fairly easy to gzip blob before storage, but will hardly help as data is not text..
- alternatively: use ROOT serialization, but this adds overhead, and won't allow non-ROOT readout, thus not recommended;
Note: I investigated source codes for StPxlDbMaker, and found that Rows / Columns are accessed by scanning an array of std::vectors:
STAR DB API v2
STAR DB API v2
This page holds STAR database API v2 progress. Here are major milestones :
- Components Overview (UML)
- Core Components technology choice:
- [done] New version of XML configuration file + XML Schema for verification (.xsd available, see attachment);
- [done] New XML parser library :
- [done] rapidXML (header-only, fast, non-validating parser) - will use this one as a start;
- [not done] xerces-c (huge, validating, slow parser);
- [done] Encryption support for XML configuration :
- [done] XOR-SHIFT-BASE64;
- [done] AES128, AES256;
- [CYPHER-TYPE]-V1 means that [CYPHER-TYPE] was used with parameter set 1 (e.g.: predefined AES key 'ABC');
- [done] Threads support for Load Balancer, Data preload, Cache search
- pthreads - popular, widely used;
- pthreads - popular, widely used;
- [done] Database Abstraction Layer reshape :
- OpenDBX (MySQL, Postresql, Sqlite3, Oracle) - API level abstraction, will require "personalized" sql queries for our system;
- [done] In-memory cache support [requires C++ -> DB -> C++ codec update]:
- memcached (local/global, persistent, with expiration time setting);
- simple hashmap (local - in memory cache, per job, non-persistent);
- [in progress] Persistent cache support :
- hypercache (local, persistent, timestamped, file-based cache);
- Supported Features list
- OFFLINE DB: read-heavy
- ONLINE DB: write-heavy
- AOB
--------------------------------------------------------------------------------------------------------------
New Load Balancer (abstract interface + db-specific modules) :
- dbServers.xml, v1, v2 xml config support;
- db load : number of running threads;
- db load : response time;
- should account for slave lag;
- should allow multiple instances with different tasks and databases (e.g. one for read, another for write);
- should randomize requests if multiple "free" nodes found;
OPEN QUESTIONS
Should we support <databases></databases> tag with new configuration schema?
<StDbServer>
<server> run2003 </server>
<host> onldb.starp.bnl.gov </host>
<port> 3501 </port>
<socket> /tmp/mysql.3501.sock </socket>
<databases> RunLog, Conditions_rts, Scalers_onl, Scalers_rts </databases>
</StDbServer>Hypercache ideas and plans
--- HYPERCACHE ---
Definitions :
1. persistent representation of STAR Offline db on disk;
2. "database on demand" feature;
Each STAR Offline DB request is :
- fetched from original db server by timestamp (or run number);
- stored on disk in some format for later use;
- subsequent requests check disk cache first, try db next, eventually building local db cache accessible by db name/table + timestamp;
3. data on disk is to be partitioned by :
a) "db path" AND ("validity time" OR "run number");
POSSIBLE IMPLEMENTATIONS:
a) local sqlite3 database + data blobs as separate files, SINGLE index file like "/tmp/STAR/offline.sqlite3.cache" for ALL requests;
b) local sqlite3 database + data blobs as separate files, MULTIPLE index files, one per request path. Say, request is "bemc/mapping/2003/emcPed", therefore, we will have "/tmp/STAR/sha1(request_path).sqlite3.cache" file for all data entries;
c) local embedded MySQL server (possibly, standalone app) + data blobs as separate files;
d) other in-house developed solution;
-----------------------------------------------------------------------------------------------------------------------------
SQLITE 3 database table format : [char sha1( path_within_subsystem ) ] [timestamp: beginTime] [timestamp: endTime] [seconds: expire] [char: flavor]
SQLITE 3 table file : /tmp/STAR_OFFLINE_DB/ sha1 ( [POOL] / [DOMAIN] / [SUBSYSTEM] ) / index.cache
SQLITE 3 blob is located at : /tmp/STAR_OFFLINE_DB/ sha1 ( [POOL] / [DOMAIN] / [SUBSYSTEM] ) / [SEGMENT] / sha1( [path_within_subsystem][beginTime][endTime] ).blob.cache
[SEGMENT] = int [0]...[N], for faster filesystem access
database access abstraction libraries overview
| Name | Backends | C/C++ | Linux/Mac version | Multithreading lib/drivers | RPM available | Performance | Licence |
| OpenDBX | Oracle,MySQL, PostgreSQL, Sqlite3 + more | yes/yes | yes/yes | yes/yes | yes/authors | fast, close to native drivers | LGPL |
| libDBI | MySQL, PostgreSQL, Sqlite3 | yes/external | yes/yes | yes/some | yes/Fedora | fast, close to native drivers | LGPL/GPL |
| SOCI | Oracle,MySQL, PostgreSQL | no/yes | yes/yes | no/partial | yes/Fedora | average to slow | Boost |
| unixODBC | ALL known RDBMS | yes/external | yes/yes | yes/yes | yes/RHEL | slow | LGPL |
While other alternatives exist ( e.g. OTL,QT/QSql ), I'd like to keep abstraction layer as thin as possible, so my choice is OpenDBX. It supports all databases we plan to use in a mid-term (MySQL, Oracle, PostreSQL, Sqlite3) and provides both C and C++ APIs in a single package with minimal dependencies on other packages.
STAR Online Services Aggregator
STAR Online Services Aggregator
STAR @ RHIC v0.4.0
1. DESCRIPTION
STAR @ RHIC is cross-platform application, available for Web, Android, WinPhone, Windows, Mac and Linux operating systems, which provides a convenient aggregated access to various STAR Online tools, publicly available at STAR collaboration website(s).
STAR @ RHIC is the HTML5 app, packaged for Android platform using Crosswalk, a HTML application runtime, optimized for performance (ARM+x86 packages, ~50 MB installed). Crosswalk project was founded by Intel's Open Source Technology Center. Alternative packaging (Android universal, ~5 MB, WinPhone ~5 MB) is done via PhoneGap build service, which is not hardware-dependent, as it does not package any html engine, but it could be affected by system updates. Desktop OS packaging is done using NodeWebKit (NW.js) software.
Security: This application requires STAR protected password to function (asks user at start). All data transmissions are protected by Secure Socket Layer (SSL) encryption.
Source code is included within packages, and is also available at CVS location
Try web version using this link.
2. DOWNLOADS
2.1 Smartphones, Tablets
All packages are using self-signed certificates, so users will have to allow such packages explicitly at OS level otherwise they will not be installed. All app versions require just two permissions: network discovery and network access.- ANDROID app, optimized for ARM processors
- ANDROID app, optimized for x86 processors
- ANDROID app, universal, non-optimized
- WINPHONE app, universal
Note: sorry iOS users (iPhone, iPad) - Apple is very restrictive and does not allow to package or install applications using self-signed certificates. While there is a technical possibility to make iOS package of the application, it will cost ~$100/year to buy iOS developer access which includes certificate.
2.2 Desktop OS
Note: linux packages require fresh glibc library, and therefore are compable with RedHat 7 / Scientific 7 or latest Ubuntu distributions. Redhat 5/6 is NOT supported.STAR Online Status Viewer
STAR ONLINE Status Viewer
Location: development version of this viewer is located here : http://online.star.bnl.gov/dbPlots/
Rationale: STAR has many standalone scripts written to show online status of some specific subsystem during Run time. Usually, plots or histograms are created using either data from Online Database, or Slow Controls Archive or CDEV inteface. Almost every subsystem expert writes her own script, because no unified API/approach is available at the moment. I decided to provide generic plots for various subsystems data, recorded in online db by online collector daemons + some data fetched directly from SC Archive. SC Archive is used because STAR online database contains primarily subsystem-specific data like voltages, and completely ignores basic parameters like hall temperature and humidity (not required for calibrations). There is no intention to provide highly specialized routines for end-users (thus replacing existing tools like SPIN monitor), only basic display of collected values is presented.
Implementation:
- online.star.bnl.gov/dbPlots/ scripts use single configuration file to fetch data from online db slave, thus creating no load on primary online db;
- to reduce CPU load, gnuplot binary is used instead of php script to process data fetched from database and draw plots. This reduces overall CPU usage by x10 factor to only 2-3% of CPU per gnuplot call (negligible).
- Slow Controls data is processed in this way: a) cron-based script, located at onldb2(slave) is polling SC Archive every 5 minutes and writes data logs in a [timestamp] [value] format; b) gnuplot is called to process those files; c) images are shipped to dean.star.bnl.gov via NFS exported directory;
Maintenance: resulting tool is really easy to maintain, since it has only one config file for database, and only one config file for graphs information - setup time for a new Run is about 10 minutes. In addition, it is written in a forward-compatible way, so php version upgrade should not affect this viever.
Browser compatibility: Firefox, Konqueror, Safari, IE7+, Google Chrome are compatible. Most likely, old netscape should work fine too.
STAR database inrastructure improvements proposal
STAR database improvements proposal
D. Arhipkin
1. Monitoring strategy
Proposed database monitoring strategy suggests simultaneous host (hardware), OS and database monitoring to be able to prevent db problems early. Database service health and response time depends strongly on underlying OS health and hardware, therefore, solution, covering all aforementioned aspects needs to be implemented. While there are many tools available on a market today, I propose to use Nagios host and service monitoring tool.
Nagios is a powerful monitoring tool, designed to inform system administrators of the problems before end-users do. The monitoring daemon runs intermittent checks on hosts and services you specify using external "plugins" which return status information to Nagios. When problems are encountered, the daemon can send notifications out to administrative contacts in a variety of different ways (email, instant message, SMS, etc.). Current status information, historical logs, and reports can all be accessed via web browser.
Nagios is already in use at RCF. Combined the Nagios server ability to work in a slave mode, this will allow STAR to integrate into BNL ITD infrastructure smoothly.
Some of the Nagios features include:
Monitoring of network services (SMTP, POP3, HTTP, NNTP, PING, etc.)
Monitoring of host resources (processor load, disk and memory usage, running processes, log files, etc.)
Monitoring of environmental factors such as temperature
Simple plugin design that allows users to easily develop their own host and service checks
Ability to define network host hierarchy, allowing detection of and distinction between hosts that are down and those that are unreachable
Contact notifications when service or host problems occur and get resolved (via email, pager, or other user-defined method)
Optional escalation of host and service notifications to different contact groups
Ability to define event handlers to be run during service or host events for proactive problem resolution
Support for implementing redundant and distributed monitoring servers
External command interface that allows on-the-fly modifications to be made to the monitoring and notification behavior through the use of event handlers, the web interface, and third-party applications
Retention of host and service status across program restarts
Scheduled downtime for suppressing host and service notifications during periods of planned outages
Ability to acknowledge problems via the web interface
Web interface for viewing current network status, notification and problem history, log file, etc.
Simple authorization scheme that allows you restrict what users can see and do from the web interface
2. Backup strategy
There is an obvious need for unified, flexible and robust database backup system for STAR databases array. Databases are a part of growing STAR software infrastructure, and new backup system should be easy to manage and scalable enough to perform well under such circumstances
Zmanda Recovery Manager (MySQL ZRM, Community Edition) is suggested to be used, as it would be fully automated, reliable, uniform database backup and recovery method across all nodes. It also has an ability to restore from backup by tools included with standard MySQL package (for convenience). ZRM CE is a freely downloadable version of ZRM for MySQL, covered by GPL license.
ZRM allows to:
Schedule full and incremental logical or raw backups of your MySQL database
Centralized backup management
Perform backup that is the best match for your storage engine and your MySQL configuration
Get e-mail notification about status of your backups
Monitor and obtain reports about your backups (including RSS feeds)
Verify your backup images
Compress and encrypt your backup images
Implement Site or Application specific backup policies
Recover database easily to any point in time or to any particular database event
Custom plugins to tailor MySQL backups to your environment
ZRM CE is dedicated to use with MySQL only.
3. Standards compliance
OS compliance. Scientific Linux distributions comply to the Filesystem Hierarchy Standard (FHS), which consists of a set of requirements and guidelines for file and directory placement under UNIX-like operating systems. The guidelines are intended to support interoperability of applications, system administration tools, development tools, and scripts as well as greater uniformity of documentation for these systems. All MySQL databases used in STAR should be configured according to underlying OS standards like FHS to ensure effective OS and database administration during the db lifetime.
MySQL configuration recommendations. STAR MySQL servers should be configured in compliance to both MySQL for linux recommendations and MySQL server requirements. All configuration files should be complete (no parameters should be required from outer sources), and contain supplementary information about server primary purpose and dependent services (like database replication slaves).
References
http://www.zmanda.com/backup-mysql.html
http://proton.pathname.com/fhs/
Solid State Drives (SSD) vs. Serial Attached SCSI (SAS) vs. Dynamic Random Access Memory (DRAM)
INTRODUCTION
This page will provide summary of SSD vs SAS vs DRAM testing using SysBench tool. Results are grouped like this :
- FS IO performance tests;
- Simulated/artificial MySQL load tests;
- STAR Offline API load tests;
Filesystem IO results are important to understand several key aspects, like :
- system response to parallel multi-client access (read,write,mixed);
- cost estimation: $/IOP/s and $/MB of storage;
Simulated MySQL load test is critical to understand strengths and weaknesses of MySQL itself, deployed on a different types of storage. This test should provide baseline for real data (STAR Offline DB) performance measurements and tuning - MySQL settings could be different for SAS and SSD.
Finally, STAR Offline API load tests should represent real system behavior using SAS and SSD storage, and provide an estimate of the potential benefits of moving to SSD in our case of ~1000 parallel clients per second per db node (we have dozen of Offline DB nodes at the moment).
While we do not expect DRAM to become our primary storage component, these tests will allow to estimate the benefit of partial migration of our most-intensively used tables to volatile but fast storage.
Basic results of filesystem IO testing :
- Serial Attached SCSI drive testing results taken with default CFQ scheduler and noatime mount option;
- Solid State Drive testing results taken with default CFQ scheduler and noatime mount option;
- Dynamic Random Access Memory testing results
Summary :
- DATABASE INDEX SEARCH or SPARSE DATA READ: SSD performs ~50 times better than SAS HDD in short random reads (64 threads, 4kb blocks, random read) : 24000 IOP/s vs 500 IOP/s
- SEQUENTIAL TABLE SCAN: SSD performs ~2 times better than SAS HDD in flat sequential reads (64 threads, 256kb blocks, sequential read) : 200 MB/s vs 90 MB/s
- DATABASE INSERT SPEED: SSD performs ~10 times better than SAS HDD in short random writes (64 threads, 4kb blocks, random write) : 6800 IOP/s vs 750 IOP/s
Simulated MySQL Load testing :
- Simulated DB Load : SAS
- Simulated DB Load : SSD
- Simulated DB Load : DRAM
- Simulated DB Load : DRAM vs SSD vs SAS
Summary : quite surprising results were uncovered.
- READONLY Operations : *ALL* Drives show roughly identical performance! Does it mean that MySQL treats all drives as SAS by default (Query Optimizer), or synthetic test is not quite great for benchmarking? Real data testing to follow...
- Mixed READ/WRITE Operations: SSD and DRAM results are practically identical, and SAS is x2 slower than SSD/DRAM!
STAR Offline DB testing :
TBD
Summary :
CONCLUSIONS:
TBD
Dynamic Random Access Memory testing results
SysBench results for tmpfs using 6 GB of DRAM
[ SAMSUNG DDR3-1333 MHz (0.8 ns) DIMM, part number : M393B5673DZ1-CH9 ]



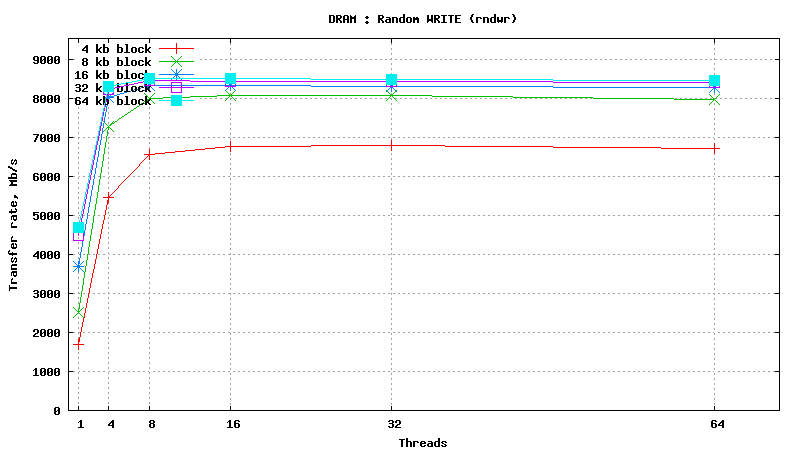


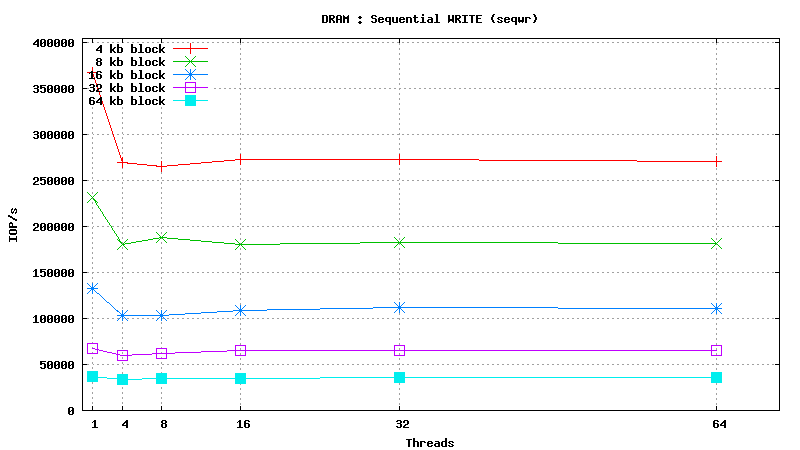
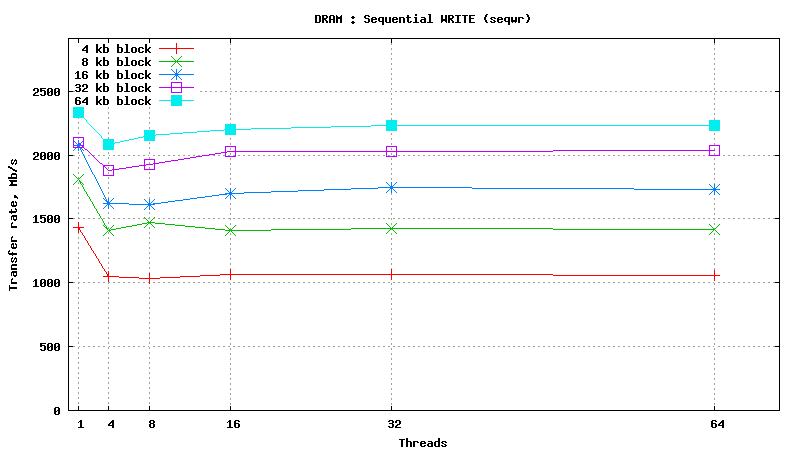
Serial Attached SCSI drive testing results
SysBench results for Fujitsu MBC2073RC
(size: 72 GB; 15,000 RPM; SAS; 16 MB buffer; cost is ~160$ per unit)

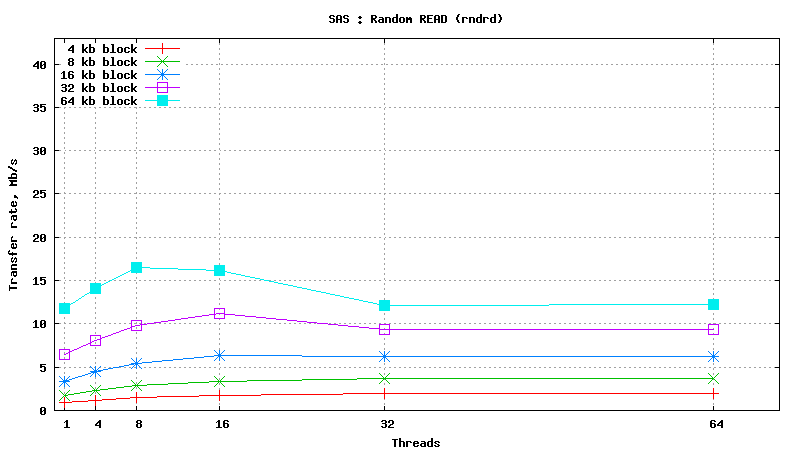
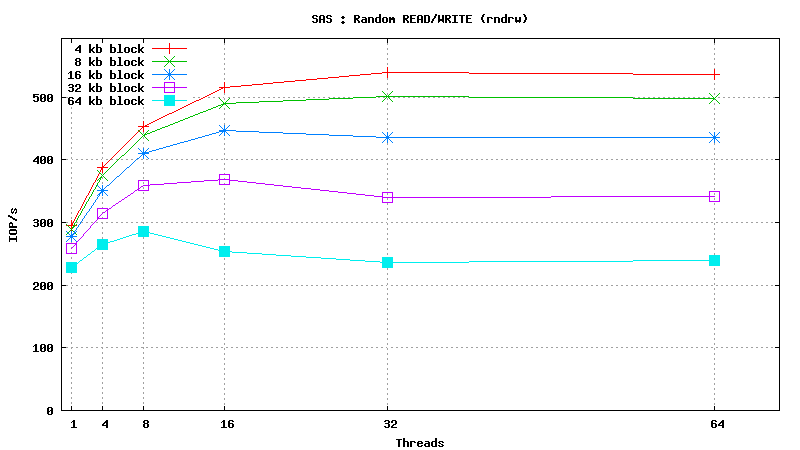




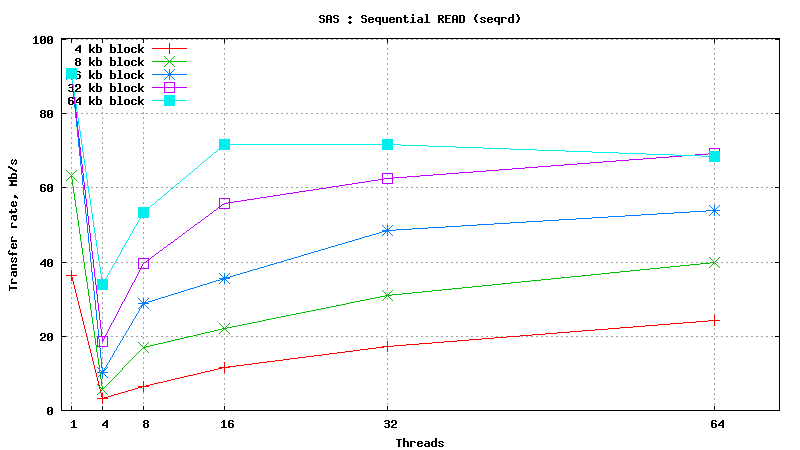


Simulated DB Load : DRAM
Simulated DB Load Testing Results : DRAM
SysBench parameters: table with 20M rows, readonly. No RAM limit, /dev/shm was used as MySQL data files location.
READ only operations

![]()
READ/WRITE operations

![]()
Same plots, focus on 1-128 threads
READ only operations
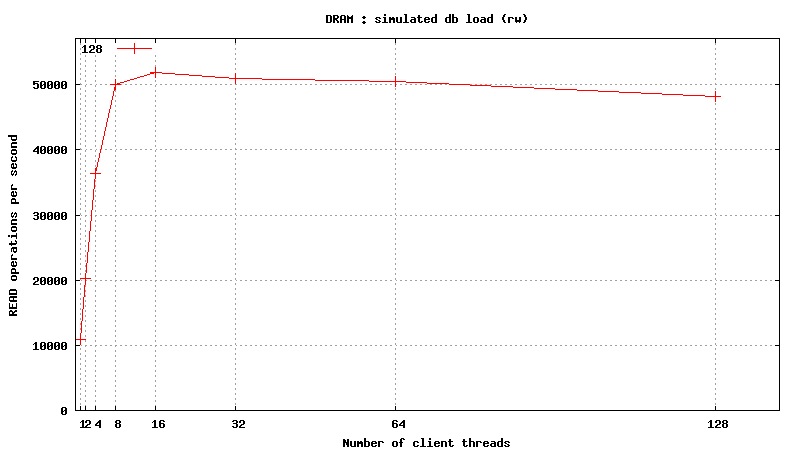
![]()
READ/WRITE operations

![]()
Simulated DB Load : DRAM vs SSD vs SAS
Simulated DB Load : DRAM vs SSD vs SAS
READ only operations
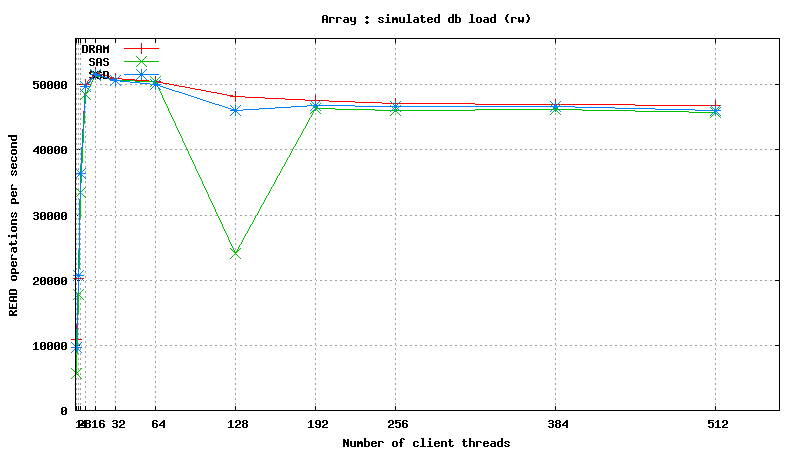
![]()
READ/WRITE operations

![]()
Simulated DB Load : SAS
Simulated DB Load : Serial Attached SCSI
SysBench parameters: table with 20M rows, readonly. Allowed RAM limit: 2Gb to reduce fs caching effects.
READ only operations

![]() <h1 class="rtecenter">Simulated DB Load : Solid State Disk</h1>
<h1 class="rtecenter">Simulated DB Load : Solid State Disk</h1>
READ/WRITE operations
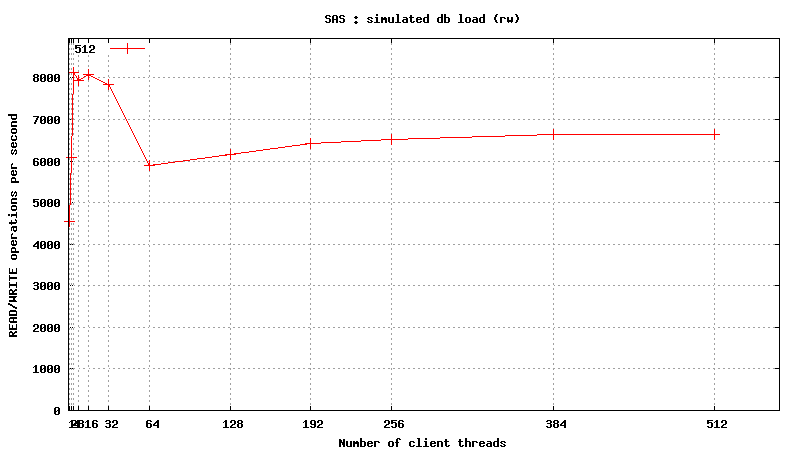
![]()
Same plots, focus on 1-128 threads
READ only operations

![]()
READ/WRITE operations
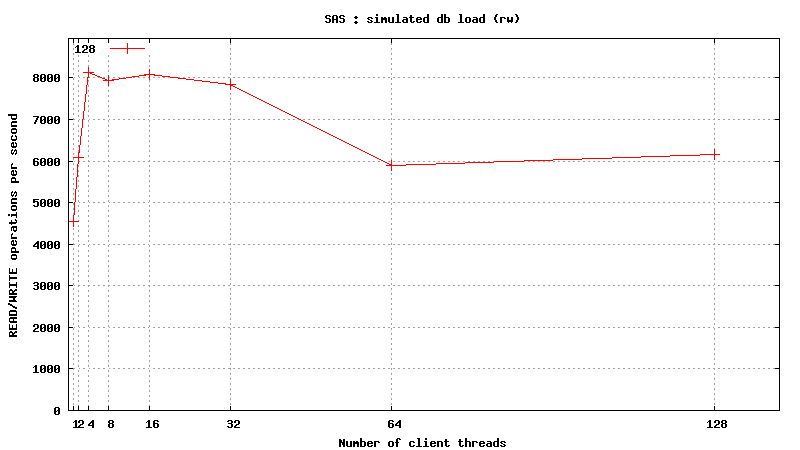
![]()
Simulated DB Load : SSD
Simulated DB Load : Solid State Disk
SysBench parameters: table with 20M rows, readonly. Allowed RAM limit: 2Gb to reduce fs caching effects.
READ only operations

![]()
READ/WRITE operations

![]()
Same plots, focus on 1-128 threads
READ only operations

![]()
READ/WRITE operations

![]()
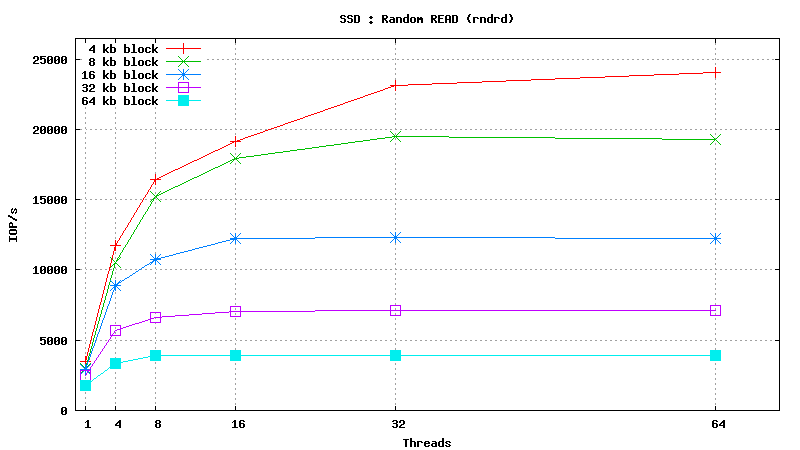


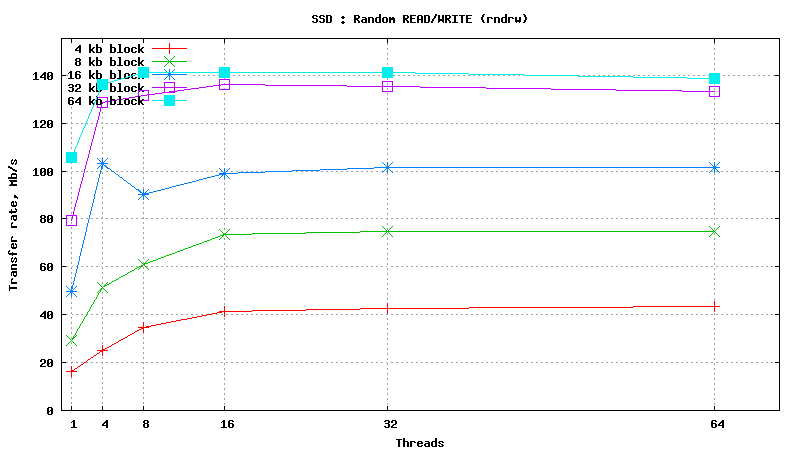


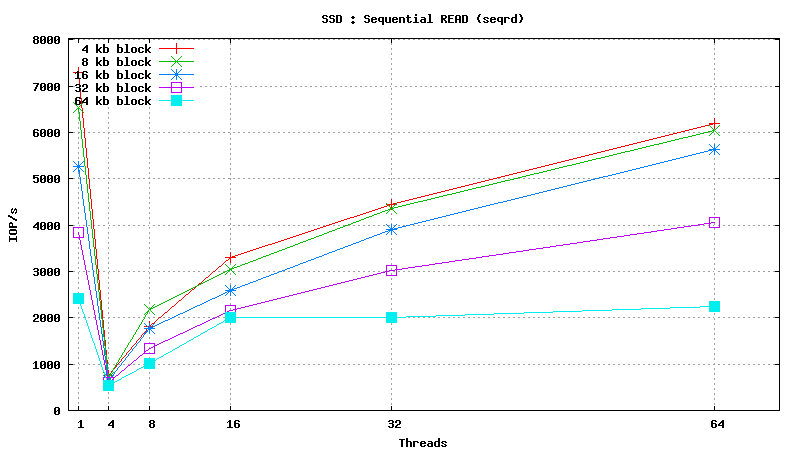


.png)
{kind=link}
{kind=link}
{kind=link}
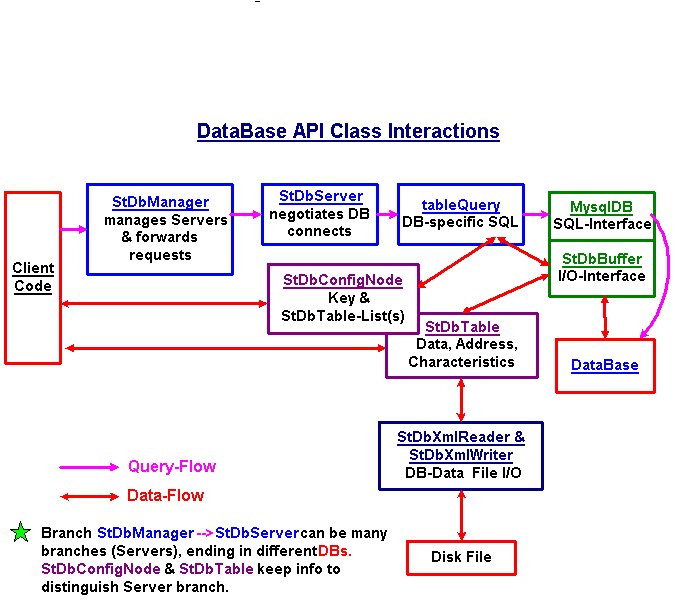{kind=link}
Test
Test page